
Posted by
Mordy Oberstein
It’s the one story that Google would like to shake, but can’t seem to, Fake News. In a way, it’s the story that may define this era of search. Fighting fake news encompasses the full spectrum of the meta issues that make search so complex. With underlying ethical underpinnings that bring into question where Google’s content responsibilities begin and end, along with the technical boundaries fighting fake news stirs up, the issue is in a way epic. Over time Google has released a series of statements, and even the announcement of a new project, all indicating it is on top of the Fake News faux pas. But are they really? After taking a hard look at how Google goes about broadcasting information media, that would be news to me…
Google Cannot Effectively Combat Fake News
So where do we currently stand in the battle against fake news? To fight the good fight Google has released Project Owl into the wild. The panacea for all things fake news, the project was birthed at the end of April 2017. With it, Google uses quality raters, actual people, to manually “teach itself” to pick up low quality search results and inaccurate Featured Snippets (as an aside these quality raters have subsequently had their hours slashed by Google). This leads into the next major aspect of the fake news fight, site authority. As you can imagine, less than quality news originates from less than quality sites, at least that’s the going theory. Subsequently, Google has indicated that articles originating from more authoritative sites will be given preference within the results.
My Claim: The Fight Against Fake News Is Not Feasible

On the surface, this sounds all well and good. Google is not putting a machine on the job, but actual people. More so, it is dispensing with low-quality sites and favoring those with authority and prominence. However, as I will show, I believe these methods of dealing with fake news actually arise from Google’s inability to actually combat it. That is, they are examples of Google’s limitations rather than its advancements and potent capabilities.
The limitation being that Google cannot actually determine what is “news content” to begin with, let alone what is “real” or “fake” news content. That is if Google, as I claim, cannot accurately determine what is and what is not news content per se, then how is it possible to differentiate between various forms of news content? To this extent, I will show that Google’s methods of rectification, as mentioned above, arise out of the search engine’s very limitations.
To support my case, I will make use of a long series of Google News Boxes (often referred to as Google Top Stories) to show you that Google indeed has a tremendously difficult time accurately picking up news content. That quite often, Google places content from “news sites” into its News Box that is not actually news.
Ironically, in terms of the SERP, the News Box is obviously the most prominent place for news to appear, yet, almost all discussion related to Google’s take on fake news relates to organic results and/or Featured Snippets, as I indicated earlier. However, as the most fundamental news placement on the SERP, I believe Google’s News Box is at the very center of its inability to deal with Fake News, or as I claim with any news at all. In other words, to determine the effectiveness of Google’s fake news fight we have to see how it is that Google goes about processing a piece of news content and this is most plainly seen by studying the results Google chooses to place within its News Box.
The Case Against Google’s Ability to Fight Fake News

Before I begin I want to ensure that what I present here is not taken the wrong way. I am not trying to catch Google in a web of lies, I am not proposing Google has been less than truthful with the public in any way, as I do not suppose that Google has done anything that even resembles malicious behavior. What I am proposing is, that like any public entity, be it a person or corporation, Google has, and in fact quite wisely, held their full hand of cards quite closely. This, of course, is common practice not just for a corporation but of humanity itself as it’s human nature to preserve one’s image to the best of one’s ability without crossing any ethical boundaries. Thus, all I am simply going to do is provide some insight into what Google has chosen not to reveal publicly at this time.
To accomplish this, and as I mentioned briefly above, I will highlight multiple cases that indicate Google’s lack of ability in discerning true news content, specifically the content Google so chooses to show in its News Box. The end goal is to illustrate a pattern of behavior that directly points to the method Google uses to select content for its News Box. Once a pattern can be established, and Google’s methods broadcasted, it will be possible to show the limitations of such methods and why these limitations preclude Google from being able to combat the fake news problem in any meaningful and direct manner.
With annotation now out of the way, here are the aforementioned cases:
Spam In the News Box
Let’s rock the boat a bit with a wild claim…. Spam appears within Google’s News Box more often than you would suspect, and it does so right under your nose without much of a scent. To showcase this, I selected the keyword, bad credit. With such a query one would expect a News Box containing articles related to whatever credit law is working its way through Congress or whatever legislative body so wishes to tackle finance law. Should there be no news related to credit law and the like, I would expect that Google would not show a News Box.
However, none the two aforementioned options are the case as Google shows a News Box with no actual news within it. This would be a good time to create a working definition of what it is we mean by “news.” When I say news, I mean content that reports on the unfolding of recent events of any nature. That is, for something to be news content, at least part of its significance must be its timing. This is in fact distinguishes what is news from what is history.
To this extent, Google themselves lists an article’s time of publication within the News Box. This is important to note, as many of the examples I will present here show News Box content unconnected to time related events. This, of course, is a contradiction. What purpose does specifically showing how long ago something was published, to the specific hour at times, if the content, and its latent significance, lack any association to time?
In regards to the case at hand, Google is doing just that, showing a News Box with three articles that are not news content in any shape or form:
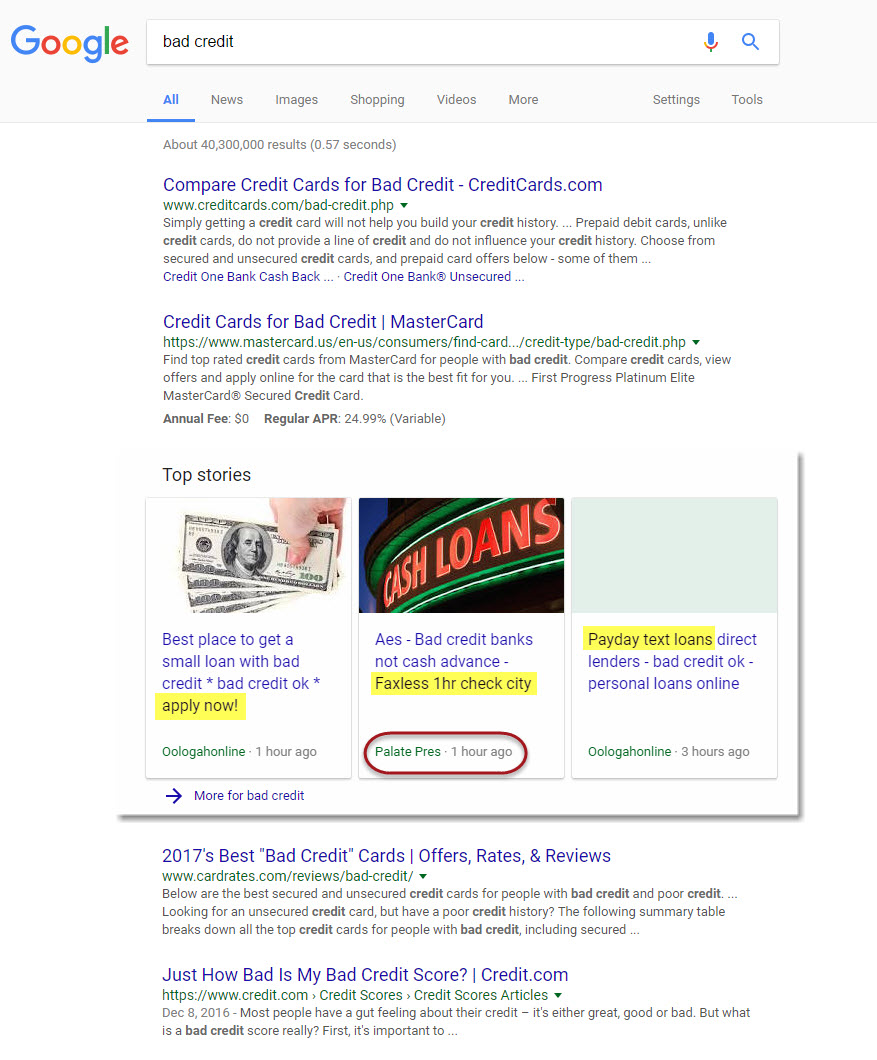
Let’s begin dissecting this result for a moment. The sites listed within the organic results seem to be sufficiently in order. For example, the first two sites allow those with bad credit to apply for an appropriate credit card, with the second site being a major international credit card company.
The results in the News Box, however, are not only unrelated to news, but they are spam. Here are the problems with this News Box in specific:
1) The Titles: Notice the title of the “article” within the first result: Best place to get a small loan *better credit ok* apply now!. By definition a news article is an informative piece of content that by its nature cannot contain a call to action.
Moving to the second “article” and the title is incomprehensible, as “Faxless 1hr check city” is completely indiscernible. What is a “1hr check city” exactly?
The third title is absolutely astounding as it indicates it is offering a Payday loan. For those who are not aware, Google has banned ads for Payday loans from appearing within AdWords, yet here is a call for such a loan within a Google News Box.
