
Celebrate the Holidays with some of SEJ’s best articles of 2023.
Our Festive Flashback series runs from December 21 – January 5, featuring daily reads on significant events, fundamentals, actionable strategies, and thought leader opinions.
2023 has been quite eventful in the SEO industry and our contributors produced some outstanding articles to keep pace and reflect these changes.
Catch up on the best reads of 2023 to give you plenty to reflect on as you move into 2024.
There is a lot of confusion about how SEO pros should both understand and, more importantly, leverage “entities” in SEO.
I understand where this comes from, especially with the traditional approach to SEO being around words and phrases.
Indeed, most of the algorithms that the first wave of SEO pros (like me) grew up with had no concept of an “entity” in search. SEO principals – from content writing to anchor text in links to SERPs tracking – were (and largely still are) keyword-driven, and many people still find it hard to understand what has changed.
But over the last decade, all search has been moving towards understanding the world as a string of words and as a series of interconnected entities.
Working with entities in SEO is the foundation for a future-proof search strategy.
They are also important for a future with generative AI and ChatGPT.
This article talks about why. It covers:
- What are entities?
- What is the Knowledge Graph?
- A brief history of entities in search: Freebase, Wikidata, and entities.
- How entities work and how they are used for ranking.
- Examples of entities in Google.
- How to optimize for entities.
- Using Schema to help define entities.
What Are Entities?
SEOs often confuse entities with keywords.
An entity (in search terms) is a record in a database. An entity generally has a specific record identify.
In Google, that might be:
“MREID=/m/23456” or “KGMID=/g/121y50m4.”
It is certainly not a “word” or “phrase.” I believe that the confusion with keywords stems from two root causes:
- The first is that SEO pros learned their craft pre-2010 in terms of keywords and phrases. Many still do.
- The second is that every entity comes with a label – which is generally a keyword or descriptor.
So while “Eiffel Tower” might seem like a perfectly identifiable “entity” to us as humans, Google sees it as “KGMID=/m/02j81” and really doesn’t care if you call it “Eiffel Tower,” or “ Torre Eiffel,” or “ایفل بورجو” (Which is Azerbaijan for “Eiffel Tower”). It knows that you are probably referring to that underlying entity in its Knowledge Graph.
This comes on to the next point:
What Is “The Knowledge Graph”?
There are subtle but important differences between “a knowledge graph,” “The Knowledge Graph,” and “The Knowledge Panel.”
- A knowledge graph is a semi-structured database containing entities.
- The Knowledge Graph is generally the name given to Google’s Knowledge Graph, although thousands of others exist. Wikidata (itself a knowledge graph) attempts to cross-reference identifiers from different reputable data sources.
- The Knowledge Panel is a specific representation of results from Google’s Knowledge Graph. It is the pane often showing on the right of the results (SERPs) in a desktop search, giving more details about a person, place, event, or other entity.
A Brief History Of Entities In Search
Metaweb
In 2005, Metaweb started to build out a database, then called Freebase, which it described as an “open, shared database of the world’s knowledge.”
I would describe it as a semi-structured encyclopedia.
It gave every “entity” (or article, to extend the metaphor) its own unique ID number – and from there, instead of a traditional article in words, the system tried to connect articles through their relationships with other ID numbers in the system.
Some $50 million dollars in capital funding, and 5 years later, the project was sold to Google.
No commercial product was ever built, but the foundation was set for a 10-year transition, for Google, from a keyword-based search engine to an entity-based one.
Wikidata
In 2016 – some six years after the purchase – Google formally closed down Freebase because it had migrated and developed the ideas into its own “knowledge graph,” the modern term for these databases.
At that time, it is useful to note that Google publicly stated that it had synced much of its entity data with Wikidata and that, moving forward, Wikidata (which underpins the data used in Wikipedia) was one way in which Google’s Knowledge Graph could interface with the outside world.
How Entities Work And How They Are Used For Ranking
Entities In The Core Algorithm
Entities are primarily used to disambiguate ideas, not to rank pages with the same ideas.
That is not to say that clever use of entities can’t help your site’s content rank more effectively. It can. But when Google tries to serve up results to a user search, it aims first and foremost for an accurate answer.
Not necessarily the most deserving.
Therefore, Google spends considerable time converting text passages into underlying entities. This happens both when indexing your site and when analyzing a user query.
