
Understanding how to use the robots.txt file is crucial for any website’s SEO strategy. Mistakes in this file can impact how your website is crawled and your pages’ search appearance. Getting it right, on the other hand, can improve crawling efficiency and mitigate crawling issues.
Google recently reminded website owners about the importance of using robots.txt to block unnecessary URLs.
Those include add-to-cart, login, or checkout pages. But the question is – how do you use it properly?
In this article, we will guide you into every nuance of how to do just so.
What Is Robots.txt?
The robots.txt is a simple text file that sits in the root directory of your site and tells crawlers what should be crawled.
The table below provides a quick reference to the key robots.txt directives.
| Directive | Description |
| User-agent | Specifies which crawler the rules apply to. See user agent tokens. Using * targets all crawlers. |
| Disallow | Prevents specified URLs from being crawled. |
| Allow | Allows specific URLs to be crawled, even if a parent directory is disallowed. |
| Sitemap | Indicates the location of your XML Sitemap by helping search engines to discover it. |
This is an example of robot.txt from ikea.com with multiple rules.
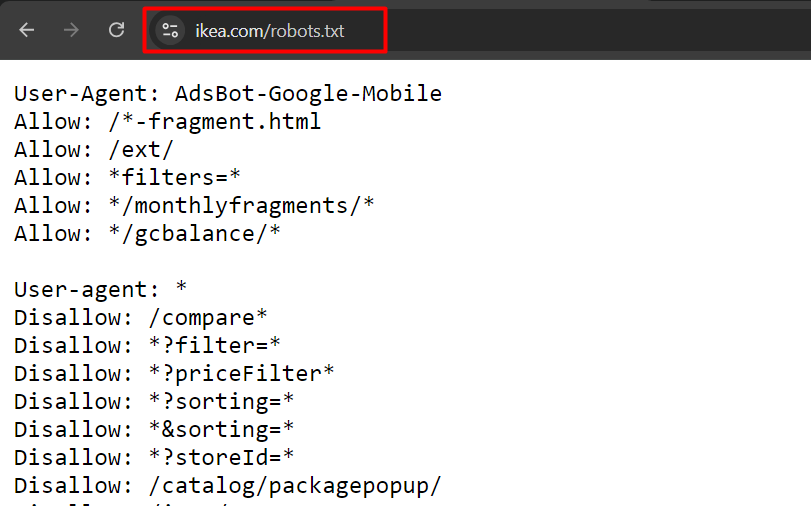 Example of robots.txt from ikea.com
Example of robots.txt from ikea.comNote that robots.txt doesn’t support full regular expressions and only has two wildcards:
- Asterisks (*), which matches 0 or more sequences of characters.
- Dollar sign ($), which matches the end of a URL.
Also, note that its rules are case-sensitive, e.g., “filter=” isn’t equal to “Filter=.”
Order Of Precedence In Robots.txt
When setting up a robots.txt file, it’s important to know the order in which search engines decide which rules to apply in case of conflicting rules.
They follow these two key rules:
1. Most Specific Rule
The rule that matches more characters in the URL will be applied. For example:
User-agent: *
Disallow: /downloads/
Allow: /downloads/free/In this case, the “Allow: /downloads/free/” rule is more specific than “Disallow: /downloads/” because it targets a subdirectory.
Google will allow crawling of subfolder “/downloads/free/” but block everything else under “/downloads/.”
2. Least Restrictive Rule
When multiple rules are equally specific, for example:
User-agent: *
Disallow: /downloads/
Allow: /downloads/Google will choose the least restrictive one. This means Google will allow access to /downloads/.
Why Is Robots.txt Important In SEO?
Blocking unimportant pages with robots.txt helps Googlebot focus its crawl budget on valuable parts of the website and on crawling new pages. It also helps search engines save computing power, contributing to better sustainability.
Imagine you have an online store with hundreds of thousands of pages. There are sections of websites like filtered pages that may have an infinite number of versions.
Those pages don’t have unique value, essentially contain duplicate content, and may create infinite crawl space, thus wasting your server and Googlebot’s resources.
