
Updated: August 28, 2023.
A guide to fixing “Duplicate without user-selected canonical” in Google Search Console.
Seeing the “duplicate without user-selected canonical” status in Google Search Console? This means Google found duplicate content on your site but didn’t index it because no canonical version was specified.
In this guide, I’ll explain exactly what causes this status, how to confirm it’s happening, and most importantly – how to fix it.
You’ll learn:
- What triggers the “duplicate” error in Google Search Console
- How to check for duplicate content yourself
- When duplicate content might not be an issue
- The best ways to tell Google which URL to index
- Steps to consolidate and control duplicate pages
With the right canonical signals, you can take back control and resolve this error for good. Let’s get started!
TL;DR: Duplicate without User-Selected Canonical
“Duplicate without user-selected canonical” is the status in Google Search Console indicating that Google discovered duplicate content on your site but did not index it.
This happens when Google finds multiple identical or very similar pages, but there is no canonical tag or other signal specifying which URL you want indexed as the preferred version.
So Google does not index any version of the duplicate content, since it doesn’t know which one to choose.
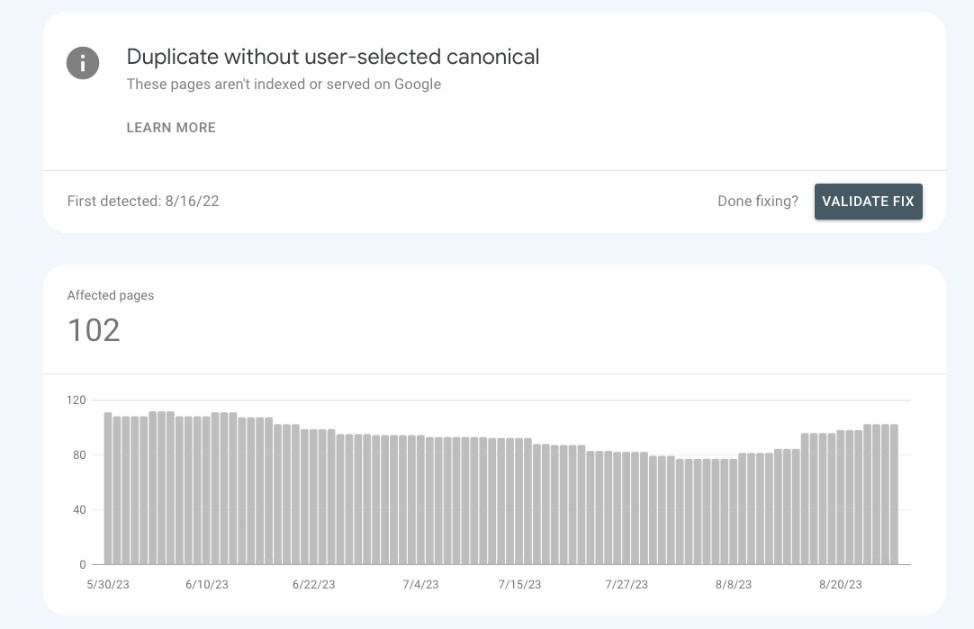
The status means duplicate content was found but no canonical page was selected by you, leaving Google unable to determine which version to include in search results.
When does the “Duplicate without user-selected canonical” error occur?
There are a few key things that can trigger the “Duplicate without user-selected canonical” status to show up in Google Search Console.
Duplicate page content causes “Duplicate without user-selected canonical”
The most common trigger is having identical or very similar content that exists on multiple pages of your site.
For example, an entire blog post that is duplicated across different URLs, product description pages that are copied to different category archives, or a piece of textual content copied to various sections of the site.
Google sees these pages as duplicate versions of the same content. Minor differences like a changed **** won’t make the pages unique in Google’s eyes.
No canonical tags may cause “Duplicate without user-selected canonical”
The duplicate content itself isn’t the only potential issue. The bigger problem is that none of these duplicate pages have canonical tags specifying which URL you want to be indexed.
Canonical tags are HTML elements that let you point to the preferred or “canonical” version of a page.

Without canonical tags guiding Google, it doesn’t know which duplicate page you want indexed, if any.
It means Google will try to make its best guess at what’s the main version of the content which may not be what you intend.