2) The Sites Themselves: It would appear that there are two sites represented within these three results, Oolaogahonline and Palate Pres. This is not true, they are all one site, Sendmycashnow.com:
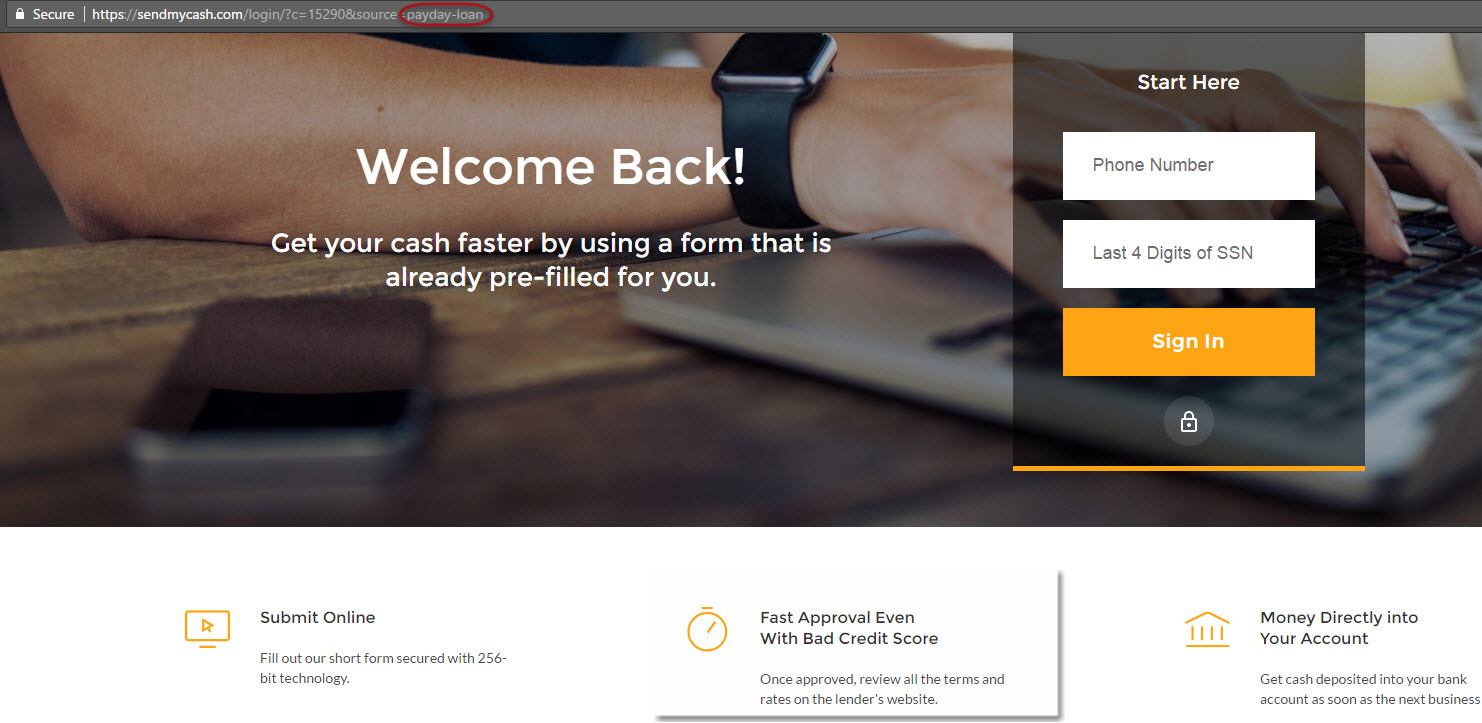
The site’s name is only the beginning of its spammy nature. The site boasts that it can obtain a fast loan approval even with bad credit as it searches for loans for you from across the web. Of course these are short term loans where “all types of credit [is] considered.”
So then, to recap, Google is not showing news within the News Box. More than that, it is showing sites that are deceiving in their name, and that for all intents and purposes offer a “spammy” sort of service. I would not expect to see such a site within the first 10 pages of organic results, let alone front and center in a SERP feature.
Google News Takeaway
How could this have happened? I’m not going to give an unequivocal answer for this specific instance, simply because I can’t, only Google knows this. However, I can begin to paint at least part of a picture. Looking back at the second result’s title is the first clue, Palate Pres. Despite being spelled incorrectly, I do not think it was an accident that the site employed a name related to news media (i.e. the intended word press). Though it certainly does not explain how such preposterous results landed in a News Box, it’s something to keep in mind moving forward.
A Common Query for Inapt News Results
The idea that Google at times places content within a News Box solely because it is found on a news site and relates to the query is novel. However, it is not uncommon once the query moves away from a trending news topic. In fact, to find such instances, one does not need to employ a set of obscure keywords.
The below is a News Box that appeared on the SERP when the term “SEO” was searched for:
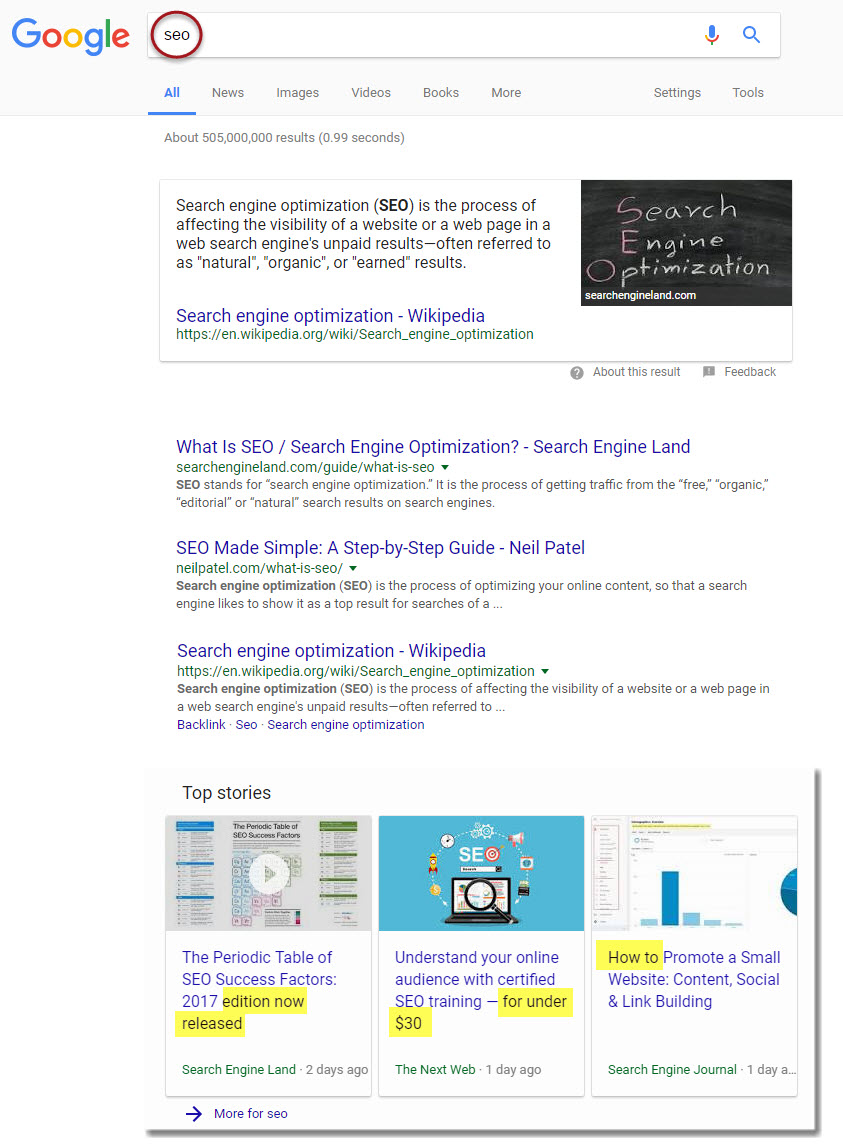
Most noticeably, the three sites shown in the News Box are household digital news names. However, at the same time, we did not need to search far and wide to find a News Box that contains no actual news content. That is, not all of the content on these “SEO news” sites, is actual news coverage. Often, the content shown on these sites relates to tips, how-tos, etc. Such is the case in all three instances within the above News Box, there is no genuine news content.
Going through the listed results themselves:
Article 1- Search Engine Land: The article presented here is a form of self promotion. Search Engine Land has a fantastic guide to SEO that it calls The Periodic Table of SEO Success. Recently, the site updated the guide and what is presented here is their announcement to that effect.
To accentuate the point, having the above results within the News Box would be like Google showing an editorial from the New York Times instead of a true current events article. Logically, the next question would be, why is it that Google, generally speaking, does not tend to show editorials from major news outlets within its News Box?
The answer is actually very straightforward but supports the idea that Google is not able to truly discern news content. Sites like the New York Times have a separate section for opinion pieces, whereas sites like Search Engine Land, do not. All of their SEO “news,” be it actual breaking news or a how-to appear, within the same section of the site. That is Google, when scouring news content on a site, is not aware of the character of the content itself but relies on structural clues to guide its way.
Article 2 – The Next Web: Of the three listed articles, this is certainly the true “odd man out.” The title of the “article” already raises suspicion as it includes a price! Sure enough, upon clicking the site, a promoted piece of content appears (see below). This is a blatant example of Google confusing promotional content with news content solely because of the site’s overall nature and purpose.
