
Embeddings are essential in the fields of natural language processing (NLP) and machine learning because they convert words and phrases into numerical vectors. By successfully capturing semantic linkages and contextual meanings, these vectors help machines comprehend and process human language. We will examine the idea of embeddings in this blog, learn about their uses, and investigate how to create and incorporate them using Azure Cognitive Search.
Organizations can create advanced search solutions using Azure Cognitive Search which is an effective cloud-based search and AI service. Additionally, the ****** from OpenAI and the revolutionary powers of embeddings make it more precise and efficient.
Word, phrase, or document embeddings are multi-dimensional vector representations that capture semantic meaning and contextual relationships. Embeddings detect complexity that conventional approaches frequently miss by mapping words onto numerical vectors in a dense vector space. Similar words are placed closer together in this area, allowing algorithms to comprehend and compare textual material more effectively.
Sentiment analysis, recommendation engines, semantic search, and many other uses are applications of embeddings.
https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
We are required to generate embeddings initially, followed by sending these embeddings to Azure Cognitive Search. This enables Azure Cognitive Search to leverage the embeddings, thereby enhancing its effectiveness.
Generating embeddings involves utilizing pre-trained ****** or training custom ****** on specific datasets. OpenAI’s API provides endpoints for generating embeddings as follows:
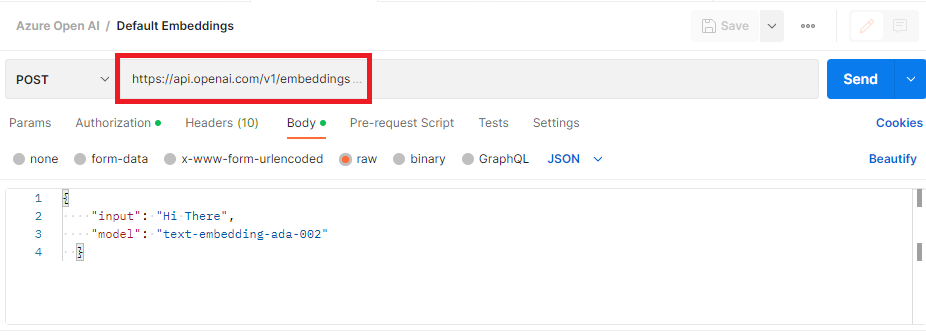
API: https://api.openai.com/v1/embeddings: The default endpoint from OpenAI for generating embeddings without deployment-specific information.
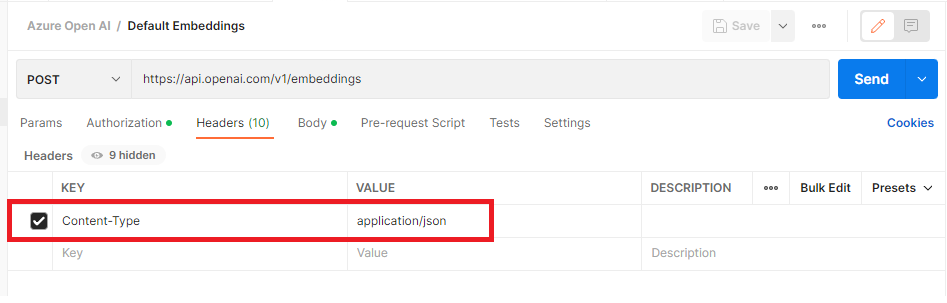
Headers:
Content-Type: application/json
Authorization: Bearer your-openai-api-key
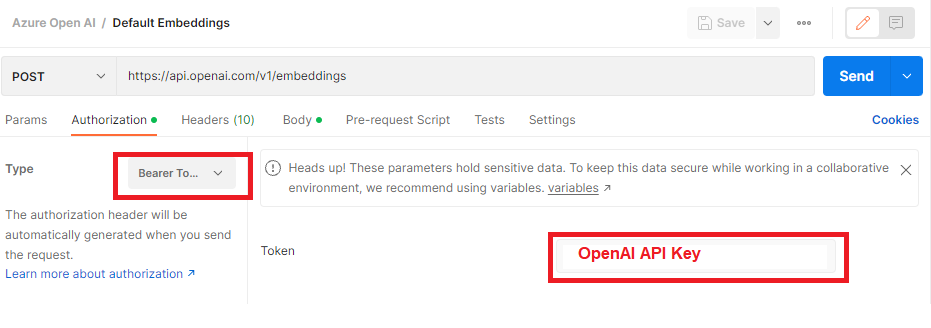
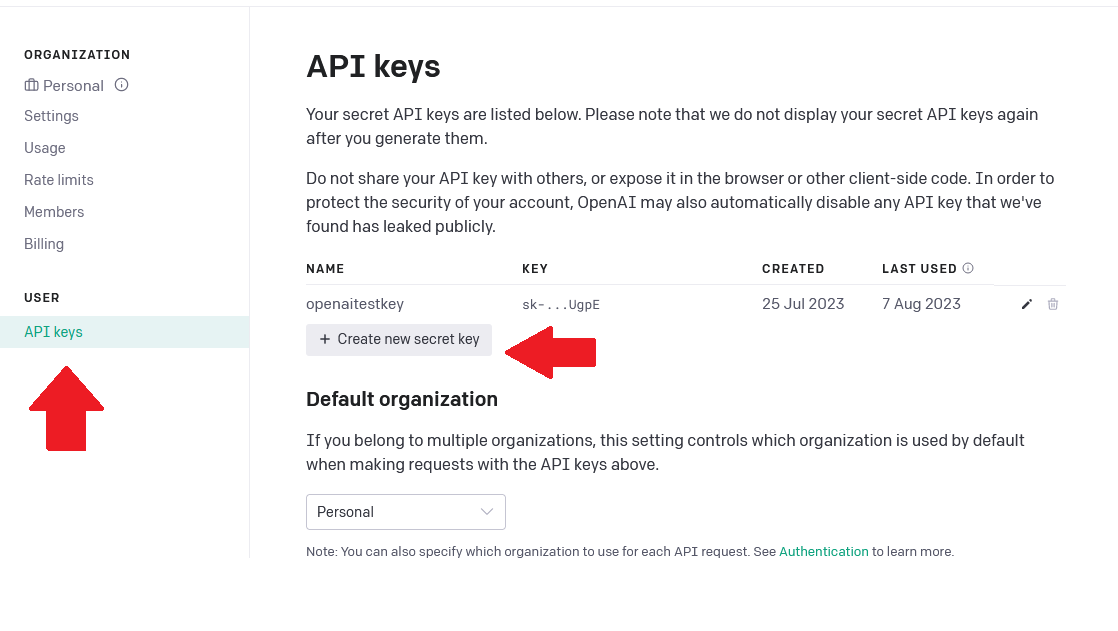
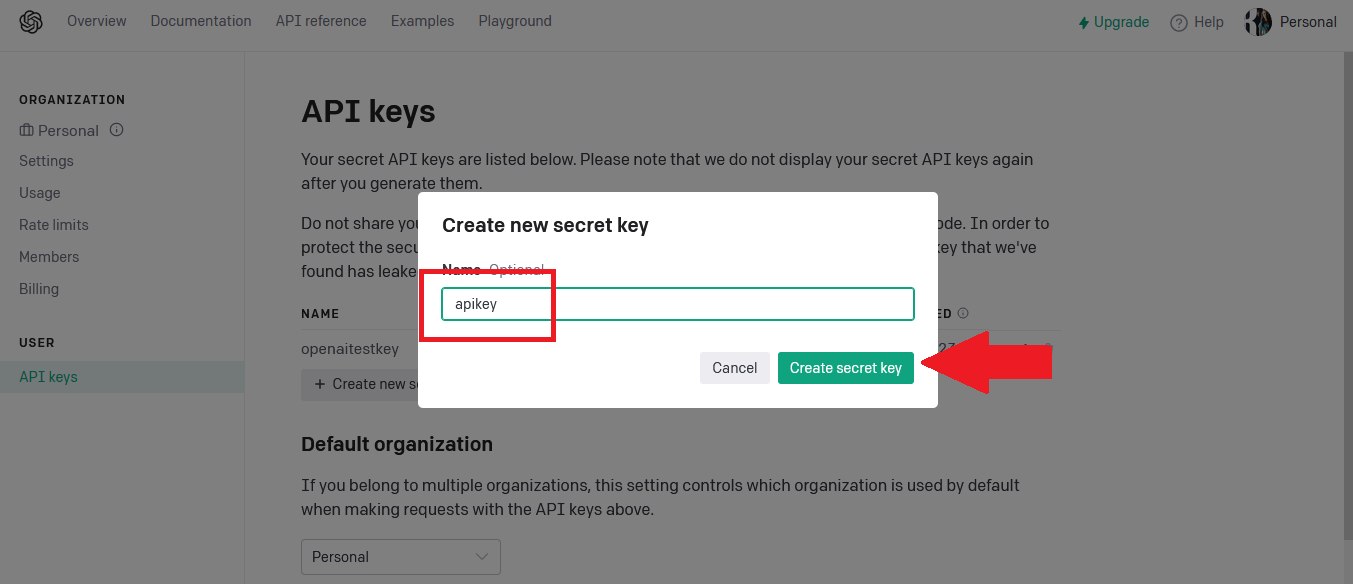
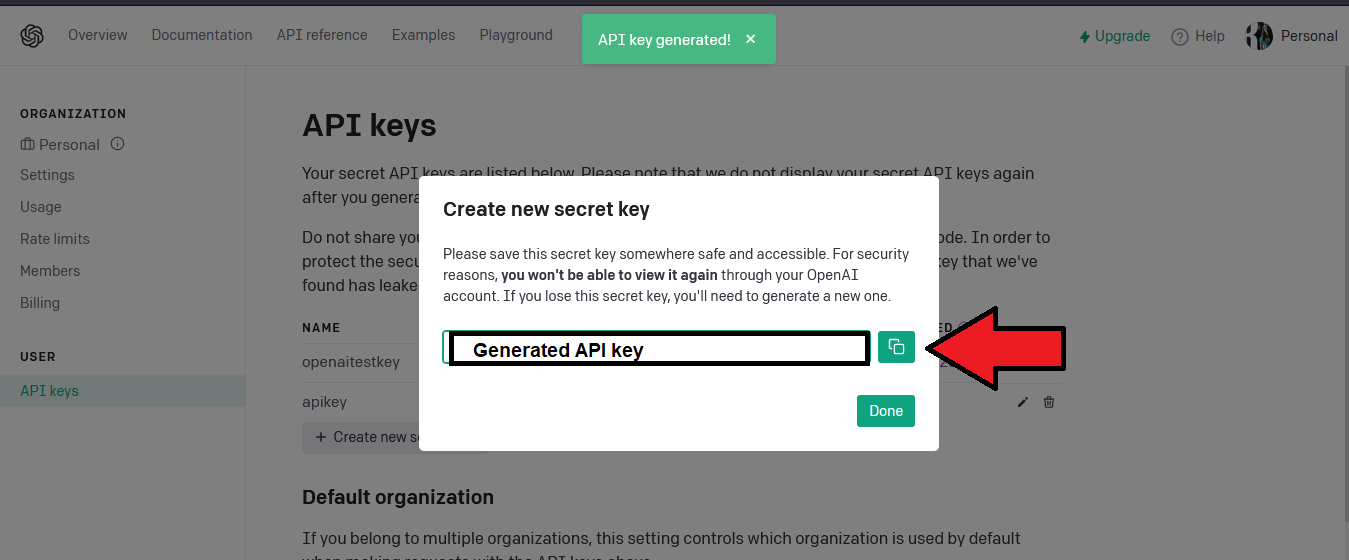
Navigate to below URI to generate OpenAI API key:
https://platform.openai.com/account/api-keys
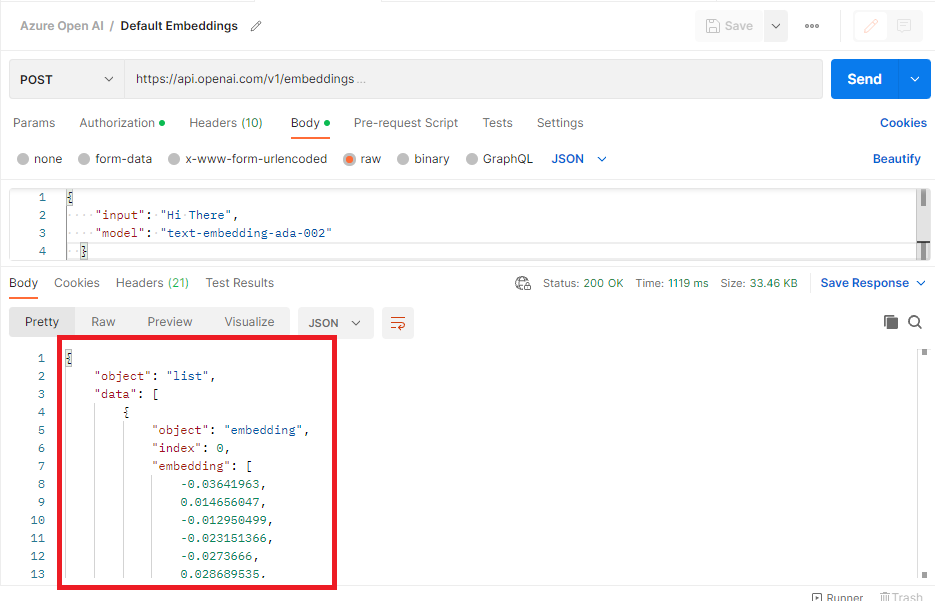
The complete response object, that contains these embeddings, is in json is given as follows:
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.022749297,
0.018456243,
-0.0120750265,
0.013086683,
-0.0018012022……
]
}
],
"model": "text-embedding-ada-002-v2",
"usage": {
"prompt_tokens": 2,
"total_tokens": 2
}
}
The size of the generated embeddings is around 1024 floats total for ADA.
“1024 floats total for Ada” likely means that when using the ADA model in the context of Azure OpenAI embeddings, each text embedding is represented as a vector with 1024 floating-point values, which collectively make up the embedding for the given text.
The input text for our embedding ****** must not exceed 2048 tokens, which is approximately equivalent to 2-3 pages of text. Please ensure that your inputs are within this limit before initiating a request.
As you keep going, we can incorporate these generated embeddings into search solutions, you’re not only improving the search experience with these embeddings but also taking a significant step toward advancement.
Embeddings are like special tools that help connect what we say and what computer understand. These tools uses special codes to capture the meaning of words and how they fit together, making it easier for computers to figure out what we mean. In this blog, we’ve seen how to generate these embeddings using OpenAI service.
These embeddings are super useful for making search results better, understanding how people express from their search words, suggesting things you might like, and helping search engines understand what you’re looking for.