
Posted by
Mordy Oberstein
It’s funny what you start seeing when you look at enough Local Packs. Stare at enough of them and you’ll notice some interesting patterns that highlight Google’s emphasis on search location within its local SEO algorithm. What happens however when this pattern is perhaps too prevalent? Is Google over-relying on search location when showing Local Pack results? We’ll take a look at a Local Pack listing pattern that has not been previously discussed and delve into the implications.
Google’s Narrow Local Pack Radius
This study began when I started noticing that the Local Packs I was getting for NYC (New York City) contained results that were predominantly located in Greenwich Village – predominantly. For those unfamiliar with my hometown, Greenwich Village is but one small part of Manhattan Island, that if walked briskly could be traversed in a half hour. It was thus odd that a disproportionate number of the Local Packs I was getting were hyper-focused on that one area of the city.
There were two logical possibilities I considered plausible:
1) Much to the delight of its trendy population, Google considers Greenwich Village to be more authentically “NYC” than any other neighborhood on Manhattan Island.
2) Google tends to show all of its Local Pack results within the same geographic location (i.e., Google clusters its Local Pack results by land area). That is, whether Google uses search location or certain area tendencies (i.e., Wall Street for listings related to stock purchasing), the search engine tends to choose an area and show its listings within the boundaries of it.
To test the viability of these possibilities I started to run more searches that were aimed at other areas of New York City. That is, I ran some queries for businesses that I would not expect to be prolifically popular in the young and hip streets of “The Village” in order to see if Google, in fact, moved the map. I found that queries such as lawyers
With these more diverse Local Pack locations, I started to measure the actual distance between each of the listed businesses, and this is where things started to get interesting. I noticed, that for the most part, the distances between any business shown in the Local Packs I was getting was not exactly “vast” (even in the relative sense, as Manhattan is pretty small as far as American cities go).
How could it be that most of the top businesses for a query were all so close to each other in the vast majority of the Local Packs I was seeing? What’s the mathematical possibility of that? I’ll tell you what it is… 0!
In the end, I ran 22 searches that brought up Local Packs with businesses found on Manhattan Island and despite Manhattan
Let me just put some meat on this:
- It is 3.9 miles between Times Square and Wall Street.
- To get from New York University to the Guggenheim is 4.4 miles.
- Columbus Circle is 3.6 miles away from the Apollo Theatre.
And that’s being generous in “Google’s favor.” Follow me for a moment as I showcase the distance between some lesser-known New York City landmarks and institutions. If I really wanted to show some distance I would have told you that the Brooklyn Bridge is 10.6 miles away from Columbia Presbyterian Medical Center and 13.9 miles from “The Cloisters” up in Inwood. I’m going to stop before this turns into some kind of Billy Joel song.
The point is, 2.6 miles on average between businesses – that’s a pretty darn small radius even for New York City proper (i.e., not including its other boroughs).
Thus, the question is, does Google show me the best local results or the best results near where it thinks I may be (or near a location it so chooses when a search is done from hundreds of miles away, or when the location cannot be determined).
Google’s Distance Preference Inside the Local Pack
Having seen the above data, I was determined to see if this pattern held true across the board. So, I ran an additional 109 “local” queries for another five locations (Baltimore, Boston, Chicago, Houston, and Los Angeles) for a total of 131 city-based queries. Here’s the data:
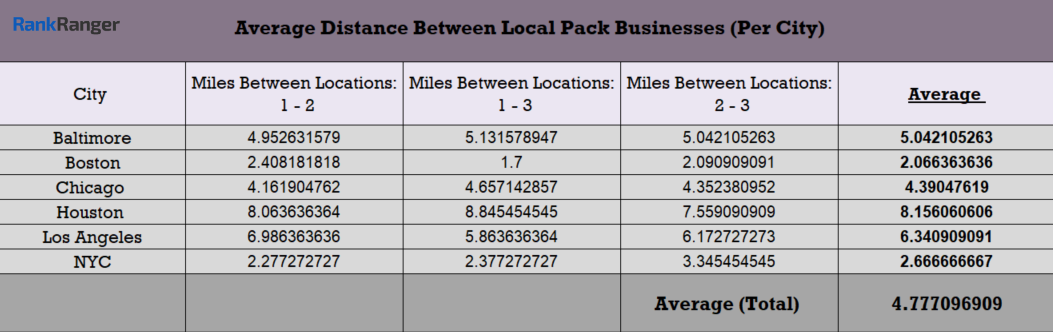
Overall, Google does very much prefer to show locations that are not significantly far from one another within a given Local Pack. Across all six locations and 131 keywords, the average distance between the businesses listed in a Local Pack stands at just under 4.8 miles.
Sure, the average distance fluctuates from city to city. Larger cities (by land area) like Houston and Los Angeles have a greater average distance between Local Pack results than NYC and Boston. However, don’t forget that these cities are significantly larger.
Let me give this data some context by showing you the square miles within each city’s borders:
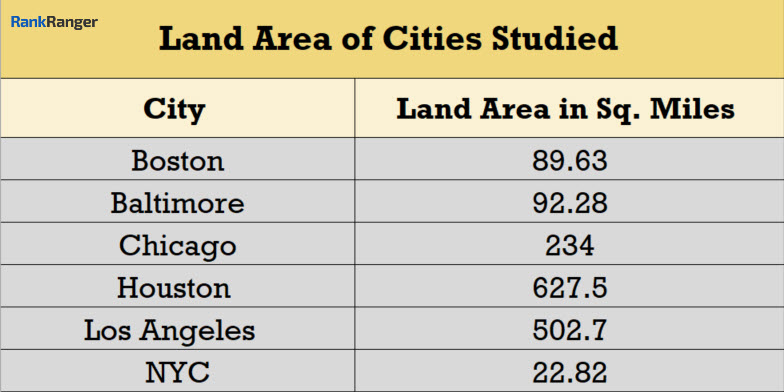
So yes, Houston has an average distance of 8.16 miles between locations whereas NYC has but an average of 2.6 miles. However, while the average distance in Houston is 4X greater than it is in Manhattan, the city is 27X the size of its East Coast counterpart. Thus, Houston’s greater average distance, which is disproportionate to its larger land area, clearly demonstrates what we’ve all known for a long time
Google’s Local Pack ‘Chunking’ Pattern
After spending countless hours looking at 131 Local Packs and the distance between the businesses contained in them, I can not only tell you the best place to get your taxes done in Chicago but that Google has an interesting way of showing you relevant local results.
