
Google announced a remarkable ranking framework called Term Weighting BERT (TW-BERT) that improves search results and is easy to deploy in existing ranking systems.
Although Google has not confirmed that it is using TW-BERT, this new framework is a breakthrough that improves ranking processes across the board, including in query expansion. It’s also easy to deploy, which in my opinion, makes it likelier to be in use.
TW-BERT has many co-authors, among them is Marc Najork, a Distinguished Research Scientist at Google DeepMind and a former Senior Director of Research Engineering at Google Research.
He has co-authored many research papers on topics of related to ranking processes, and many other fields.
Among the papers Marc Najork is listed as a co-author:
- On Optimizing Top-K Metrics for Neural Ranking ****** – 2022
- Dynamic Language ****** for Continuously Evolving Content – 2021
- Rethinking Search: Making Domain Experts out of Dilettantes – 2021
- Feature Transformation for Neural Ranking ****** – – 2020
- Learning-to-Rank with BERT in TF-Ranking – 2020
- Semantic Text Matching for Long-Form Documents – 2019
- TF-Ranking: Scalable TensorFlow Library for Learning-to-Rank – 2018
- The LambdaLoss Framework for Ranking Metric Optimization – 2018
- Learning to Rank with Selection Bias in Personal Search – 2016
What is TW-BERT?
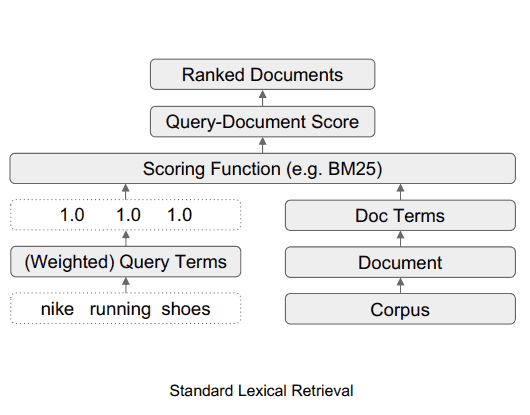
TW-BERT is a ranking framework that assigns scores (called weights) to words within a search query in order to more accurately determine what documents are relevant for that search query.
TW-BERT is also useful in Query Expansion.
Query Expansion is a process that restates a search query or adds more words to it (like adding the word “recipe” to the query “chicken soup”) to better match the search query to documents.
Adding scores to the query helps it better determine what the query is about.
TW-BERT Bridges Two Information Retrieval Paradigms
The research paper discusses two different methods of search. One that is statistics based and the other being deep learning ******.
There follows a discussion about the benefits and the shortcomings of these different methods and suggest that TW-BERT is a way to bridge the two approaches without any of the shortcomings.
They write:
“These statistics based retrieval methods provide efficient search that scales up with the corpus size and generalizes to new domains.
However, the terms are weighted independently and don’t consider the context of the entire query.”
The researchers then note that deep learning ****** can figure out the context of the search queries.
It is explained:
“For this problem, deep learning ****** can perform this contextualization over the query to provide better representations for individual terms.”
What the researchers are proposing is the use of TW-Bert to bridge the two methods.
The breakthrough is described:
“We bridge these two paradigms to determine which are the most relevant or non-relevant search terms in the query…
Then these terms can be up-weighted or down-weighted to allow our retrieval system to produce more relevant results.”
Example of TW-BERT Search Term Weighting
The research paper offers the example of the search query, “Nike running shoes.”
In simple terms, the words “Nike running shoes” are three words that a ranking algorithm must understand in the way that the searcher intends it to be understood.
They explain that emphasizing the “running” part of the query will surface irrelevant search results that contain brands other than Nike.
In that example, the brand name Nike is important and because of that the ranking process should require that the candidate webpages contain the word Nike in them.
Candidate webpages are pages that are being considered for the search results.
What TW-BERT does is provide a score (called weighting) for each part of the search query so that it makes sense in the same way that it does the person who entered the search query.
In this example, the word Nike is considered important, so it should be given a higher score (weighting).
The researchers write:
“Therefore the challenge is that we must ensure that Nike” is weighted high enough while still providing running shoes in the final returned results.”
The other challenge is to then understand the context of the words “running” and “shoes” and that means that the weighting should lean higher for joining the two words as a phrase, “running shoes,” instead of weighting the two words independently.
This problem and the solution is explained:
“The second aspect is how to leverage more meaningful n-gram terms during scoring.
In our query, the terms “running” and “shoes” are handled independently, which can equally match “running socks” or “skate shoes”.
In this case, we want our retriever to work on an n-gram term level to indicate that “running shoes” should be up-weighted when scoring.”
Solving Limitations in Current Frameworks
The research paper summarizes traditional weighting as being limited in the variations of queries and mentions that those statistics based weighting methods perform less well for zero-shot scenarios.
Zero-shot Learning is a reference to the ability of a model to solve a problem that it has not been trained for.
There is also a summary of the limitations inherent in current methods of term expansion.