Site migrations and URL structure changes may cause “Duplicate without user-selected canonical”
Major changes to your site’s structure or URLs can also create duplicate content issues.
For example, if you migrate an old domain to a new domain, the old pages may still be crawled, creating duplicates of the new domain’s content.
Changing URL structures like going from .php to .html pages, adding or removing ****-based URLs, or pagination and filtering systems can also lead to pages with the same content but different URLs.
CMS or server issues may also cause “Duplicate without user-selected canonical”
Sometimes technical issues can inadvertently create duplicate pages on your site.
Bugs in your CMS, database errors, issues with caches, mirrors or backups of your site could all lead to duplicate content appearing without your knowledge.
TIP: In essence, any issues that result in the same content appearing on different URLs can lead to the “Duplicate without user-selected canonical” status.
How to check if your site has duplicate content without the canonical tag specified
The first signs of “duplicate without user-selected canonical” will show up in Google Search Console. But there are a few proactive checks you can do to identify duplicate content issues on your site.
Finding “Duplicate without user-selected canonical” in Google Search Console
Finding “Duplicate without user-selected canonical” in Google Search Console is the first place to identify if it exists:
- Navigate to the Indexing > Pages report in your Google Search Console account.
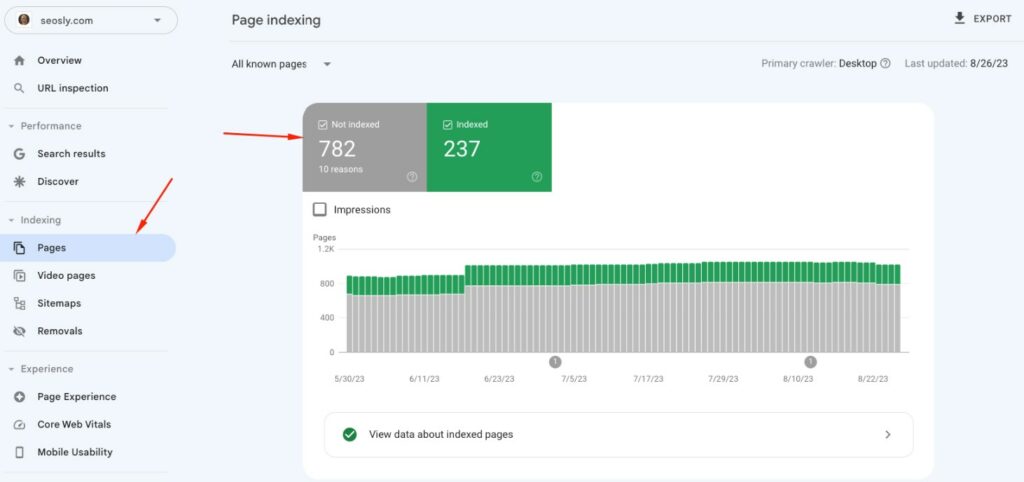
- Under Why pages aren’t indexed, look for Not indexed for the “Duplicate without user-selected canonical” status with Website as the source.
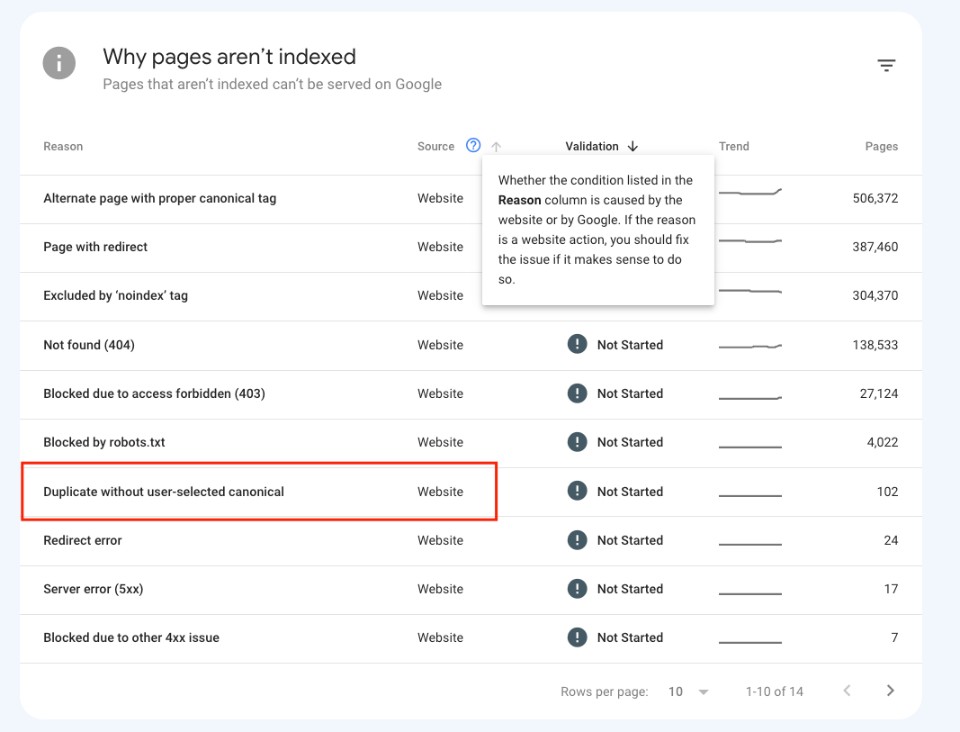
- Click into the error to see a list of all affected URLs Google has discovered.