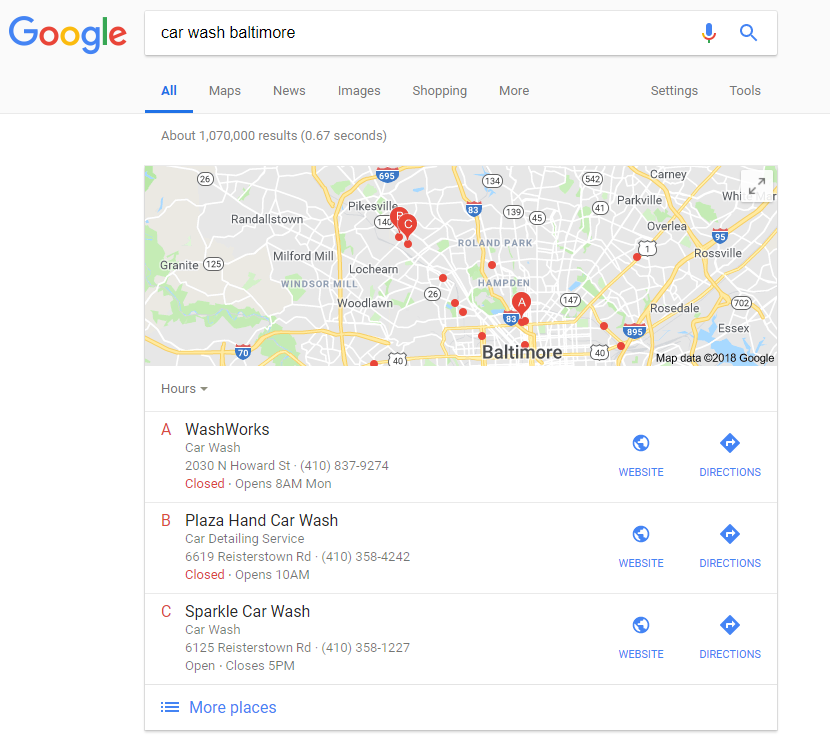
As I began going through more and more Local Packs a clear and self-evident patterned emerged, and for the sake of simplicity I’m calling it the “2:1 pattern.”
What is this 2:1 pattern? Why it’s this:
And this:
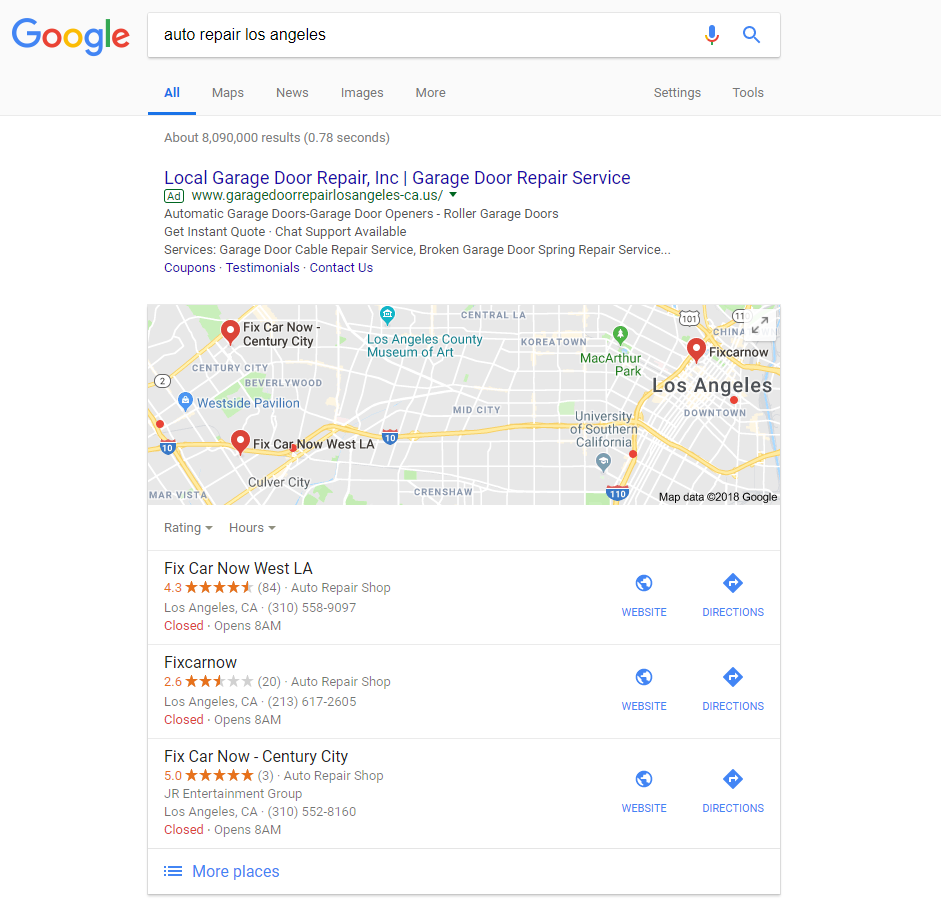
And this:
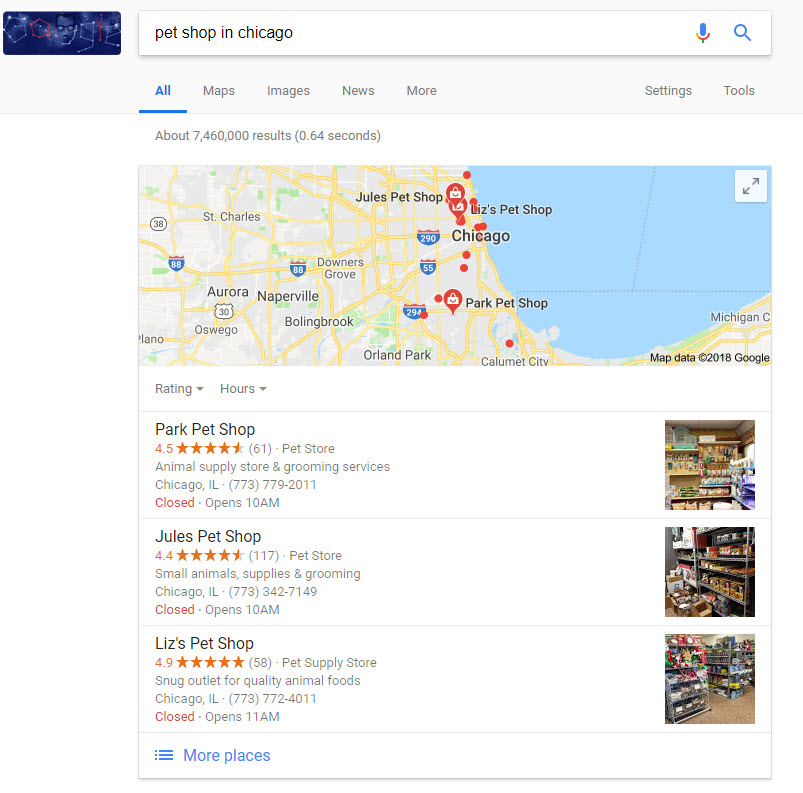
And this:
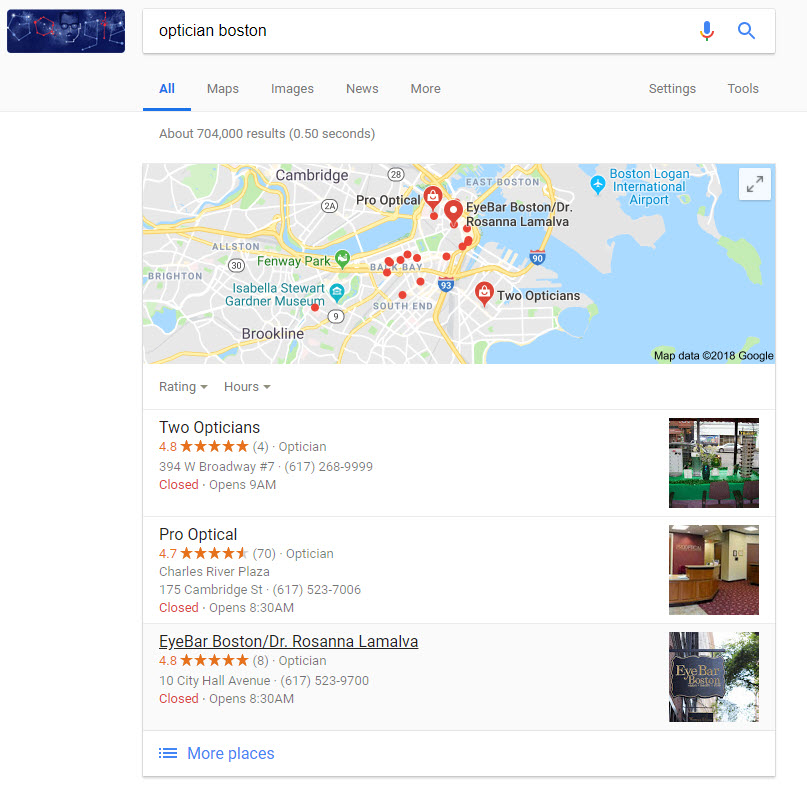
And this:
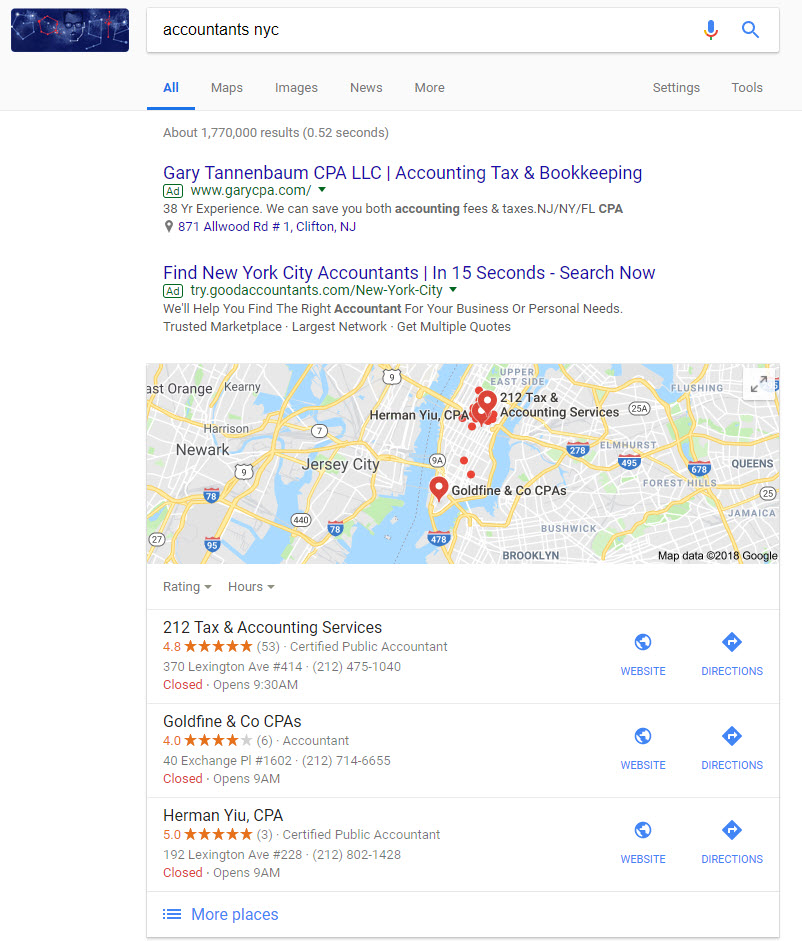
Need I say more? (No! But has that ever stopped me before?)