For example, if I type in “The names of the restaurants underneath the Eiffel Tower,” Google knows that the searcher is not looking for “names” or the “Eiffel Tower.”
They are looking for restaurants. Not any restaurant, but ones in a specific location. The two relevant entities in this search are “restaurant” in the context of “Champ de Mars, 5 Av. Anatole France, Paris” (The address of the Eiffel Tower).
This helps Google to decide how to blend its various search results – images, Maps, Google businesses, adverts, and organic web pages, to name a few.
Most importantly, for the SEO pro, it is very important for (say) the Jules Verne restaurant’s site to talk about its spectacular view of the Eiffel Tower if it wants Google to recognize that the page is relevant to this search query.
This might be tricky since the Jules Verne restaurant is inside the Eiffel Tower.
Language Agnostic
Entities are great for search engines because they are language-agnostic. Moreover, that idea means that an entity can be described through multiple media.
An image would be an obvious way to describe the Eiffel Tower since it is so iconic. It might also be a speech file or the official page for the tower.
These all represent valid labels for the entity and, in some cases, valid identifiers in other knowledge graphs.
Connections Between Entities
The interplay between entities allows an SEO pro to develop coherent strategies for developing relevant organic traffic.
Naturally, the most “authoritative” page for the Eiffel Tower is likely to be the official page or Wikipedia. Unless you are literally the SEO pro for the Eiffel Tower, there is little that you can do to challenge this fact.
However, the interplay between entities allows you to write content that will rank. We already mentioned “restaurants” and “Eiffel Tower” – but what about “Metro” and “Eiffel Tower,” or “Discounts” and “Eiffel Tower”?
As soon as two entities come into play, the number of relevant search results drops dramatically. By the time you get to “Discounted Eiffel Tower tickets when you travel by Metro,” you become one of just a tiny selection of pages focusing on the juxtaposition between Metro tickets, Eiffel Tower tickets, and discounts.
Many fewer people type in this phrase, but the conversion rate will be much higher.
It may also prove a more monetizable concept for you! (This example is to explain the principle. I do not know if such discounts exist. But they should.)
This concept can be scaled to create exceptionally strong pages by first breaking all the competing pages for a search phrase into a table showing the underlying entities and their relative importance to the main query.
This can then act as a content plan for a writer to build up a new piece of content that is more authoritative than any of the other competing pieces.
So although a search engine may claim that entities are not a ranking factor, the strategy goes to the heart of the philosophy that “If you write good content, they will come.”