That is where robots.txt comes in, preventing search engine bots from crawling those pages.
If you don’t do that, Google may try to crawl an infinite number of URLs with different (even non-existent) search parameter values, causing spikes and a waste of crawl budget.
When To Use Robots.txt
As a general rule, you should always ask why certain pages exist, and whether they have anything worth for search engines to crawl and index.
If we come from this principle, certainly, we should always block:
- URLs that contain query parameters such as:
- Internal search.
- Faceted navigation URLs created by filtering or sorting options if they are not part of URL structure and SEO strategy.
- Action URLs like add to wishlist or add to cart.
- Private parts of the website, like login pages.
- JavaScript files not relevant to website content or rendering, such as tracking scripts.
- Blocking scrapers and AI chatbots to prevent them from using your content for their training purposes.
Let’s dive into how you can use robots.txt for each case.
1. Block Internal Search Pages
The most common and absolutely necessary step is to block internal search URLs from being crawled by Google and other search engines, as almost every website has an internal search functionality.
On WordPress websites, it is usually an “s” parameter, and the URL looks like this:
https://www.example.com/?s=googleGary Illyes from Google has repeatedly warned to block “action” URLs as they can cause Googlebot to crawl them indefinitely even non-existent URLs with different combinations.
Here is the rule you can use in your robots.txt to block such URLs from being crawled:
User-agent: *
Disallow: *s=*- The User-agent: * line specifies that the rule applies to all web crawlers, including Googlebot, Bingbot, etc.
- The Disallow: *s=* line tells all crawlers not to crawl any URLs that contain the query parameter “s=.” The wildcard “*” means it can match any sequence of characters before or after “s= .” However, it will not match URLs with uppercase “S” like “/?S=” since it is case-sensitive.
Here is an example of a website that managed to drastically reduce the crawling of non-existent internal search URLs after blocking them via robots.txt.
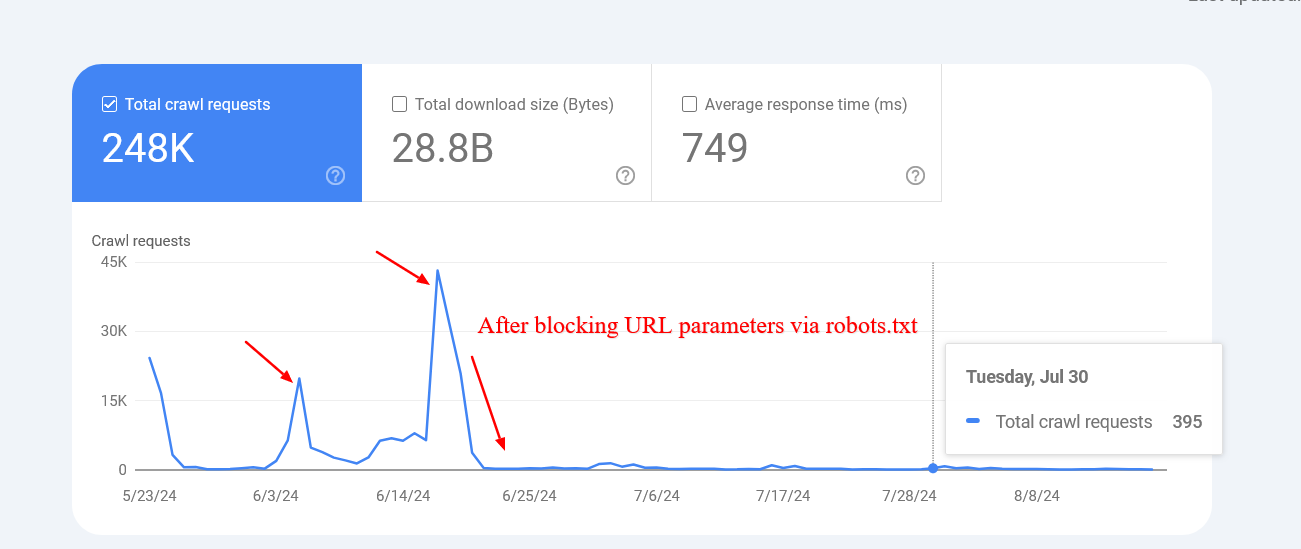 Screenshot from crawl stats report
Screenshot from crawl stats reportNote that Google may index those blocked pages, but you don’t need to worry about them as they will be dropped over time.