Why am I calling it a 2:1 pattern… because Google is clustering two of the locations within the Local Pack together and then offering a third, more distant location… or 2:1.
The Catch – What If the Searcher is Nowhere Near?
Rather than this being some sort of existential question, I literally mean, what if the searcher is nowhere near the location they are searching for? Why does that matter you may ask?
Well, the 2:1 pattern makes sense. If Joe’s Sandwiches and Kim’s Cupcakes are the two closest eateries with a decent rating, then it makes sense that Google would show these two listings. This is why you get those two “chunked” listings inside the Local Pack. But what of the third and more distant listing?
When I started seeing this peculiar 2:1 pattern we reached out to local SEO guru Joy Hawkins, who explained that “what Google is doing is showing the user two businesses that are closer to them, but then also pulling in one from further away.” Meaning, Google wants a bit of diversity and adds what is perhaps a more popular, more well-known, or even a better-rated establishment that is a tad further away. Where the search takes place within close proximity to the location indicated in the query, Google is right on target. They’re showing you highly relevant and proximal results while offering you a bit of diversity with that “more distant” listing.
Great, except that when I did these searches I was nowhere near the location. While Google’s 2:1 Local Pack clustering pattern is great for the person trying to get a bite down the street, does it really make sense for a prospective tourist from China who wants to see all that the Big Apple has to offer? Does it make sense for parents trying to find the best treatment for their child that the entire city has to offer?
Is There Such Thing as Too Much Emphasis on Search Location Inside the Local Pack?