Examples Of Entities In Google
Entities In Image Search
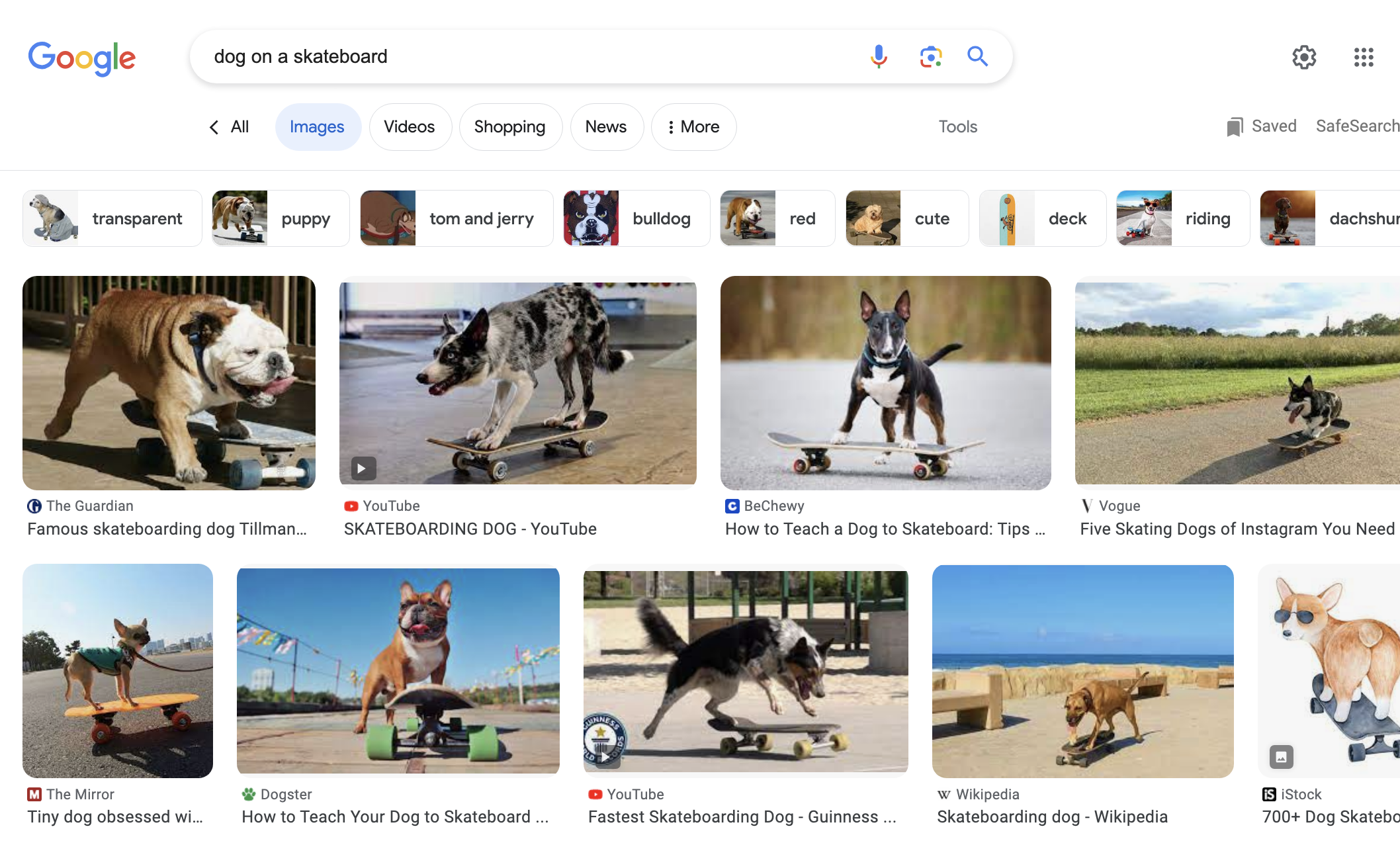 Screenshot from search for [ on a skateboard], Google, August 2023
Screenshot from search for [ on a skateboard], Google, August 2023Entities can also be very helpful in optimizing images.
Google has worked very hard to analyze images using machine learning. So typically, Google knows the main imagery in most photos.
So take [a on a skateboard] as a search term…making sure that your content fully supports the image can help your content be more visible, just when the user is searching for it.
Entities In Google Discover
One of the most underrated traffic sources for SEO professionals is Google Discover.
Google provides a feed of interesting pages for users, even when they are not actively looking for something.
This happens on Android phones and also in the Google app on iPhones. Whilst news heavily influences this feed, non-news sites can get traffic from “Discover.”
How? Well – I believe that entities play a big factor!
 Screenshot from Google Search Console, August 2023
Screenshot from Google Search Console, August 2023Don’t be disheartened if you do not see a “Discover” tab in your Google Search Console. But when you do, it can be a welcome sign that at least one of your web pages has aligned with entities enough that at least one person’s interests overlap with your content enough to have the page in a feed targeted specifically to the user.
In the example above, even though “Discover” results are not displayed at the exact time that a user is searching, there is still a 4.2% click-through rate.
This is because Google can align the interests and habits of many of its users to the content on the Internet by mapping entities.
Where a strong correlation occurs, Google can offer up a page for a user.
How To Optimize For Entities
Some Research From A Googler
In 2014, a paper came out that I find quite helpful in demonstrating that Google (or at least, its researchers) were keen to separate out the ideas of using keywords to understand topics vs. using entities.
In this paper, Dunietz and Gillick note how NLP systems moved towards entity-based processing. They highlight how a binary “salience” system can be used on large data sets to define the entities in a document (webpage).
A “binary scoring system” suggests that Google might decide that a document either IS or ISN’T about any given entity.
Later clues suggest that “salience” is now measured by Google on a sliding scale from 0 to 1 (for example, the scoring given in its NLP API).
Even so, I find this paper really helpful in seeing where Google’s research thinks “entities” should appear on a page to “count” as being salient.
I recommend reading the paper for serious research, but they list how they classified “salience as a study of ‘New York Times’ articles.”