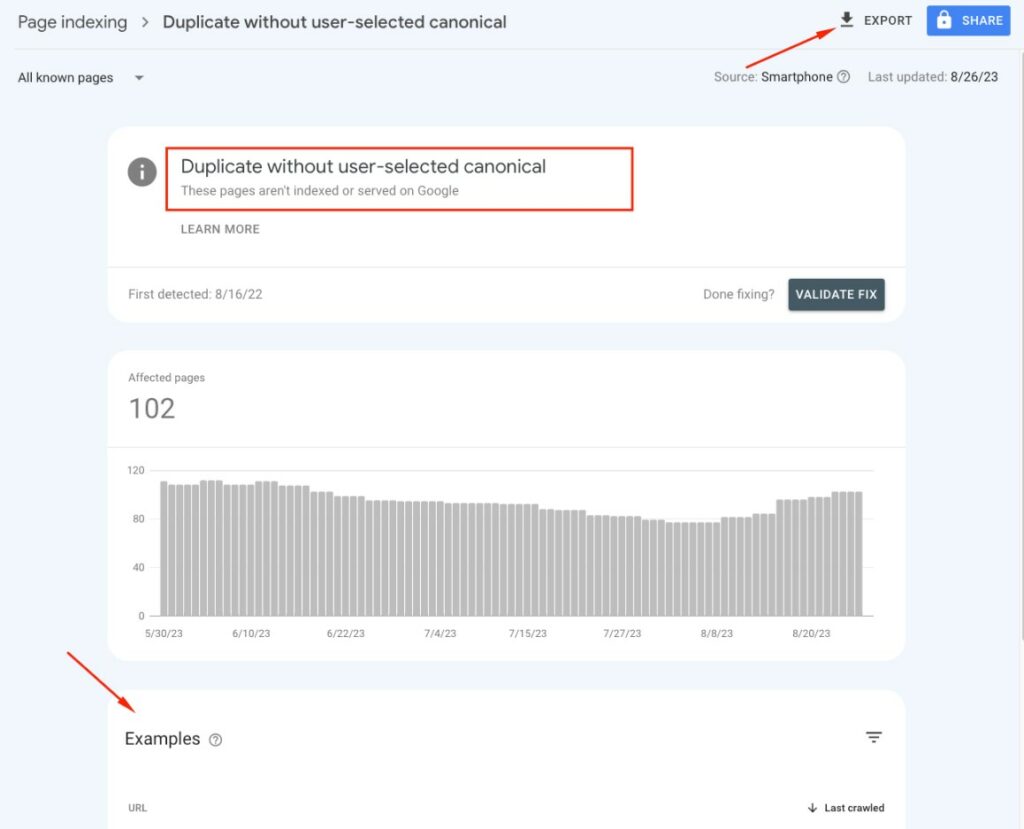
Google URL Inspection
Using Google’s URL Inspection tool allows you to check specific pages and provides a plethora of information in addition to whether the page is classified as “Duplicate without user-selected canonical”:
- Use Google’s URL Inspection tool to paste suspect URLs one by one. You can either paste the URL into the inspection tool or click on the magnifying glass in the list of examples.