As part of the process to sort of pin down what was happening with this “2:1 Local Pack pattern,” I started running queries at the state level. That is, I went to the state level and ran an additional 95 queries. The same queries I ran within the confines of NYC, Baltimore, Boston, Chicago, Houston, and Los Angeles, I also ran for California, Illinois, Maryland, Massachusetts, and Texas. Meaning, I ran a query for clothes store
The idea was to see what happens when you introduce so much diversity in that there are so many major cities for Google to choose from and where the wording of the query itself indicates the intent is not to be confined to a limited area (but rather, results from a large land area are desired). My hunch was that Google does focus in on a specific area at every level. Seeing the 2:1 pattern at the state level would, of course, confirm that. Again, I was nowhere near the locations mentioned in the queries themselves. (Though, for a statewide query, should that even matter?)
This all assumes that the 2:1 pattern presents itself at the state level.
Which it does:
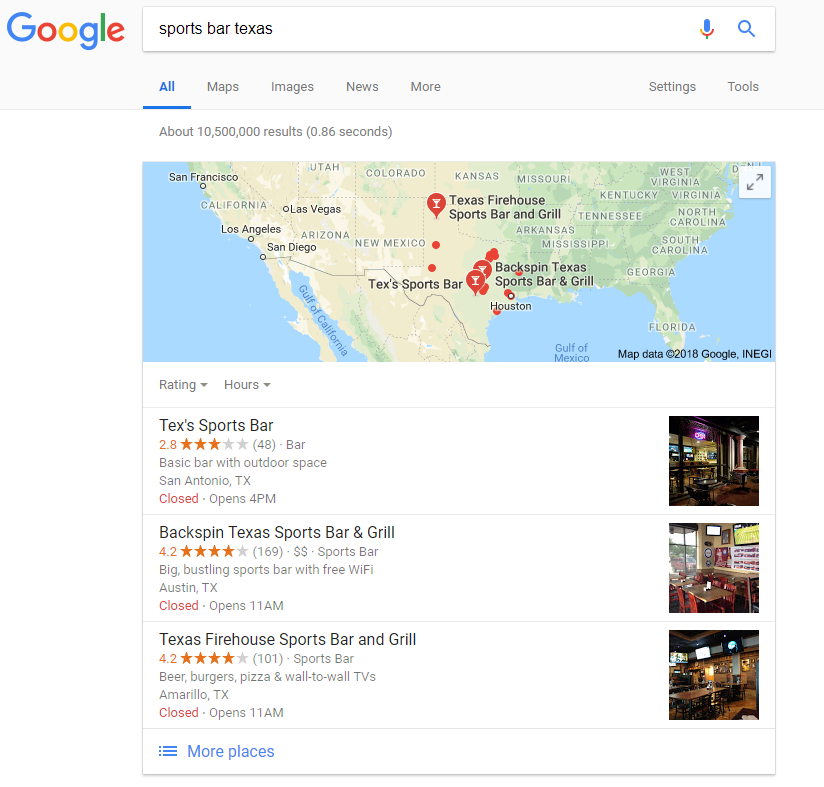
Again:
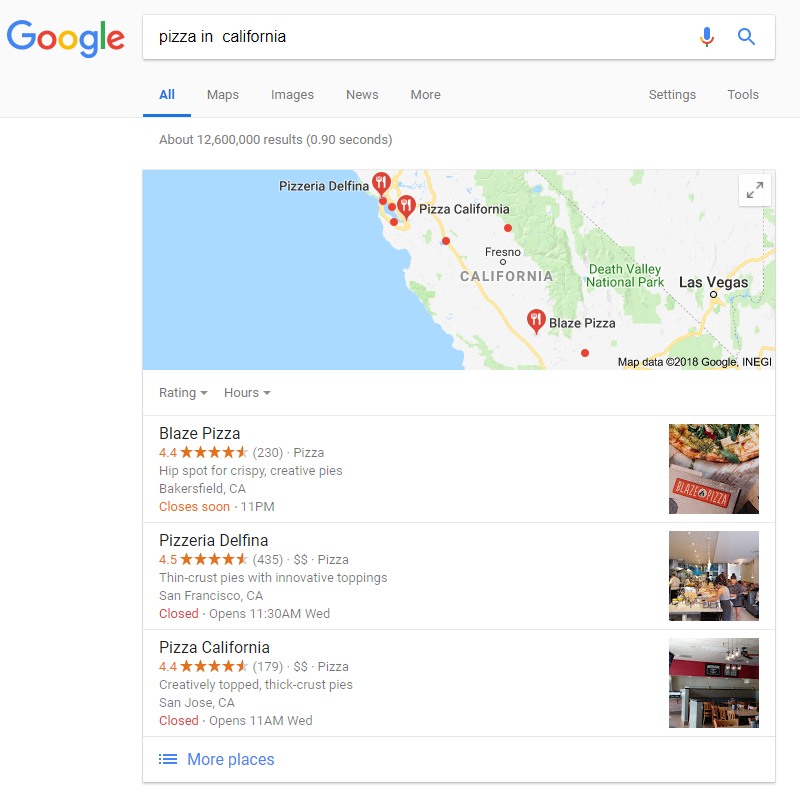
And again:
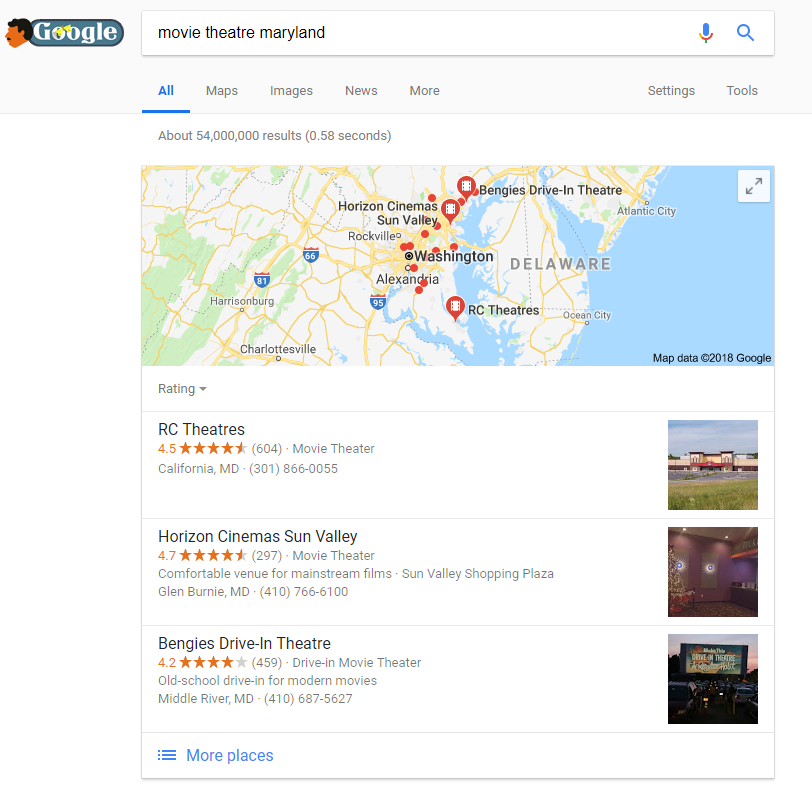
And again:
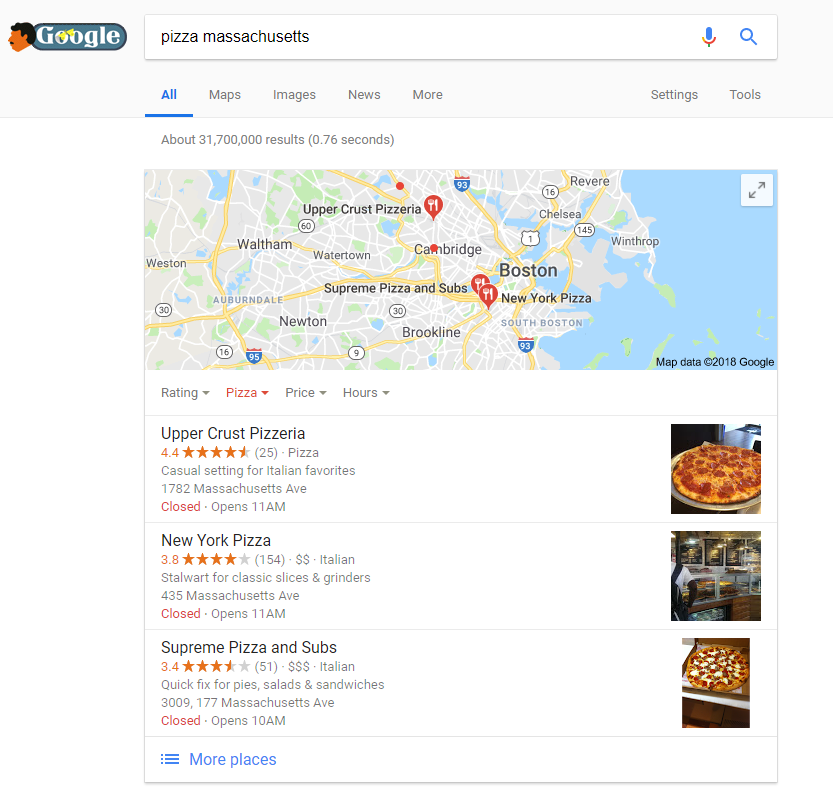
Local Pack Location Clustering Data
The actual data creates a firm depiction of what is going on inside the Local Pack. Here’s the percentage of keywords that produced the 2:1 pattern at both the city and state levels:
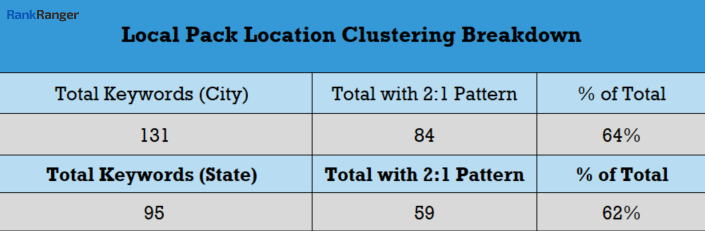
The 2:1 Local Pack clustering pattern is dominant across the board appearing within 64% of “city-based” Local Packs and 62% of “state-based” Local Packs. It’s quite significant to note that the percentage of times the 2:1 pattern appeared within the Local Pack at both levels was consistent, hovering in the mid to low 60% range in both instances.
This means, that even when the query includes non-proximal intent (i.e., a search across the entire state of California), Google’s clustering pattern remains the same, thereby indicating that its treatment of the query itself… remains the same.