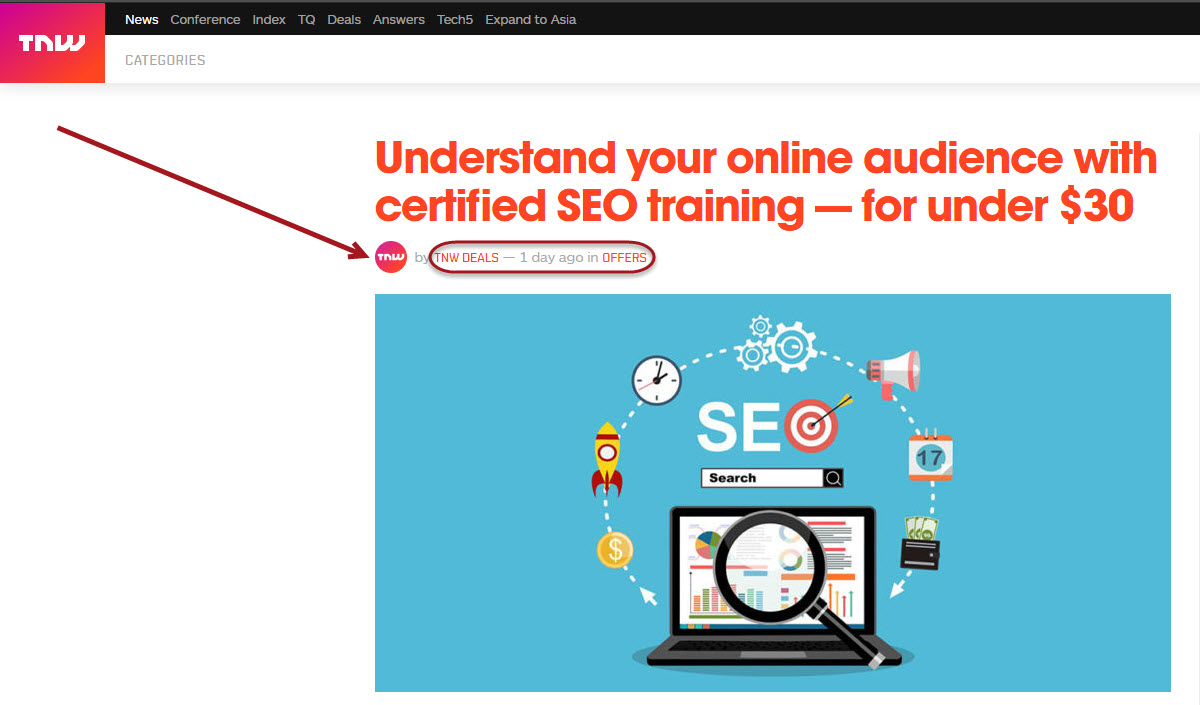
Article 3 – Search Engine Journal: Here too, the misinsertion of the article into a News Box is a bit obvious. A simple glance at the title tells you that this is not a time associated piece of news. Rather, it is as it says, a how-to. It almost highlights how linearly Google is operating here. The article, its association with SEO, and its placement on an SEO news site were enough for it to appear within the News Box, despite the fact that a quick review of the keywords within the title would indicate its true character.
Google News Takeaway
The eminent virtue of the above “news” results are the results themselves. As I’ll show, there is no lack of news deficient results. At risk of stating the obvious, the SEO industry is a robust news producing enterprise. The sites shown in the News Box in the example here, are some of the more prominent SEO news sites. What is peculiar is that Google, despite the industry serving up a variety of news stories on a silver platter each and every day and despite the numerous news outlets, could not conjure a single piece of authentic news for its SERP feature. All the more so for the most general of keywords, “SEO.”
This is incredibly incriminating if not altogether bizarre. In fact, it’s the latter quality that perhaps is more pertinent. Observing such strange and if not fickle Google behavior begs further inquiry into how such inadequate search results can even come about. That is to say, such results may be understandable for an outlandish set of keywords within an overly narrow industry or niche, not within Google’s very own habitat, SEO. How then did we get here? Rather, how then did Google get us here?
Call to Actions and Google News Results
Call to actions, by definition, are heavily associated with eCommerce, not news media. While not impossible, the relevancy of a time dependent piece of news content to keywords that are all but calls to action would intuitively be quite sparse. That is, by its very nature, a call to action aims at stimulating a response, not informing, certainly not in the manner in which news content does. Though not necessarily common, at times Google does show its News Box for a keyword that is a call to action. These News Box scorings tend to be “unconventional” and bring into question why their appearance on the SERP is pertinent at all.
The below is what resulted for a query for buy this now:
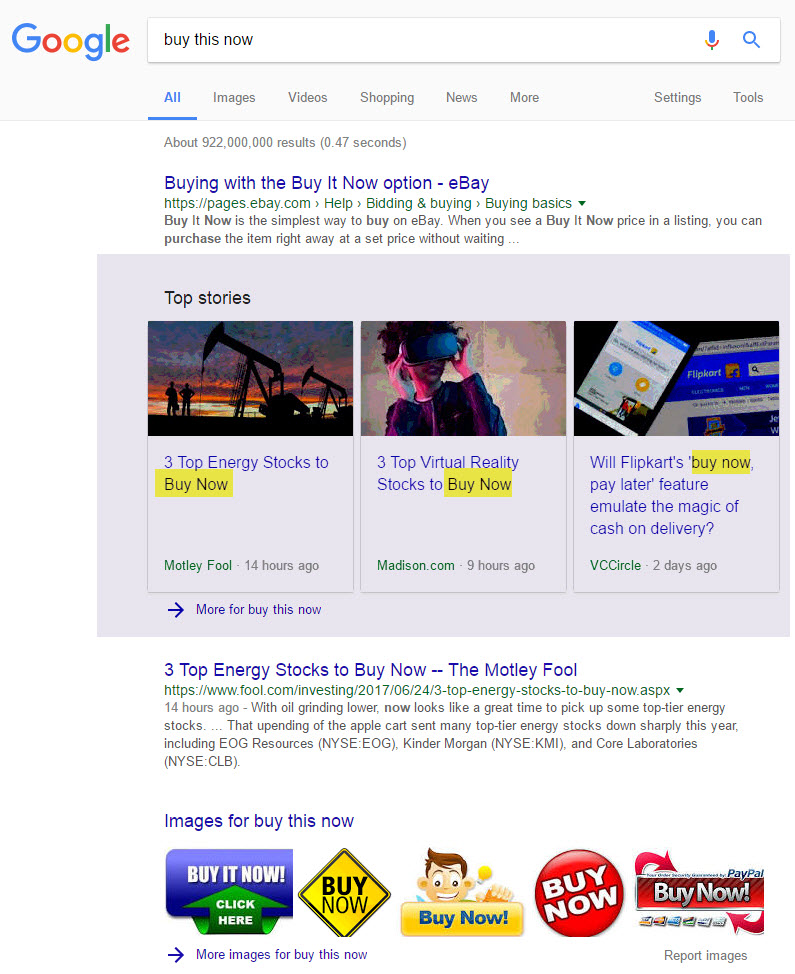
Glancing at the titles, it becomes apparent that Google matched the query to articles that included the term “buy now” in their title. This is in fact important to note as it will become abundantly clear just how much stock Google places in having keywords within the title, despite both the article’s lack of relevancy and identity as genuine news content. Beyond the evident, there is much by way of insight when looking at the results per se within the above News Box.
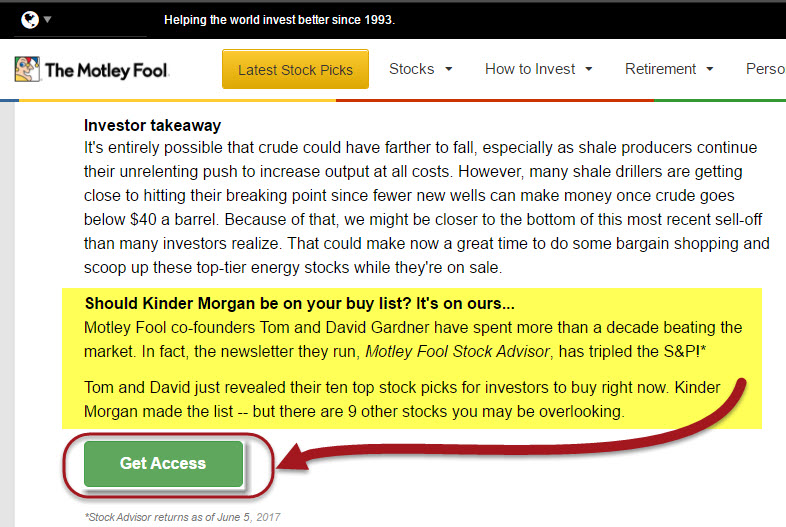
Article 1 – Motley Fool: Stating the obvious, the article is not news content, but stock recommendations. The closest the piece comes to being news content is its relation to current stock and commodity trends. Fundamentally, it is not news as no new information was revealed, only how to manipulate what has been disclosed previously, i.e. stock prices, etc. The authenticity of this article, as a piece of news content, is further brought into question by the soft sale at the post’s end, where the reader is called upon to join a mailing list so as to receive stock tips.
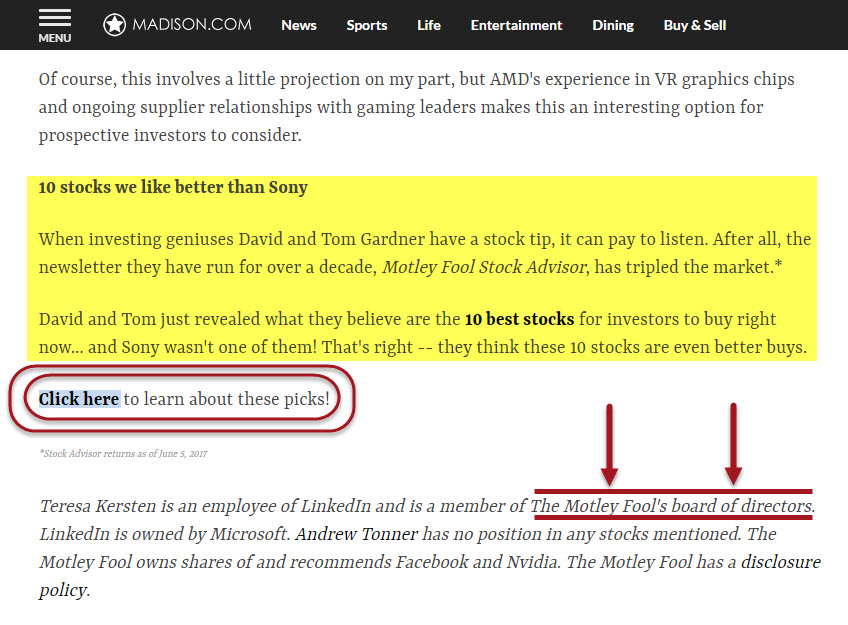
Article 2 – Madison.com: Two things stand out. The first is the nature of the site, madison.com. It is a site dedicated to sharing news related to Wisconsin’s capital city of Madison. For the record, the search was not conducted in Madison, nor within 500 miles of Madison. This is important in light of the second notable aspect of the result, its original source. The article was written by a member of Motley Fool’s board of directors. It is beyond coincidental that two articles, both originally sourced to Motley Fool appear next to each other within the News Box.