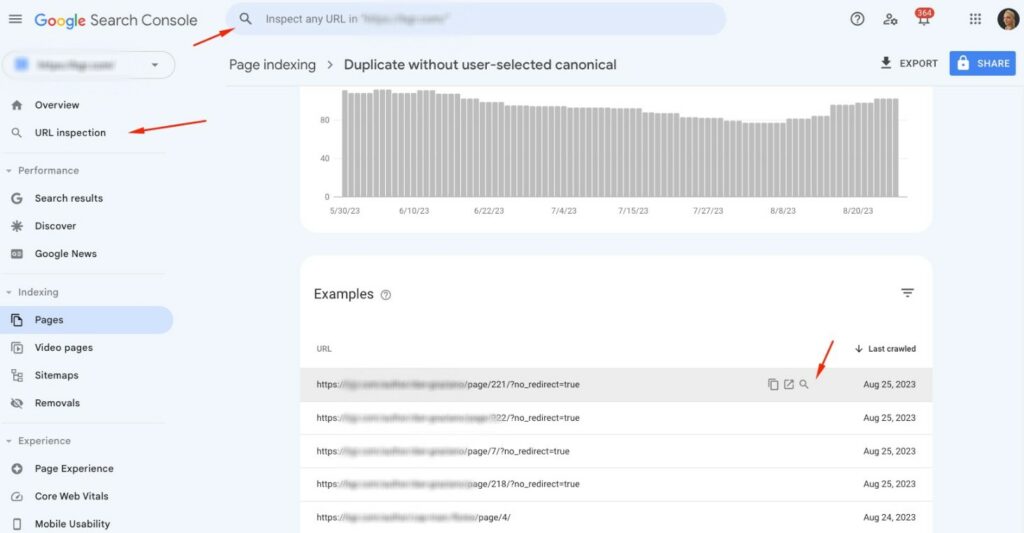
- The report will show you if Google has selected a different canonical URL than what you may have tagged.
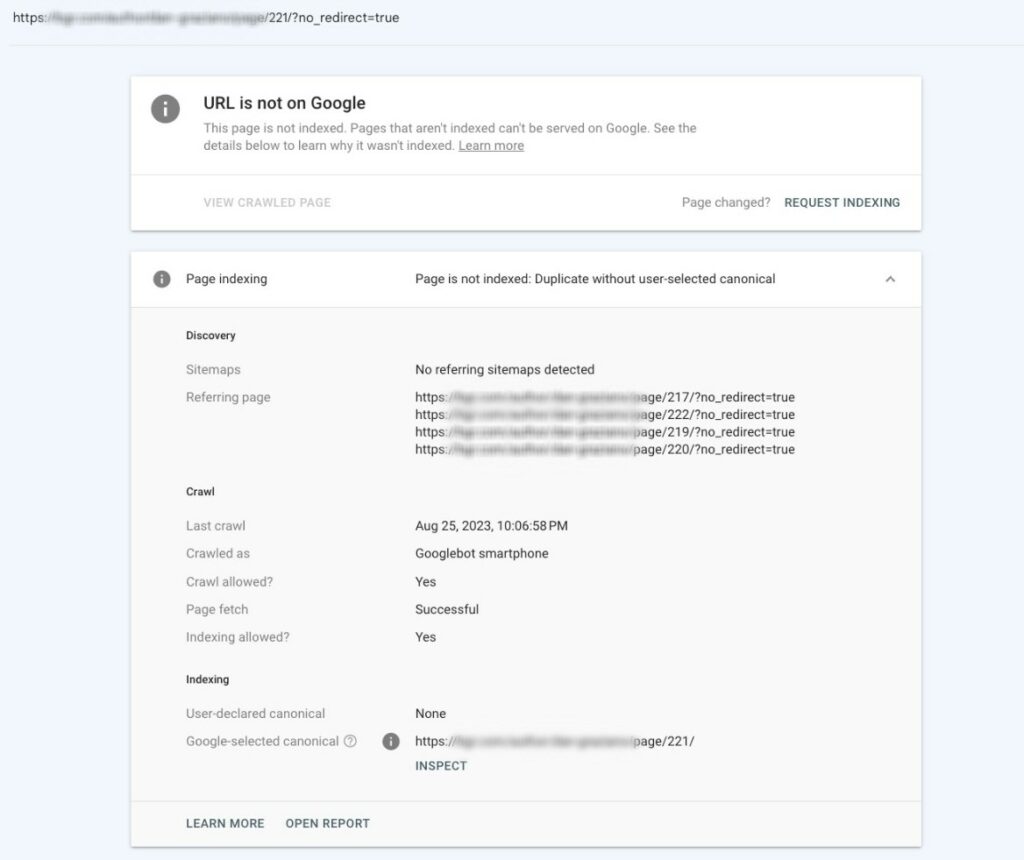
- You can also use the URL Inspection API to do bulk checks on up to 2000 URLs per day.