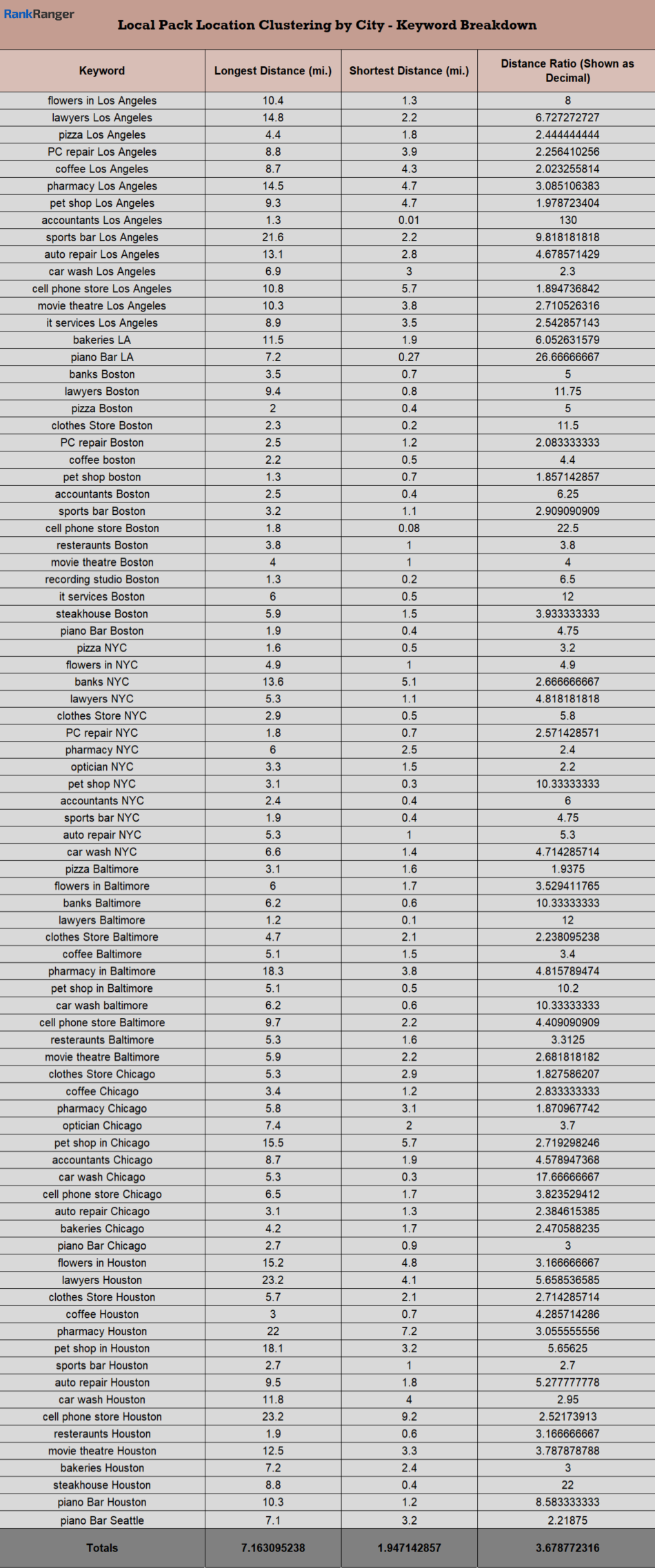
Moreover, there seems to be a proportional formula that Google uses when showing the 2:1 clustering. Have a look at the distance between the two furthest and two closest locations as a ratio (shown as a decimal for the record) when the 2:1 pattern appeared at the city level:
Now have a glance at the same data on the state level:
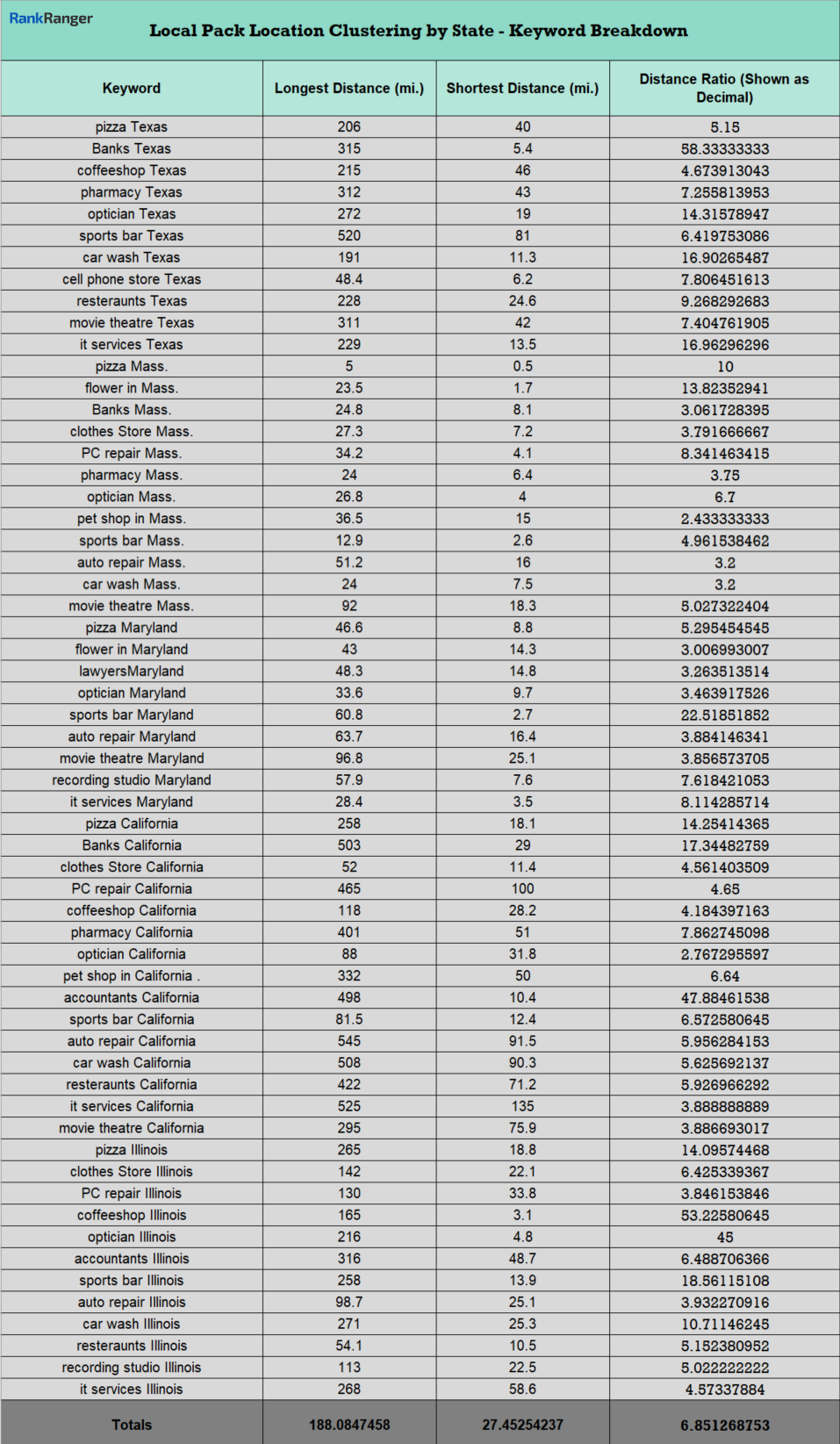
That’s correct! The distance ratio at the state level is double that seen at the city level. Adding a further degree of intention, the ironic 2:1 average distance ratio between the city and state level data emphasizes both Google’s intention to offer users two locations within a relatively close proximity and its well-structured formula for doing so even when the query seeks a broader set of results.