Here, like the article on Motley Fool itself, the post ends in what is for all practical purposes the same soft sale as found in the previously mentioned article. Thus, as is evident, Google has either ignored, or more likely, was not able to notice the pattern of soft sales that appear at the end of Motley Fool’s content, and as a result has placed sales-like content within the same News Box, twice.
Article 3 – VCCircle: Of the articles presented in this News Box, this is the closest to being actual news. The article is an analysis of a new Flipkart option. Had Google been more accurate here, it would have at least presented content related to the announcement of the new feature, which the site, VCCircle, published a few days prior to this one. What is most peculiar is that the site in question is based out of India, and relates news and other such content within the context of that specific geographical location. Thus its appearance next to a site from Madison, Wisconsin within the News Box is slightly offbeat for a search engine that tends to not only be more precise but rhythmic and patterned as well.
Google News Takeaway
There are numerous oddities and patterns in this instance that require further investigation. That being said, there is an enormous insight presented within these results that drive the conversation forward, namely the significance of keywords within an article’s title. Regardless of the incongruity between the standard use of the language that is the keyword, so long as the keyword is prominent within content that Google believes to be news, it will appear on the SERP. That is, Google, as will be evidenced repeatedly in this post, has tremendous difficulty in the labor that is matching news content with user intent.
Further, and as previously indicated, Google struggles with deciphering content on a news-like site, and as such often cannot distinguish between what is and what is not news content on such a site. The clearest example in this particular instance was the result from the VCCircle site. The site is part of News Corp, which was founded by Rupert Murdoch, and includes news publications such as The Wall Street Journal within its conglomerate. The point is, as the VCCircle site is intrinsically tied to a large newsgroup, Google was in a sense fooled into thinking the content it displayed within this particular News Box was as such genuine news content and not analysis.
News Site Status and Titles Matter – Not Relevancy
At the risk of sounding repetitious (but for the sake of clarity), Google will quite often show content within a News Box based upon two disjointed characteristics:
1) The article’s title, specifically when the keyword for a query exists within it.
2) The nature of the site sourcing the content as being a news media site.
To prove this to be the case, a query for get it was executed and the following News Box was the result:
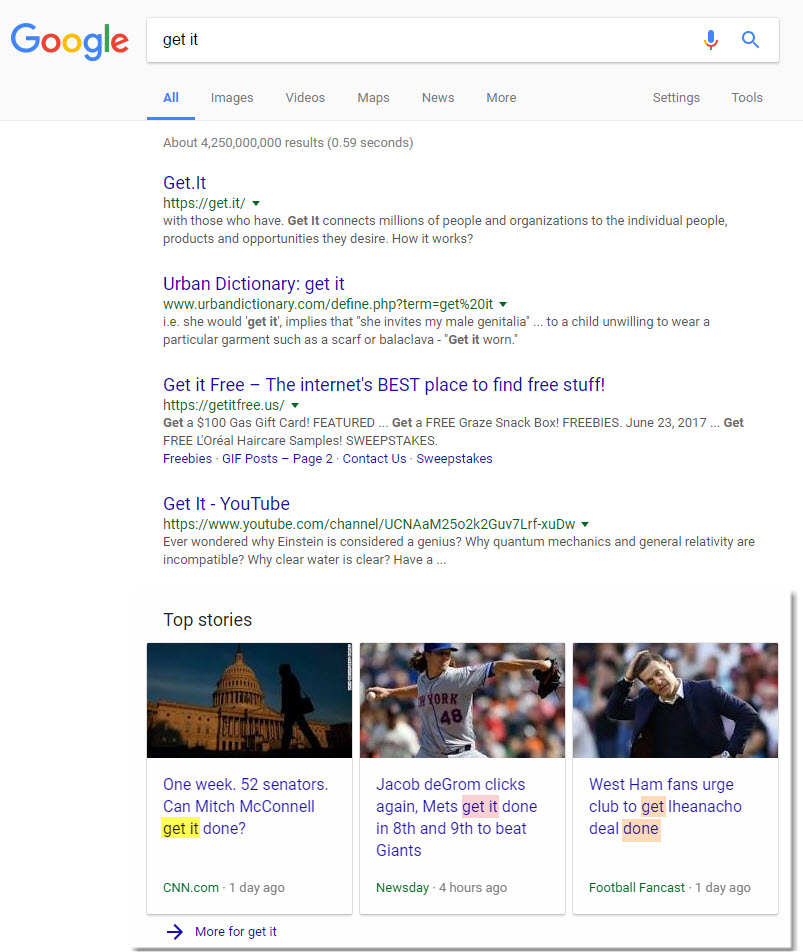
The query, in a many ways, is incomprehensible from an intent perspective, and should have precluded a News Box from appearing. A notion supported by the very organic results Google displayed on the SERP, which ranged from a definition of the term get it, to a site whose URL includes the phrase get it, to a publication entitled Get It Online. Pointedly, how is it that Google can offer a series of news related content for a term it itself does not understand?
The answer is that it cannot and it did not. Each of the articles shown within the query’s News Box are only present for two reasons:
1) The article’s title, specifically as the keyword for the query exists within it.
2) The nature of the article’s source as a news media site.
The evidence for this assertion lies in the relationship that exists between the three articles, which is none. The articles here are releases of previously undisclosed information, to the exclusion of the first result from CNN, which like many of the articles previously mentioned in this post, is analysis. Despite the authentic news being disseminated, at least via the latter two articles, they are unrelated. That is, none of the articles within this News Box have any connection to each other beyond:
1) Their usage of the keyword in their titles.
2) Their being on a site that publishes news content.
Topically speaking the three articles are entirely unrelated from a specific news matter. It is therefore evident that Google did not display them as a means of sharing news content related to a specific topic. Rather, Google is not able to delve that deeply into either intent or topical anatomy and syntax. Simply, these three articles appear together as result of what it is all but an accident that originates from the shared term within their titles.
This is huge. The fact that Google, when showing News Boxes related to common news topics is able to show a series of related and relevant content… is accidental and is not the result of a prolific ability to discern between various forms of content and their contextual relevancy. Understanding this point is the single most important facet of determining Google’s ability to display news content and subsequently battle against fake news being placed on the SERP.
In the below example, the phrase just released was entered into the search box. Like the term get it, the query is ambiguous and could relate to any one of a million things, as indicated by the diverse organic results. By all appearances, however, the News Box, interestingly enough, seems to be quite on target:
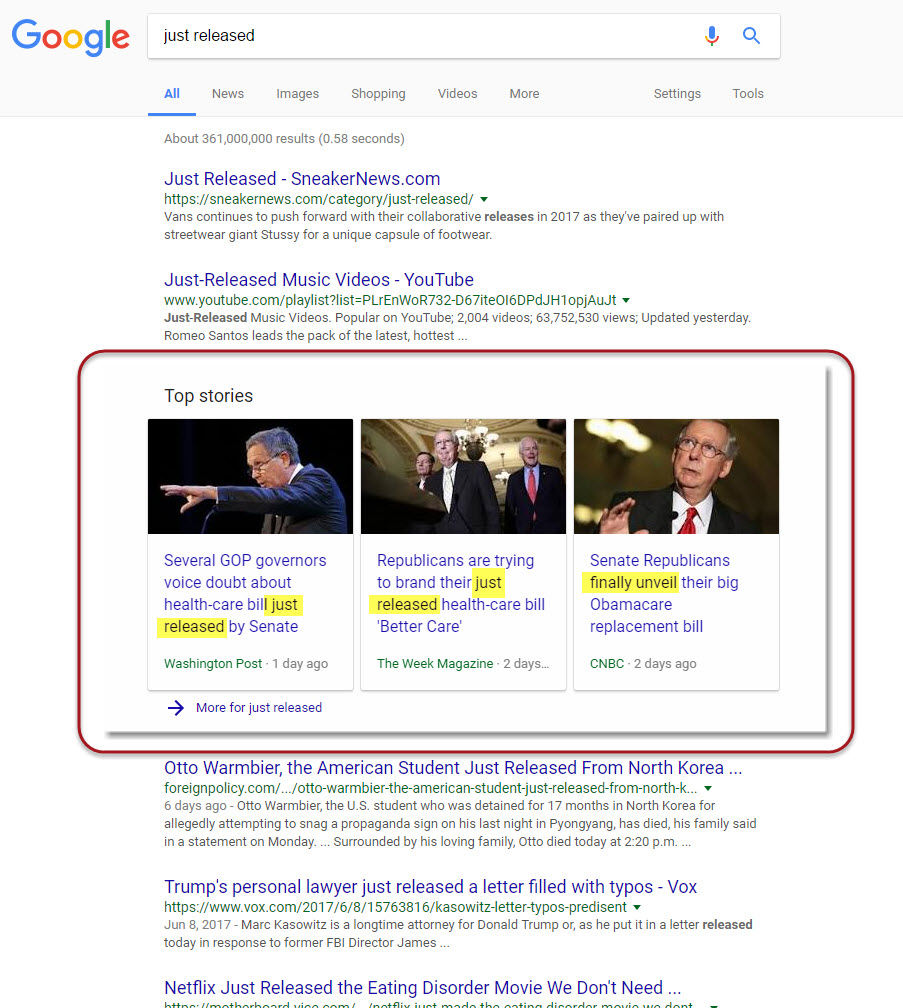
This of course, cannot be the case as the organic results with their lack of cohesion prohibits the possibility. In fact, while more than one of the organic results relates to a news topic, none of them had any connection to the news story presented within the News Box itself to the exclusion of the page’s last result.