2. Block Faceted Navigation URLs
Faceted navigation is an integral part of every ecommerce website. There can be cases where faceted navigation is part of an SEO strategy and aimed at ranking for general product searches.
For example, Zalando uses faceted navigation URLs for color options to rank for general product keywords like “gray t-shirt.”
However, in most cases, this is not the case, and filter parameters are used merely for filtering products, creating dozens of pages with duplicate content.
Technically, those parameters are not different from internal search parameters with one difference as there may be multiple parameters. You need to make sure you disallow all of them.
For example, if you have filters with the following parameters “sortby,” “color,” and “price,” you may use this set of rules:
User-agent: *
Disallow: *sortby=*
Disallow: *color=*
Disallow: *price=*Based on your specific case, there may be more parameters, and you may need to add all of them.
What About UTM Parameters?
UTM parameters are used for tracking purposes.
As John Mueller stated in his Reddit post, you don’t need to worry about URL parameters that link to your pages externally.
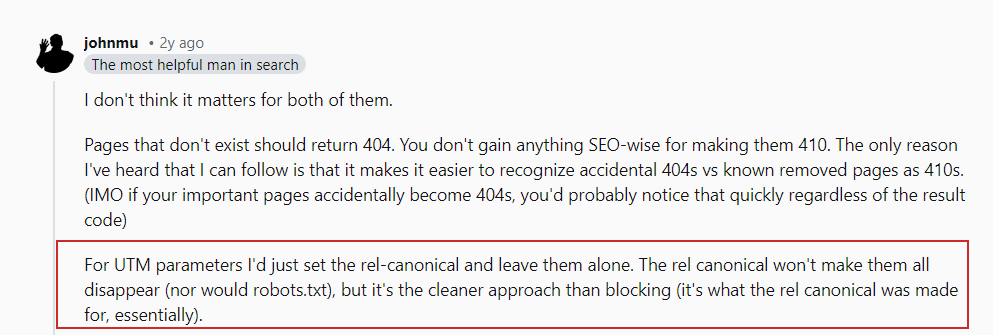 John Mueller on UTM parameters
John Mueller on UTM parametersJust make sure to block any random parameters you use internally and avoid linking internally to those pages, e.g., linking from your article pages to your search page with a search query page “https://www.example.com/?s=google.”
3. Block PDF URLs
Let’s say you have a lot of PDF documents, such as product guides, brochures, or downloadable papers, and you don’t want them crawled.
Here is a simple robots.txt rule that will block search engine bots from accessing those documents:
User-agent: *
Disallow: /*.pdf$The “Disallow: /*.pdf$” line tells crawlers not to crawl any URLs that end with .pdf.
By using /*, the rule matches any path on the website. As a result, any URL ending with .pdf will be blocked from crawling.
If you have a WordPress website and want to disallow PDFs from the uploads directory where you upload them via the CMS, you can use the following rule:
User-agent: *
Disallow: /wp-content/uploads/*.pdf$
Allow: /wp-content/uploads/2024/09/allowed-document.pdf$You can see that we have conflicting rules here.
In case of conflicting rules, the more specific one takes priority, which means the last line ensures that only the specific file located in folder “wp-content/uploads/2024/09/allowed-document.pdf” is allowed to be crawled.
4. Block A Directory
Let’s say you have an API endpoint where you submit your data from the form. It is likely your form has an action attribute like action=”/form/submissions/.”
The issue is that Google will try to crawl that URL, /form/submissions/, which you likely don’t want. You can block these URLs from being crawled with this rule:
User-agent: *
Disallow: /form/By specifying a directory in the Disallow rule, you are telling the crawlers to avoid crawling all pages under that directory, and you don’t need to use the (*) wildcard anymore, like “/form/*.”