Here’s the data on the distance between the two nearest locations on the state level:
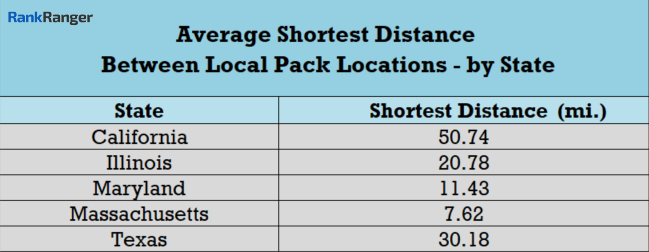
Texas is larger than many countries. Germany is smaller than Texas. France is smaller than Texas. Spain is smaller than Texas. The land area in Texas is 268,597 square miles. The UK stands at 93,627 square miles. Yet, the average distance between the two closest results for the queries I ran for the Republic of Texas (it’s technically not a state, but a Republic), was a mere 30 miles.
Let’s put this in real terms. Over the course of your trip, between both highway and street driving, say your average speed is 30 miles per hour. At 30 miles per hour, it would take you an hour to drive between the two closest Local Pack locations in Texas (on average, and for state-level queries). All things considered, it’s not unreasonable to expect someone on the hunt for a specific product or service to drive to multiple businesses within an hour’s distance in order to track down what they are in need of. Except that:
- I was nowhere near Texas when I did the search
- My intent was to see the best results across the entire state
The data shows that in smaller states, such as Massachusetts and Maryland the two clustered locations are ridiculously close. Massachusetts has a land area of 17,002 square miles. Here, the two clustered locations are a minimal 7.6 miles away from each other. That’s maybe a 15 –
Maryland (19,967 square miles) is the same, just 11.5 miles stand between the two closest locations within the Local Pack.
California
Why Local Pack Clustering Matters

Seeing the state-level data I was a bit taken aback. Is Google really assigning me a location within the entire State of Maryland and clustering two results to that location? That seems a bit hard to understand. We posed this question to Joy Hawkins, who confirmed the notion, saying,”If you search from California, Google is dropping the location somewhere near Long Beach because that’s what Google considers the center of California.”
Based on what I saw myself, I agree, Google picks a prime spot in a state (for Texas it was circa Houston) and goes from there. Except that I still don’t see the logic of it. Why would I search for pet shops texas if I really wanted Houston? It’s only the best for my little poodle Phee Phee.
What about tourists? What about someone who wants to go on a road trip from state-to-state? From the business side, what about statewide businesses, or, non-profits, or especially clinics? The latter is a great example. Many clinics are highly specialized. Its location is less of a factor than its purpose or specialty. Google though, does not seem to distinguish between the degrees of relevance location has to an entity.
My dad is actually a great example. He has a lot of problems with his eyes, and he would actually drive hours upon hours to see the best eye doctor in the state. So when Google shows him doctors in his neighborhood, or at least a “chunking” of them, is that what he really wants? This is especially applicable to places like New York City (where my dad lives). Sure, business X is around the corner, but is it really that hard to jump on the subway for five minutes? My point is, even at the city level, it is possible to be too focused on the user’s location. Especially in my case, where Google assigned me a location.
Simply put, does Local Pack location clustering point to an overemphasis on the search location within Google’s Local Pack algorithm?
Local Results – Too Local Perhaps?
It seems pretty clear that Google uses the same process, the same algorithm, even when they don’t know the user’s location or when that location is irrelevant (i.e., searching for something in NYC from the North Pole). Google’s overall practice and intentions are all good and noble. However, there are times where fundamentally basing Local Pack ranking on the search location does not work.