The cohesiveness of this News Box is a ruse of sorts. Its topical consistency comes not from Google’s ability to discern news content, but from the fact that all of the results have the keyword (or a synonym of it) within the title and are sourced to a news site. The fact that all three results are related is an “accident of moment.” At the time of the writing of this post, a major piece of legislation was just released by the US Senate. As a result, the titles of an abundance of stories related to this topic included the words just released or some variation of releasing:
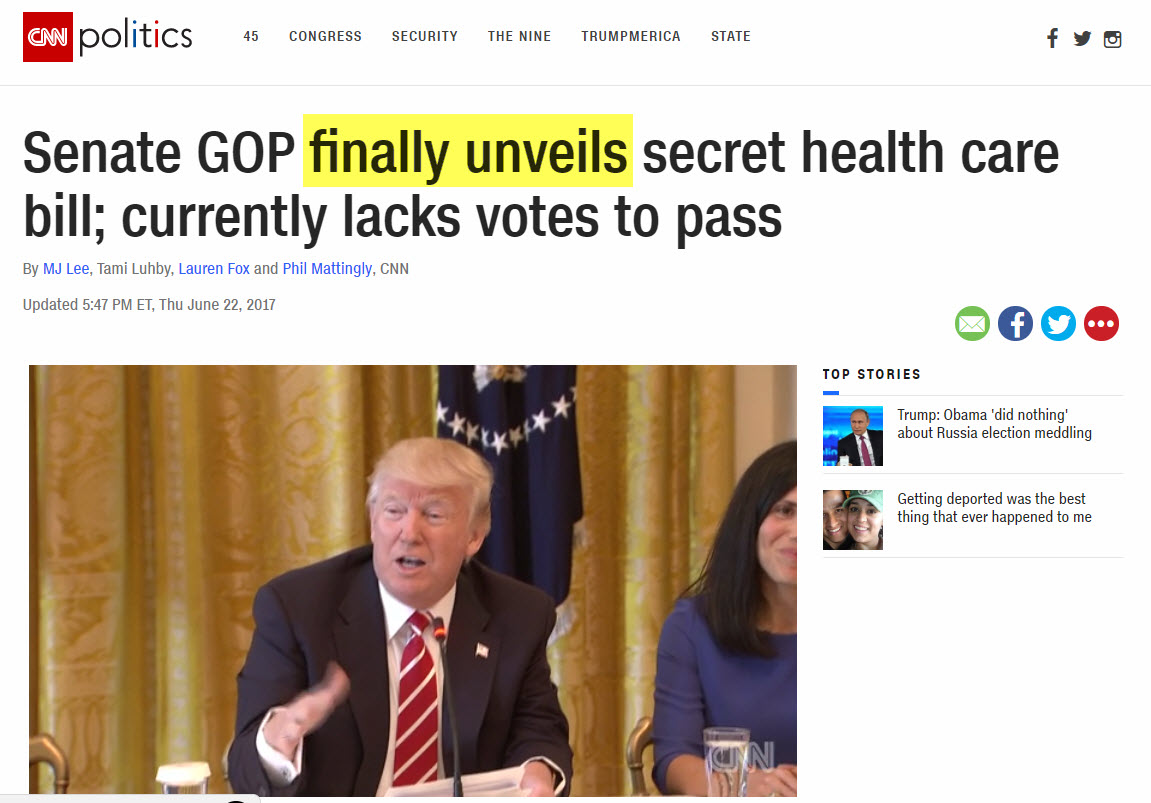
CNN:
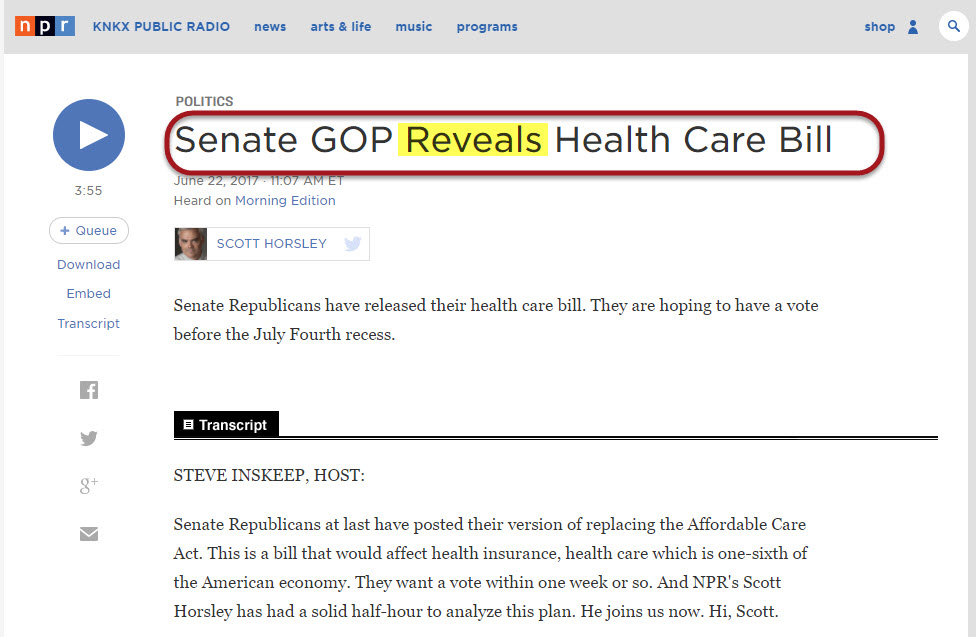
NPR:
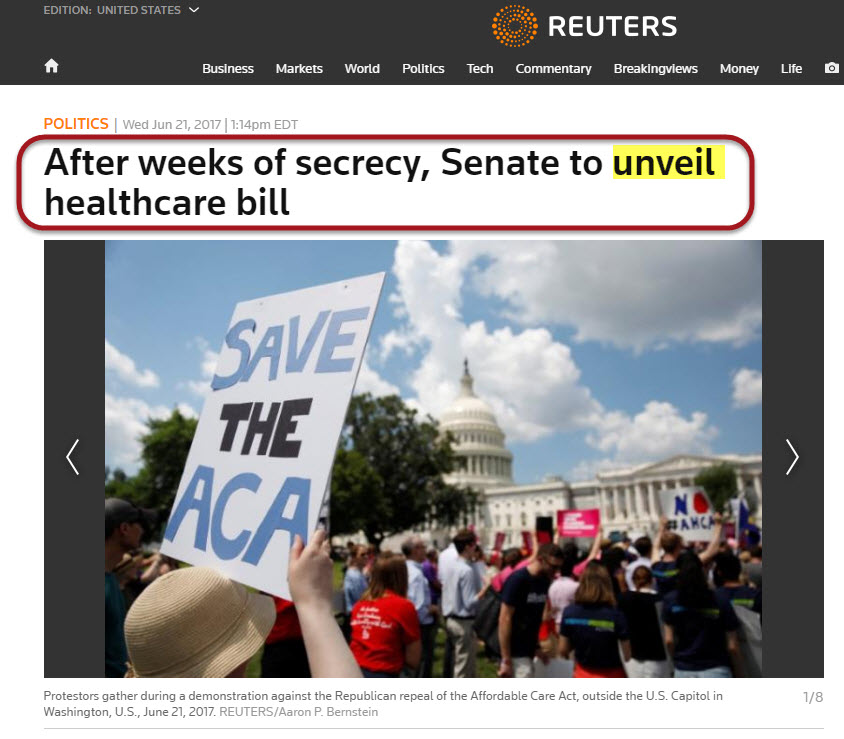
Reuters:
NBC News:
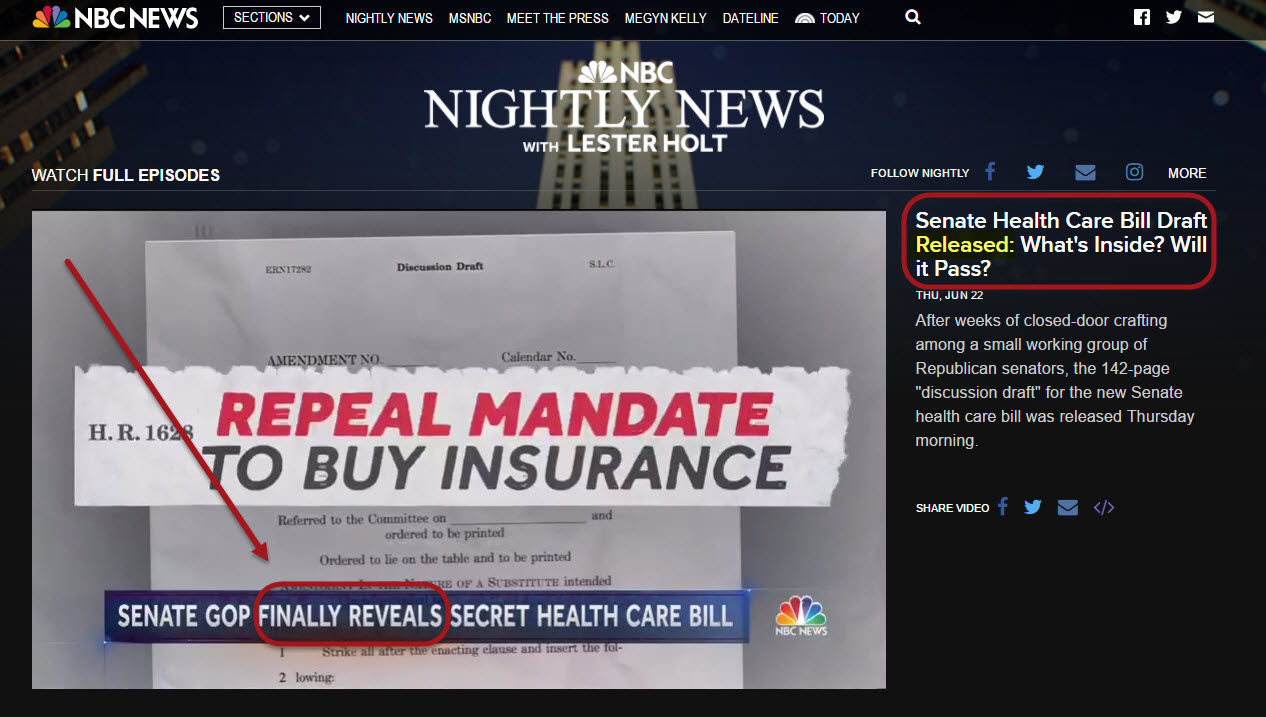
In other words, that Google placed three similar stories in one News Box did not come about because Google comprehended the content it was looking at in some sort of act of discernment. Rather, Google saw numerous authoritative news sites producing content related to some sort of release that just happened to relate to one topic. Meaning, had there been a plethora of news stories related to a multitude of “releases” spanning numerous topics, Google would not have been successful in placing successive stories in the News Box. Rather, stories with the keyword “released” relating to multiple news or news-like topics would have appeared.