Specifically, they cited:
1st-loc
This was the first sentence in which a mention of an entity first appears.
The suggestion is that mentioning the entity early in your web page might increase the chances of an entity being seen as “salient” to the article.
Head-count
This is basically the number of times the “head” word of the entity’s first mention appears.
“Head word” is not specifically defined in the article, but I take it to mean the word concatenated to its simplest form.
Mentions
This refers not just to the words/labels of the entity, but also to other factors, such as referrals of the entity (he/she/it)
Headline
Where when an entity appears in a headline.
Head-lex
Described as the “lowercased head word of the first mention.”
Entity Centrality
The paper also talks about using a variation of PageRank – where they switched out web pages for Freebase articles!
The example they shared was a Senate floor debate involving FEMA, the Republican Party, (President) Obama, and a Republican senator.
After applying a PageRank-like iterative algorithm to these entities and their proximity to each other in the knowledge graph, they were able to change the weightings of the importance of those entities in the document.
Putting These Entity Signals Together In SEO
Without being specific to Google, here, an algorithm would create values for all the above variables for every entity that an NLP or named entity extraction program (NEEP) finds on a page of text (or, for that matter, all the entities recognized in an image).
Then a weighting would be applied to each variable to give a score. In the paper discussed, this score turns into a 1 or 0 (salient or not salient), but a value from 0-1 is more likely.
Google will never share the details of those weightings, but what the paper also shows is that the weightings are determined only after hundreds of millions of pages are “read.”
This is the nature of large language learning ******.
But here are some top tips for SEO pros who want to rank content around two or more entities. Returning to the example “restaurants near the Eiffel Tower”:
- Decide on a “dead” term for each entity. I might choose “restaurant,” “Eiffel Tower,” and “distance” because distance has a valid meaning and article in Wikipedia. Cafe might be a suitable synonym for restaurant, as might “restaurants” in the plural.
- Aim to have all three entities in the header and first sentence. For example: “Restaurants a small distance from the Eiffel Tower.”
- Aim in the text to talk about the inter-relationship between these entities. For example: “The Jules-Verne restaurant is literally inside it.” Assuming “it” clearly refers to the Eiffel Tower in the context of the writing, it does not need to be written out every time. Keep the language natural.
Is This Enough For Entity SEO?
No. Probably not. (You are welcome to read my book!) However, not all factors are in your control as a writer or website owner.
Two ideas that do seem to have an impact, though, are linking content from other pages in context and adding schema to help with the definitions.
Using Schema To Help Define Entities
Further clarity might be given to search engines by using the “about” and “mentions” schema to help a search engine disambiguate content.
These two schema types help to describe what a page is talking about.
By making a page “about” one or two entities and “mentions” of maybe a few more, an SEO professional can quickly summarize a long piece of content into its key areas in a way that is ready-made for knowledge graphs to consume.
It should be noted, though, that Google has not expressly stated one way or another whether it uses this schema in its core algorithms.
I would probably add this schema to my article:
<script type=”application/ld+json”> {
“@context”: “https://schema.org”,
“@type”: “WebPage”,
“@id”: “https://www.yoursite.com/yourURL#ContentSchema”,
“headline”: “Restaurants a small distance from the Eiffel Tower”,
“url”: “https://www.yoursite.com/yourURL”,
“about”: [
{“@type”: “Thing”, “name”: “Restaurant”, “sameAs”: “https://en.wikipedia.org/wiki/Restaurant”},
{“@type”: “Place”, “name”: “Eiffel Tower”, “sameAs”: “https://en.wikipedia.org/wiki/Eiffel_Tower”}
],
“mentions”: [
{“@type”: “Thing”, “name”: “distance”, “sameAs”: “https://en.wikipedia.org/wiki/Distance”},
{“@type”: “Place”, “name”: “Paris”, “sameAs”: “https://en.wikipedia.org/wiki/Paris”}
]
} </script>
The exact choice of schema is as much a philosophical question as an SEO question.
But think of the schema you use as “disambiguating” your content rather than “optimizing your content,” and you will hopefully end up with more targeted search traffic.
Editor’s note: Dixon Jones is the author of Entity SEO: Moving from Strings to Things.
More resources:
Featured Image: optimarc/Shutterstock
Source link : Searchenginejournal.com