Note that you must always specify relative paths and never absolute URLs, like “https://www.example.com/form/” for Disallow and Allow directives.
Be cautious to avoid malformed rules. For example, using /form without a trailing slash will also match a page /form-design-examples/, which may be a page on your blog that you want to index.
Read: 8 Common Robots.txt Issues And How To Fix Them
5. Block User Account URLs
If you have an ecommerce website, you likely have directories that start with “/myaccount/,” such as “/myaccount/orders/” or “/myaccount/profile/.”
With the top page “/myaccount/” being a sign-in page that you want to be indexed and found by users in search, you may want to disallow the subpages from being crawled by Googlebot.
You can use the Disallow rule in combination with the Allow rule to block everything under the “/myaccount/” directory (except the /myaccount/ page).
User-agent: *
Disallow: /myaccount/
Allow: /myaccount/$
And again, since Google uses the most specific rule, it will disallow everything under the /myaccount/ directory but allow only the /myaccount/ page to be crawled.
Here’s another use case of combining the Disallow and Allow rules: in case you have your search under the /search/ directory and want it to be found and indexed but block actual search URLs:
User-agent: *
Disallow: /search/
Allow: /search/$
6. Block Non-Render Related JavaScript Files
Every website uses JavaScript, and many of these scripts are not related to the rendering of content, such as tracking scripts or those used for loading AdSense.
Googlebot can crawl and render a website’s content without these scripts. Therefore, blocking them is safe and recommended, as it saves requests and resources to fetch and parse them.
Below is a sample line that is disallowing sample JavaScript, which contains tracking pixels.
User-agent: *
Disallow: /assets/js/pixels.js7. Block AI Chatbots And Scrapers
Many publishers are concerned that their content is being unfairly used to train AI ****** without their consent, and they wish to prevent this.
#ai chatbots
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: Claude-Web
User-agent: ClaudeBot
User-agent: anthropic-ai
User-agent: cohere-ai
User-agent: Bytespider
User-agent: Google-Extended
User-Agent: PerplexityBot
User-agent: Applebot-Extended
User-agent: Diffbot
User-agent: PerplexityBot
Disallow: /#scrapers
User-agent: Scrapy
User-agent: magpie-crawler
User-agent: CCBot
User-Agent: omgili
User-Agent: omgilibot
User-agent: Node/simplecrawler
Disallow: /Here, each user agent is listed individually, and the rule Disallow: / tells those bots not to crawl any part of the site.
This, besides preventing AI training on your content, can help reduce the load on your server by minimizing unnecessary crawling.
For ideas on which bots to block, you may want to check your server log files to see which crawlers are exhausting your servers, and remember, robots.txt doesn’t prevent unauthorized access.
8. Specify Sitemaps URLs
Including your sitemap URL in the robots.txt file helps search engines easily discover all the important pages on your website. This is done by adding a specific line that points to your sitemap location, and you can specify multiple sitemaps, each on its own line.
Sitemap: https://www.example.com/sitemap/articles.xml
Sitemap: https://www.example.com/sitemap/news.xml
Sitemap: https://www.example.com/sitemap/video.xmlUnlike Allow or Disallow rules, which allow only a relative path, the Sitemap directive requires a full, absolute URL to indicate the location of the sitemap.
Ensure the sitemaps’ URLs are accessible to search engines and have proper syntax to avoid errors.