Google’s Inability to Analyze News Content Even for Direct New Queries
Google’s inability to purposefully place relevant and related news content into a News Box is deeper than the above indicated examples. The fact of the matter is, Google cannot interpret the meaning of news content. It has no way of intelligently interpreting the meaning of a query and evaluating news content in order to present the most relevant news results. This inability to evaluate news content on a qualitative level is pervasive, not limited to outlying News Boxes, but applies to the most centered and core news queries. As a result, and as will become overwhelmingly clear, Google has no real way of providing news results that actually match the intent of the users, even when the query is directly related to news content.
Google Cannot Interpret News Terms
Google can only show news related to a specific topic. Should topical phraseology be absent, Google cannot interpret the query so as to provide adequate results, no matter how common the term, or how clear the intent. To reiterate what has been mentioned earlier, Google, even in cases where indeed relevant news results are supplied, relies on titles and site status to provide news results. Again, that it often succeeds in doing so is the result of titles that happen to match the query, i.e. they are not the product of Google interpreting the intent and analyzing the article qualitatively. It is at its essence an accidental process.
It is precisely for this reason that queries where the intent is clear, the phrase common, and that are directly news indicative, do not produce relevant results without specific topical phraseology.
For example, say a query is done for the term breaking news. It is within reason to assume, if not to expect, Google to interpret the query as meaning the user is searching for the most global, broad, and publicized breaking new stories (with emphasis on most publicized). Plainly speaking, one would expect Google to show the top stories as found on the biggest news sites, i.e. The NY Times, CBS News, CNN, ABC News, etc. (For the record, at the time of the writing of this study, Google does not show a News Box for the query top stories, nor for top news stories, which is self-evidently peculiar, though based on the above, not entirely surprising).
The below is an actual query for breaking news:
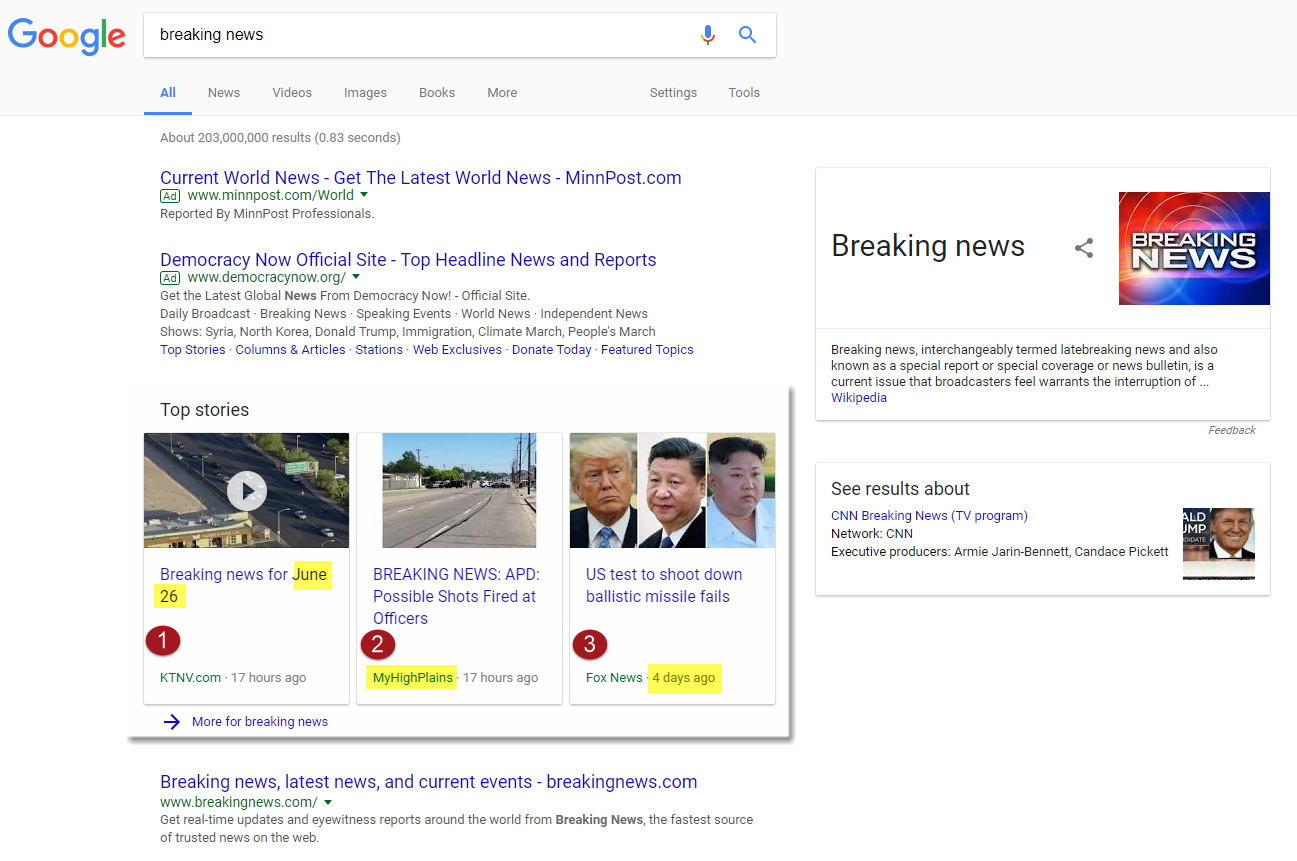
What of course stands out is a lack of content from one of the major news publishers. Further, the first result is not topic specific at all but rather is a summary of all breaking news out of Las Vegas as supplied by a local news station (for the record, this search was not done in Las Vegas). The second result is actual breaking news, but not of the universal kind. Rather, the content relates to breaking news out of Amarillo, Texas (again, this search was not executed in Texas either). These two results are present as they include the term breaking news within the title.
Neither the first nor second result, however, are as profoundly indicative of Google’s news placement problems as the third result. Published by a major news organization, and relating to a universally broad and genuine news topic, the third result of this News Box is the most troubling. The article that is the third result was published four days prior to this search, an ominous fact. Ominous in that it is suggestive that Google, is in fact, trying to comprehend the query. The search engine has produced a genuine piece of breaking news, had the search been done four days earlier. As it is in fact four days later, the news is by definition no longer breaking, and since its publication, an entire volume of breaking news stories have been published, yet Google chose this article for its News Box.
In other words, all of this time, Google has been trying to interpret the query and analyze the content, it has just been failing miserably. It is not that Google is derelict in attempting to analyze the content appropriately, but should it make an attempt it could. Meaning, it’s not that for whatever reason Google refuses to put its energies into doing so. The situation is far more dismal in that Google is making an attempt and even at the most basic level, for the most readily understood query that is a staple of news jargon, cannot break the relevant results plane.
Multiple Cases of Google Not Being Able to Determine News Relevancy
The above is not a limited instance. Across the board, for queries that are generic and relate to types of news, not specific news topics, Google is unable to supply relevant results. If a specific news title does not match the query, or if Google cannot simply look at a heading on a news site and pull a story (i.e. US News, where a query for the same will consistently show relevant articles), the results will not match intent.
Take for example the below News Box for most important news:
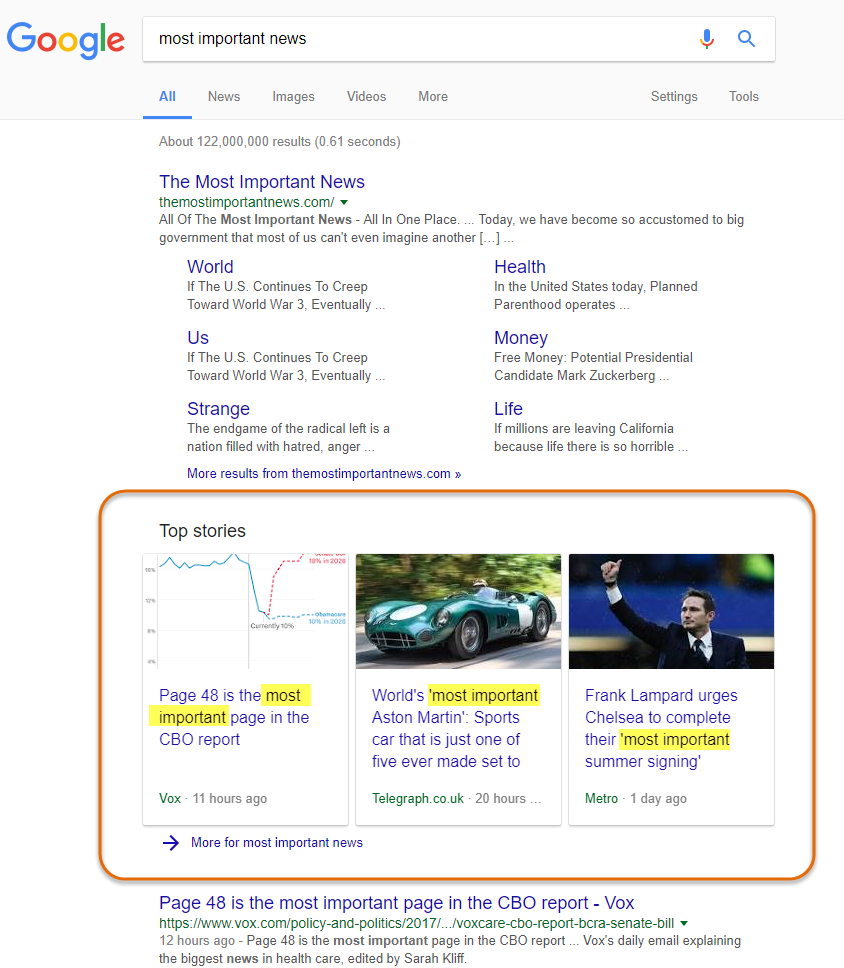
Regardless of the **** these results appeared for, they are certainly not the most important news stories of the day. It’s self-evident that these articles were placed on the SERP because their titles included the term most important. Google simply tried to match the keyword to news from the most authoritative sites it could.