- The API will return JSON data including any Google selected canonicals.
- This makes it easy to programmatically check large sets of pages for potential issues.
- Tools like JetOctopus also allow you to bulk check URLs to identify duplicate content and canonical issues at scale.
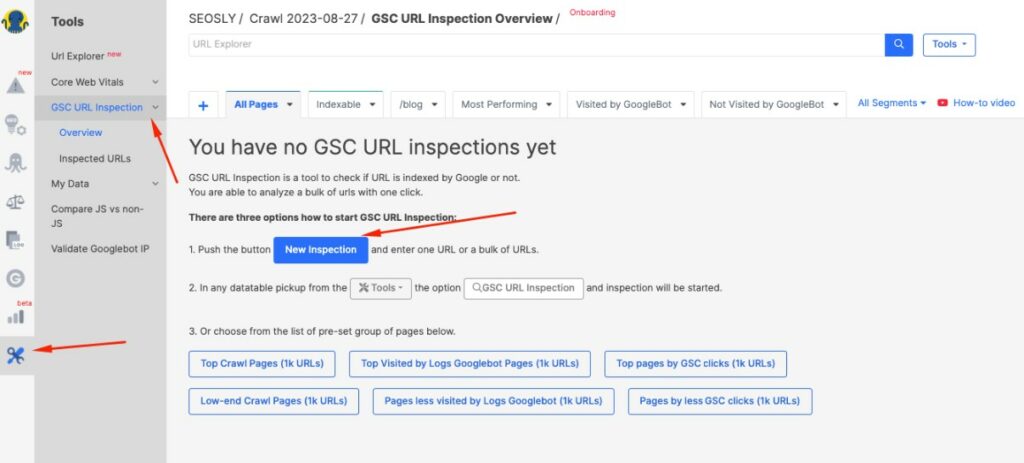
- When in JetOctopus, navigate to Tools > GSC URL Inspection > New Inspection and enter URLs to inspect.
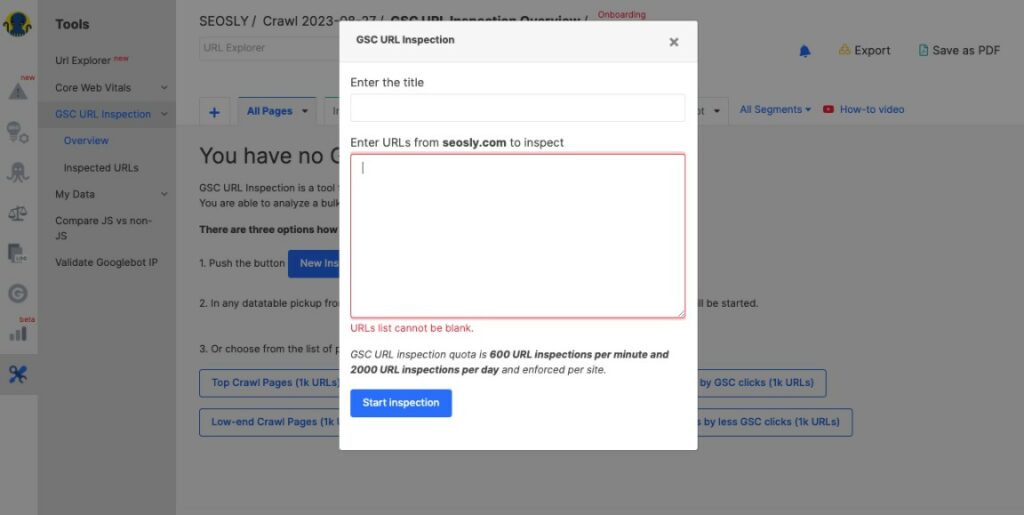
- It’s a fast way to inspect duplicate content across thousands of URLs in your site.