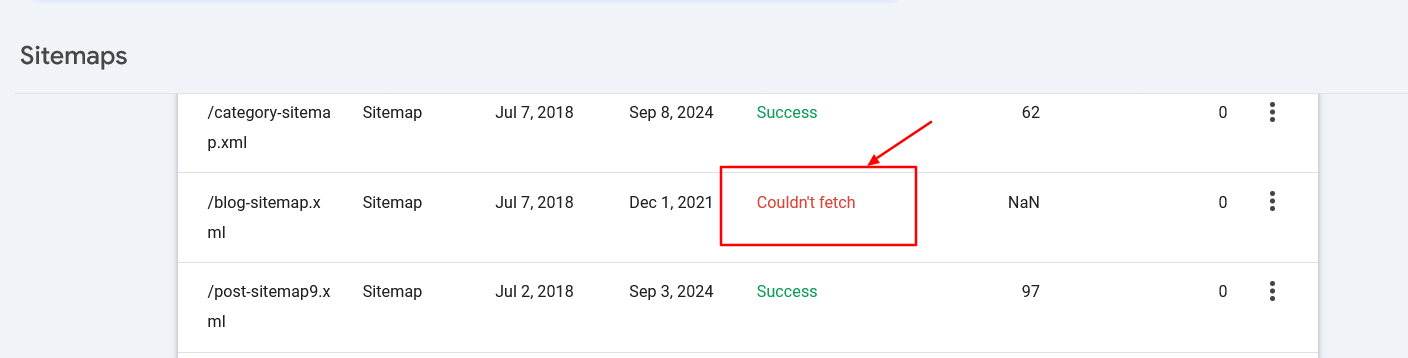 Sitemap fetch error in search console
Sitemap fetch error in search console9. When To Use Crawl-Delay
The crawl-delay directive in robots.txt specifies the number of seconds a bot should wait before crawling the next page. While Googlebot does not recognize the crawl-delay directive, other bots may respect it.
It helps prevent server overload by controlling how frequently bots crawl your site.
For example, if you want ClaudeBot to crawl your content for AI training but want to avoid server overload, you can set a crawl delay to manage the interval between requests.
User-agent: ClaudeBot
Crawl-delay: 60This instructs the ClaudeBot user agent to wait 60 seconds between requests when crawling the website.
Of course, there may be AI bots that don’t respect crawl delay directives. In that case, you may need to use a web firewall to rate limit them.
Troubleshooting Robots.txt
Once you’ve composed your robots.txt, you can use these tools to troubleshoot if the syntax is correct or if you didn’t accidentally block an important URL.
1. Google Search Console Robots.txt Validator
Once you’ve updated your robots.txt, you must check whether it contains any error or accidentally blocks URLs you want to be crawled, such as resources, images, or website sections.
Navigate Settings > robots.txt, and you will find the built-in robots.txt validator. Below is the video of how to fetch and validate your robots.txt.
2. Google Robots.txt Parser
This parser is official Google’s robots.txt parser which is used in Search Console.
It requires advanced skills to install and run on your local computer. But it is highly recommended to take time and do it as instructed on that page because you can validate your changes in the robots.txt file before uploading to your server in line with the official Google parser.
Centralized Robots.txt Management
Each domain and subdomain must have its own robots.txt, as Googlebot doesn’t recognize root domain robots.txt for a subdomain.
It creates challenges when you have a website with a dozen subdomains, as it means you should maintain a bunch of robots.txt files separately.
However, it is possible to host a robots.txt file on a subdomain, such as https://cdn.example.com/robots.txt, and set up a redirect from https://www.example.com/robots.txt to it.
You can do vice versa and host it only under the root domain and redirect from subdomains to the root.
Search engines will treat the redirected file as if it were located on the root domain. This approach allows centralized management of robots.txt rules for both your main domain and subdomains.
It helps make updates and maintenance more efficient. Otherwise, you would need to use a separate robots.txt file for each subdomain.
Conclusion
A properly optimized robots.txt file is crucial for managing a website’s crawl budget. It ensures that search engines like Googlebot spend their time on valuable pages rather than wasting resources on unnecessary ones.
On the other hand, blocking AI bots and scrapers using robots.txt can significantly reduce server load and save computing resources.
Make sure you always validate your changes to avoid unexpected crawability issues.
However, remember that while blocking unimportant resources via robots.txt may help increase crawl efficiency, the main factors affecting crawl budget are high-quality content and page loading speed.
Happy crawling!
More resources:
Featured Image: BestForBest/Shutterstock
Source link : Searchenginejournal.com