For the record, the above News Box appeared on June 27, 2017. At the time, the United States government had announced that Syria had plans to use chemical ******* against its own population. CBS News, of course, had the story front and center on its homepage:

Yet, despite the overwhelming importance of the above shown story, or of a plethora of other June 27 new stories, Google did not place it, nor any other of the day’s major stories, into a News Box for a query specifically looking for the most important news.
Just to drive the point home, the below is a News Box that appeared for the keyword big news on June 29th:
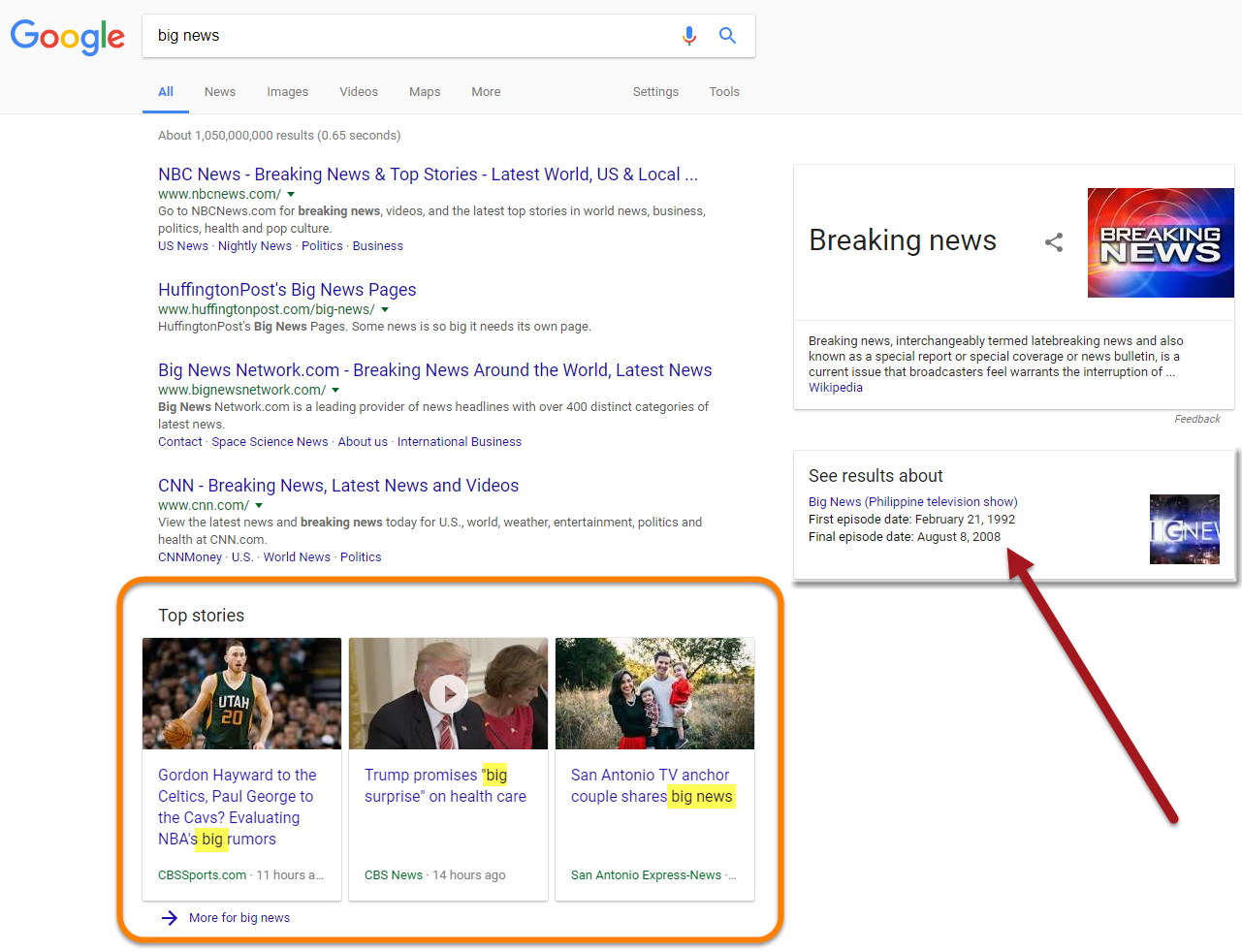
Two things are evident; the intent of the query and the inadequacy of the results. The terms big news has an obvious connotation towards news that is of significance. Gordon Hayward’s possible trade to the Cleveland Cavaliers does not qualify (see first article). While the overhaul of the US healthcare system is big news, Trump’s promise of a “big surprise” related to it, is not (see second article). A married pair of San Antonio news anchors sharing that they are again pregnant, is congratulations… not big news in the global sense (best wishes to the couple of course).
Looking again at CBS News, the source of the second article in the above News Box, and expectedly, a series of more important and vastly more significant news headlines appear:
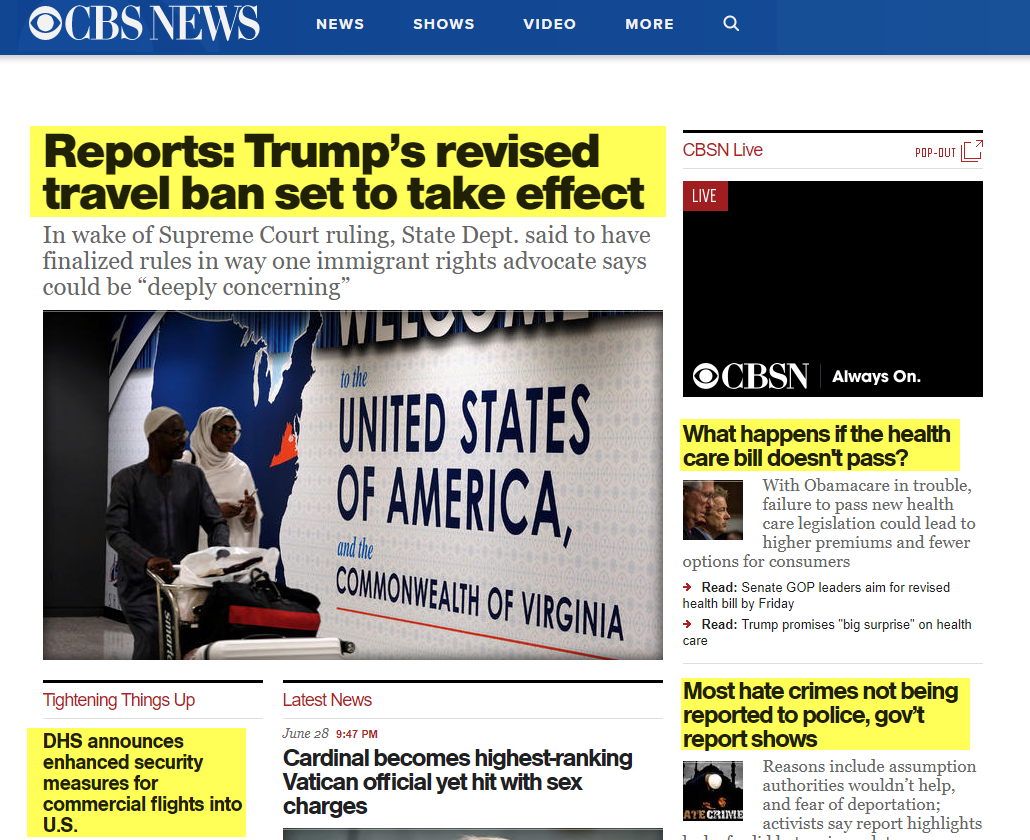
Any of the above headlines would have been a more appropriate fit for the above query. Yet, because neither the keyword big nor news is contained within these headlines, Google chose to supply a set of wholly irrelevant results.
The lack of sophistication in the way Google goes about featuring news stories within its top showing box of news is in many ways unbelievable. However, the above results do not lie and are by their multitude and keyword simplicity, not isolated incidents. However, if you are in search of further evidence, look no further than the Disambiguation Box on the SERP for the keyword big news (see above). Google, in this case, was uncertain whether big news referred to significantly important current events or a news show based in the Philippines that was canceled in 2008!