Using bulk inspection tools like the API or JetOctopus which uses API allows you to quickly scan your entire site for potential duplicate content and canonical issues. This helps find problems at scale versus manual checks.
Proactively using site crawlers
Crawling your site proactively with SEO tools can find duplicate content issues:
- Use an SEO crawler tool to crawl your site looking for duplicate title tags and meta descriptions.
- These often indicate pages with duplicate content.
- Site crawlers can identify duplicate pages that may not have been discovered by Google yet, so this is a great preventive method.
- JetOctopus lets you easily find content duplication issues. All you need to do is crawl the site and then navigate to Crawler > Duplication and you will see all the duplication issues your site has.
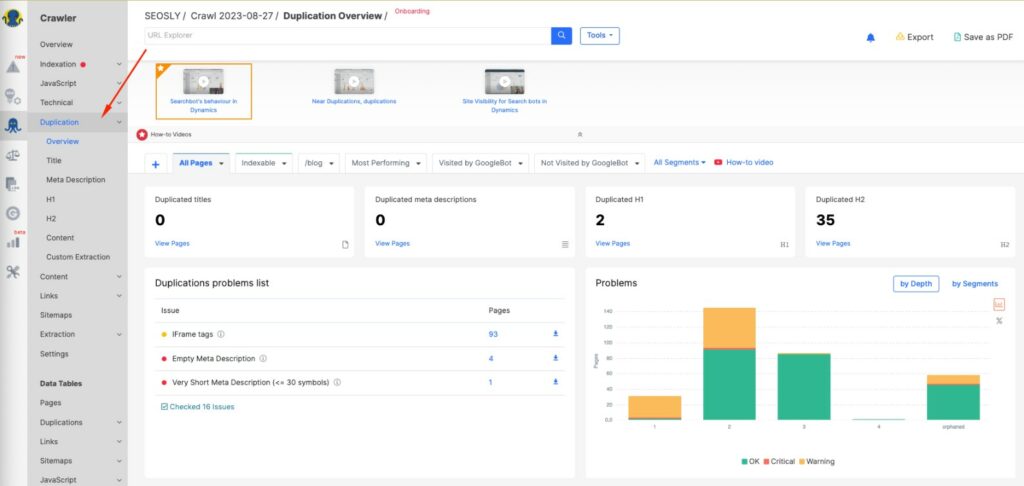
Regularly checking these sources helps you find and fix duplicate content issues before they escalate into indexing errors and problems.
Is “Duplicate without user-selected canonical” always an issue?
NO! Having this pop up in Google Search Console does not mean that this is an issue or error. This is simply one possible status of pages classified as “Not indexed”. Even in its documentation, Google doesn’t call this an “error”.
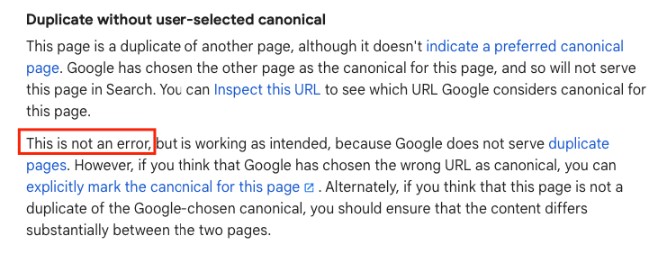
Sometimes having duplicate or very similar content on your site is intentional based on the structure and purpose of your pages.
In certain cases, you may actually want Google to index multiple versions of the same content. For example, an e-commerce site may have the same product content available under different categories or filters and there may be actually people looking for those variations in Google.
In these scenarios, you have a few options:
- Use self-referring canonical tags – These point a page to itself as the canonical version, telling Google you want that specific URL indexed as-is. You can implement a self-referring canonical on each duplicate you want indexed.
- Create unique titles, meta descriptions, images – Make sure each duplicate page has some unique identifying content and metadata so Google sees them as distinct enough to index individually.
- Vary the content slightly – Add some unique text or data to each version so they pass as different pages. This could include updating dates, stats, author info, related posts, etc.
However, in general best practice is still to create distinct, one-of-a-kind content for each new page on your site.