It very much surprised me to see that Google’s local algorithm functions the same way on both the city and state levels. The nature of those queries is very different. Even within a city itself, for certain business entities, specialization or even quality are far more important than proximity (think queries such as outpatient surgery
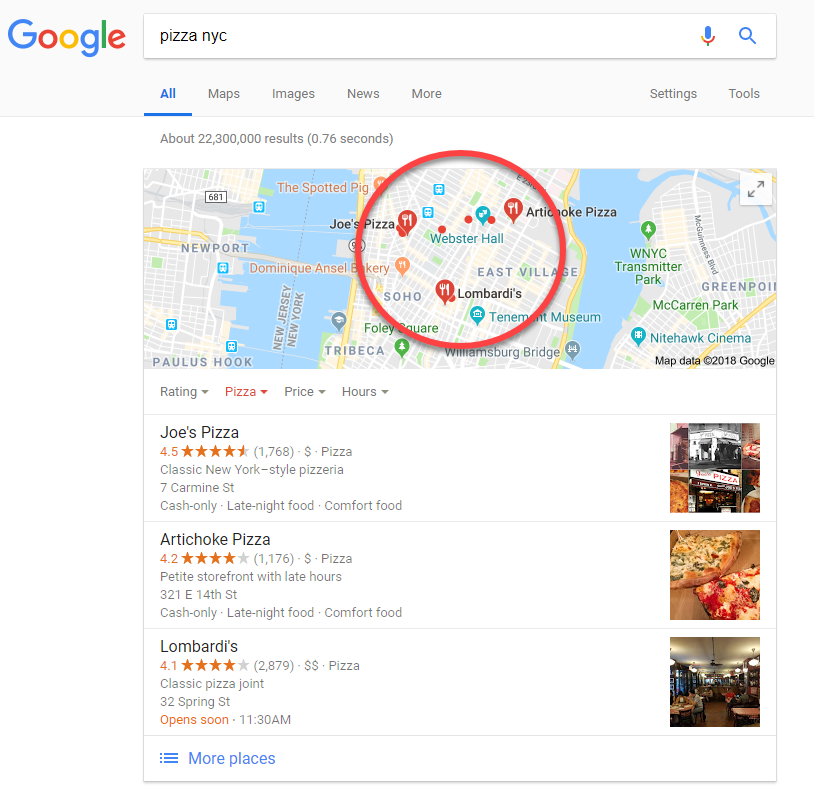
The mere fact that Google does not treat queries done from halfway around the world any differently than local queries made around the corner from the results shown is a bit curious. The reasons why someone who lives locally would execute a search is vastly different than someone doing the same search from a distance. When I lived in New York and searched for pizza
Are We Due for a More Dynamic Local Pack Algorithm?
Let’s put aside everything I said in the previous section for a moment. I would still argue that Google needs a more dynamic Local Pack algorithm. The 2:1 chunking pattern presupposes that Google wants to offer you listings that are as close to you as possible (while considering other factors such as ratings, etc.). At the same time, the pattern indicates that Google wants to offer a bit of diversity, and therefore shows that solitary result, the ”
According to this reasoning, showing this one solitary result when it’s less than a mile away from the other two “chunked” results wouldn’t be logical. Why show this pattern, why show this lone listing, if it’s in the very same area as the other two? Having all three listings within very close proximity
A picture is worth a thousand words. Despite how distant the “lone” listing looks in the below Local Pack, it is a mere 1.3 miles away from its most distant Local Pack counterpart (if you walked instead of drove, it would be a flat mile).
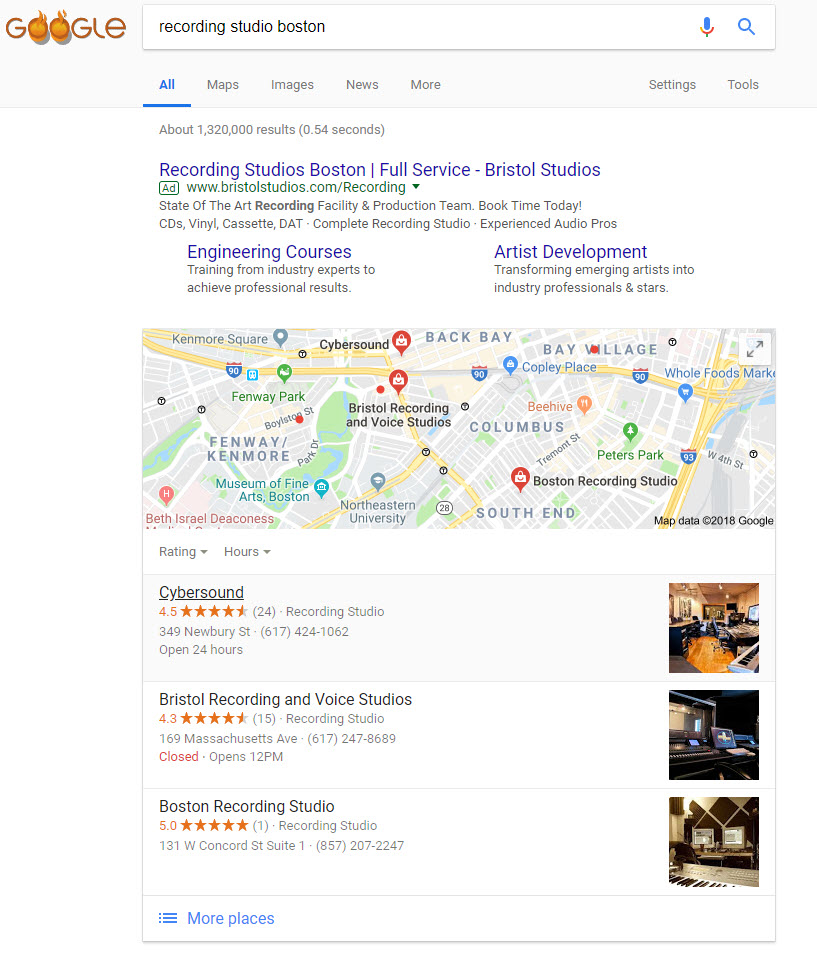
This Is Not Real Estate

This is not real estate, it’s not all about location, location, location. The 2:1 Local Pack listing pattern clearly shows that Google has a desire and strong propensity to focus on meeting the local searcher’s needs. Which as I mentioned earlier is exactly what Google should be doing. But are all such searches done by locals? Are business listings solely about finding something local? If they were, no one would fly miles to go to the Mayo or Cleveland clinics for treatment. I’m not advocating that Google can perfectly engineer a Local Pack algorithm that caters to all aspects of a local search and searcher. However, seeing Google run the same 2:1 pattern at the state level with the specific intention of doing so (think back to that distance ratio data) tells me that it might be time to make some adjustments to the Local Pack algorithm, but that’s just me. What do you think?
About The Author