Don’t be fooled by the occasions where Google “gets it right.” As mentioned earlier, this is accidental. Take for example a query for latest news:
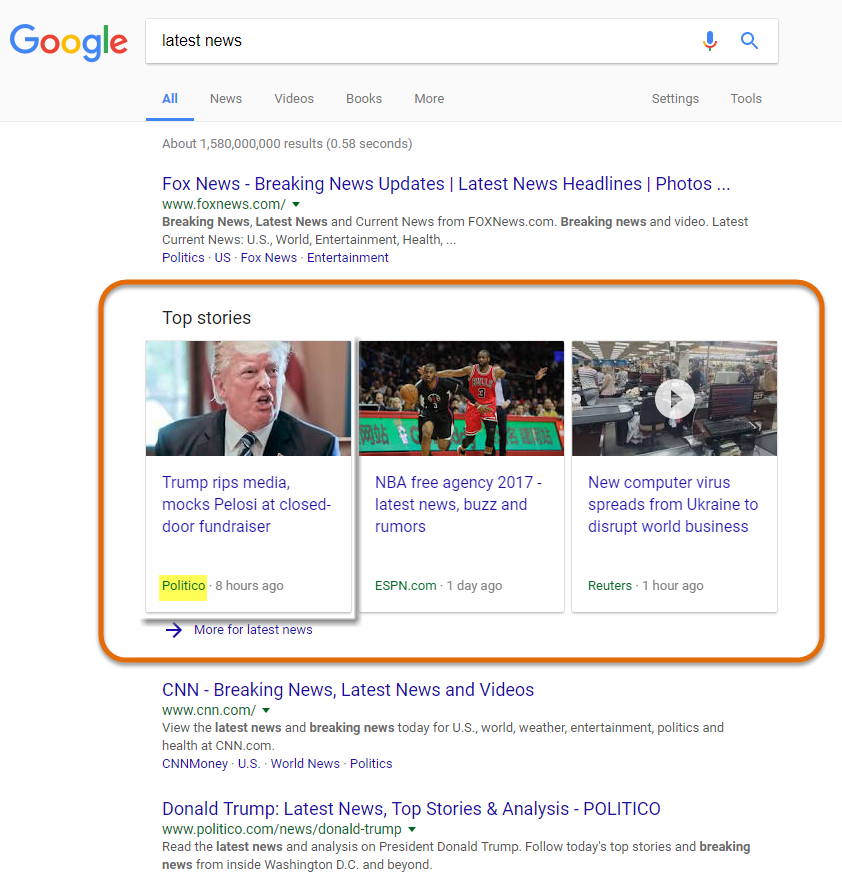
Everything in this News Box looks copacetic. You could even advocate that the sports article appears due to the broad nature of the query. However, upon investigation this notion is quickly dispelled. Google is showing relevant results because latest news, besides for being the keyword used to bring the above News Box to the SERP, is a category of news listed on many websites.
The first article above is the perfect example. Just looking at the SERP and it seems Google simply interpreted both query and content to provide a relevant result from a reputable site. Below however is a screenshot of the Politico website:
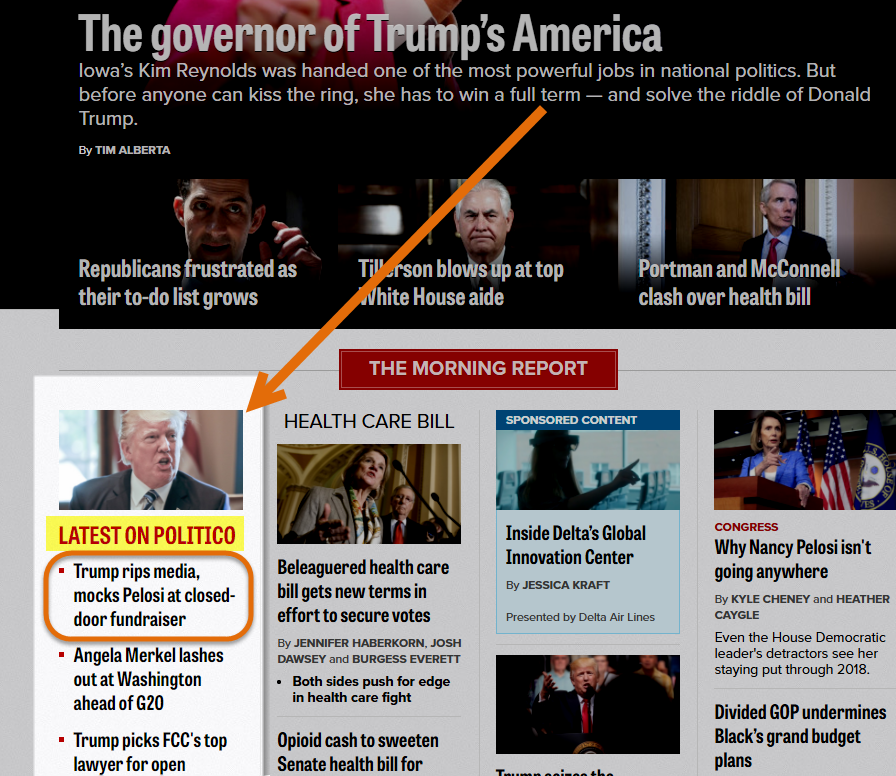
What is of course noteworthy is that the site has a category entitled Latest on Politico. Notice the first article listed within the section, it is the same one Google placed in the News Box. You can bet your bottom dollar that had the following article come first in the order of Politico’s latest news, it would have been placed on the SERP in place of Trump’s ripping of the media and mocking of former Speaker of the House Nancy Pelosi. Simply, Google did not interpret anything. It took the keyword latest, and found that it is a “category of news” on many sites. The search engine then found an authoritative site with the category and simply plopped the first article under the heading into a News Box. No content interpretation ever took place.
Bad News – What This Means for the Fight Against Fake News

Believe it or not, all of the above was set up. Without undertaking the above investigation, the foundational principles needed to understand Google’s ability to fight fake news would be altogether absent. At this point, it should be overwhelmingly clear, Google cannot determine what is, and what is not news content. Instead, it relies on an archaic means of deciphering news content, if you can call it that. In a way, Google is like a blind person stumbling in the dark, feeling around for markers to make it through. Instead of interpreting, Google matches up keywords to titles, and pulls content from news sites, making use of the headings on these sites in order to put together a series of news results for News Box placement. With such an indictment, Google’s ability to fight fake news is directly challenged.
Google Cannot Fight Fake News – No Way No How – Not Yet
I’ll make this simple…. If Google cannot determine what is, and what is not, news content, then by definition it cannot distinguish between fake and genuine news. How can Google claim to be able to adequately fight fake news, when the search engine itself places absurd and entirely irrelevant content within its own News Box? The answer is… it can’t.
Why did I drag you through all of the above examples of poorly filled News Boxes? Simple. To make it abundantly clear that Google cannot qualitatively analyze news content. To show that it uses coarse methods in stocking its own News Box. Nothing highlights this more than the fact that with the absence of a highly specified keyword, Google cannot even interpret the most basic of news queries. How can Google distinguish between fact and fiction, between rumor and evidenced truth when it can’t even comprehend what the day’s most important news stories are, or what news is breaking at the moment?

I don’t mean to be sarcastic, but ask any 5th grader what the important news of the day is and there’s a pretty decent chance you’ll get a relatively satisfactory answer. Ask the most powerful search engine in the world and you get absurd results. If the most basic, and subsequently most foundational news queries are enigmatic to Google, how then can it be expected to delineate between slight shades of truth, with the difference between them being reality and rumor?
The above case-by-case study points towards one truth… Google does not understand the news it is reading and as such intrinsically cannot fight fake news. Not without employing workarounds.
Google’s Methods of Fighting Fake News – Compensating Inadequacy
Google is in a tight spot and to paraphrase one cigar loving President, I feel their pain. It can’t just let fake news fly, and it can’t, due to what appears to be technical limitations, adequately fight it either. So then what did Google do?…. They passed off their very limitations as the best solution in what was a stroke of pure marketing genius. (Again, it’s hard to blame them.) The reality though is that Google’s solution is merely a band-aid fix, at best.

Google’s method of fighting fake news is twofold. The first element being quality raters, who, to the best of my knowledge, are real live people. Why oh why would this tech giant employ the least technologically oriented solution, people? Where are the advanced algorithms? The machine learning? The AI? Nowhere… because it doesn’t exist (at least not in this context), because it’s not yet possible to employ these methods.
Why is Google using boring old people to fight fake news? Because it has no other alternative, because it has no choice. What comes off as sincere dedication to solving the fake news catastrophe is, in reality, an admission of limitation, of not actually being able to discern news content via algorithm.
So too for the second front of the war on fake news. Here, Google has increased its reliance on site authority. Meaning, news results are more likely to come from high authority sites (think NY Times, ABC News, etc.) than your favorite fake news site which lacks such industry authority. While this sounds reasonable, consider it within the context of Google’s inability to analyze news content qualitatively.
Keeping this in mind it becomes apparent why Google has favored site-wide authority over per piece prudence in combating fake news. It is mainly because the latter, a per article content analysis to determine factual accuracy, is seemingly impossible for Google at this stage of the game. It has no choice but to rely on site-wide mechanisms, such as site authority. Yet another workaround.
Not Yet Ready to Headline
The bottom line is that Google can’t directly deal with fake news and its current processes are for all intents and purposes, workarounds. Do these workarounds have potency to them? Sure. Do these workarounds present a true solution to eliminating fake new’s presence from the SERP? No. Unless Google develops a way to combat fake news head-on, via qualitative content analysis, fake news and most certainly irrelevant “news” results will appear on the SERP. Fake news frauds will work their way around Google’s workarounds. If it’s simply a matter of creating headlines with the right words, on the right site, under the right heading, those proliferating fake news will figure it out. There is no way quality raters, who may I remind you have had their hours cut back, will be able to review enough content to effectuate a shift on the SERP. There is simply too much content out there for raters to feed AI with.

Look, at the end of the day, Google’s best efforts are workarounds meant to conceal a lack of a real and true solution. Until Google can fight fake news directly, without shortcuts of sorts, fake news sites will find a way to get their content on the SERP. Until Google can decipher between shades of truth, those in search of truth and nothing but the truth may be left stumbling in the dark a bit.
About The Author