Duplicate content bloats your site with thin pages and can confuse users. So only allow intentional, useful duplicates instead of duplicating all content across your site.
How to fix “Duplicate without user-selected canonical”
When you see the “duplicate without user-selected canonical” status in Google Search Console, it means you need to provide clear signals about your preferred canonical page. Here are some ways to fix it:
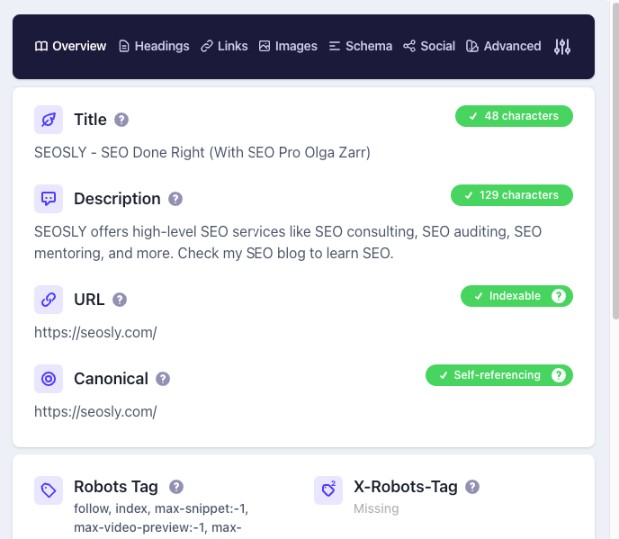
Canonical Tags
Implementing canonical tags is the most direct way to tell Google which duplicate page to index.
- Point canonical tags from all other duplicates to your one preferred page. Use a self-referring canonical on the preferred page.
- For any duplicates you want indexed separately, use self-referring canonicals pointing to themselves.
301 Redirects
If you don’t want users and Google to access the duplicate page, you can simply redirect it to the main page.
- Do permanent 301 redirects from any consolidated duplicate pages to funnel signals like equity and links to the canonical.
- Use redirects when you are specifically removing or consolidating duplicate pages you don’t need indexed anymore.
Adding a “noindex” tag
One way to fix the issue is simply by adding a “noindex” tag to the page Google identified as duplicate (assuming this is not the main version of the content you want indexed and ranked).
- This will not change a lot because Google is already refusing to index the pages showing “Duplicate without user-selected canonical” status.
- However, this may be a good prevention mechanism and a way to have things in technical “order”.
De-duplicating Content
In some cases, you may want to simply address the root cause by removing any unnecessary duplicate content or pages. You can achieve it in those ways:
- Remove duplicate pages and return status code 410 (Gone) if these are not the main versions of the content you want to rank.
- Enrich the duplicated pages so that Google considers them unique. This may involve adding more unique content, changing title tags, meta descriptions, headings, etc. In addition, you also want to add a self-referencing canonical to those pages.
Sitemaps
You can also submit your preferred canonical URL to Google in your XML sitemap. This helps reinforce which version you want indexed. However, this is not a very strong signal.
Best Practices
Here are some best practices to avoid duplicate content problems:
- Have a content strategy to create distinct content for each new page and URL.
- Keep in mind that the canonical tag is a hint, not a directive. Google may still choose to ignore it.
- Implement a site-wide canonical tag strategy to consolidate current duplicates.
- Strengthen your technical SEO to prevent any CMS or backend issues creating duplicates.
- Do ongoing site audits to detect duplicate content issues early before they scale.
- Create unique title tags, meta descriptions, and H1s for every page.
- Avoid scraping content from other sites or repurposing the same internal content too widely.
- Understand proper URL structures and redirects to avoid duplicates during migrations or site architecture changes.
Final thoughts & tips
In summary, “duplicate without user-selected canonical” errors arise when Google discovers duplicate content but you haven’t signaled the preferred URL. Implementing canonical tags is the best way to take back control.
You may even want some duplicates indexed, in which case self-referring canonicals work. But avoid rampant duplication, and focus on creating unique, high-quality content. A solid technical SEO strategy also prevents duplicate issues from ever occurring in the first place.
Hopefully this guide provides a detailed overview of causes, checking for, fixing, and preventing duplicate content problems. Consistently signaling your preferred URLs via canonical tags is key to resolving indexing errors from similar content.