Term expansion is when synonyms are used to find more answers to search queries or when another word is inferred.
For example, when someone searches for “chicken soup,” it’s inferred to mean “chicken soup recipe.”
They write about the shortcomings of current methods:
“…these auxiliary scoring functions do not account for additional weighting steps carried out by scoring functions used in existing retrievers, such as query statistics, document statistics, and hyperparameter values.
This can alter the original distribution of assigned term weights during final scoring and retrieval.”
Next, the researchers state that deep learning has its own baggage in the form of complexity of deploying them and unpredictable behavior when they encounter new areas for which they were not pretrained on.
This then, is where TW-BERT enters the picture.
TW-BERT Bridges Two Approaches
The solution proposed is like a hybrid approach.
In the following quote, the term IR means Information Retrieval.
They write:
“To bridge the gap, we leverage the robustness of existing lexical retrievers with the contextual text representations provided by deep ******.
Lexical retrievers already provide the capability to assign weights to query n-gram terms when performing retrieval.
We leverage a language model at this stage of the pipeline to provide appropriate weights to the query n-gram terms.
This Term Weighting BERT (TW-BERT) is optimized end-to-end using the same scoring functions used within the retrieval pipeline to ensure consistency between training and retrieval.
This leads to retrieval improvements when using the TW-BERT produced term weights while keeping the IR infrastructure similar to its existing production counterpart.”
The TW-BERT algorithm assigns weights to queries to provide a more accurate relevance score that the rest of the ranking process can then work with.
Standard Lexical Retrieval
Term Weighted Retrieval (TW-BERT)
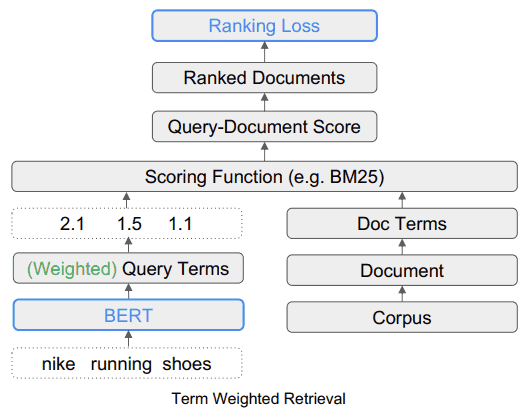
TW-BERT is Easy to Deploy
One of the advantages of TW-BERT is that it can be inserted straight into the current information retrieval ranking process, like a drop-in component.
“This enables us to directly deploy our term weights within an IR system during retrieval.
This differs from prior weighting methods which need to further tune a retriever’s parameters to obtain optimal retrieval performance since they optimize term weights obtained by heuristics instead of optimizing end-to-end.”
What’s important about this ease of deployment is that it doesn’t require specialized software or updates to the hardware to add TW-BERT to a ranking algorithm process.
Is Google Using TW-BERT In their Ranking Algorithm?
As mentioned earlier, deploying TW-BERT is relatively easy.
In my opinion, it’s reasonable to assume that the ease of deployment increases the **** that this framework could be added to Google’s algorithm.
That means Google could add TW-BERT into the ranking part of the algorithm without having to do a full scale core algorithm update.
Aside from ease of deployment, another quality to look for in guessing whether an algorithm could be in use is how successful the algorithm is in improving the current state of the art.
There are many research papers that only have limited success or no improvement. Those algorithms are interesting but it’s reasonable to assume that they won’t make it into Google’s algorithm.
The ones that are of interest are those that are very successful and that’s the case with TW-BERT.
TW-BERT is very successful. They said that it’s easy to drop it into an existing ranking algorithm and that it performs as well as “dense neural rankers”
The researchers explained how it improves current ranking systems:
“Using these retriever frameworks, we show that our term weighting method outperforms baseline term weighting strategies for in-domain tasks.
In out-of-domain tasks, TW-BERT improves over baseline weighting strategies as well as dense neural rankers.
We further show the utility of our model by integrating it with existing query expansion ******, which improves performance over standard search and dense retrieval in the zero-shot cases.
This motivates that our work can provide improvements to existing retrieval systems with minimal onboarding friction.”
So that’s two good reasons why TW-BERT might already be a part of Google’s ranking algorithm.
- It’s an across the board improvement to current ranking frameworks
- It’s easy to deploy
If Google has deployed TW-BERT, then that may explain the ranking fluctuations that SEO monitoring tools and members of the search marketing community have been reporting for the past month.
In general, Google only announces some ranking changes, particularly when they cause a noticeable effect, like when Google announced the BERT algorithm.
In the absence of official confirmation, we can only speculate about the likelihood that TW-BERT is a part of Google’s search ranking algorithm.
Nevertheless, TW-BERT is a remarkable framework that appears to improve the accuracy of information retrieval systems and could be in use by Google.
Read the original research paper:
End-to-End Query Term Weighting (PDF)
Google Research Webpage:
End-to-End Query Term Weighting
Featured image by Shutterstock/TPYXA Illustration
Source link : Searchenginejournal.com