
What is a Knowledge Graph?
A knowledge graph is a reusable data layer that serves as a collection of relationships between things, defined using a standardized vocabulary.
It provides a structured framework from which new knowledge can be gained through inferencing, allowing for the exploration and understanding of complex relationships within diverse datasets.
The goal in any form of marketing is one of communication: you want to communicate your information to the world. To connect with the right people at the right time and through the right channel, your content needs to be properly understood.
This is hard enough to do successfully between people, but it becomes even more difficult when machines become conduits for this information.
Not only must we anticipate the needs and interests of our audience, but this information needs to be translated into a machine-readable, processable, and searchable format.
Industry Use Cases for Knowledge Graphs
If you’re familiar with the concept, it’s probably due to Google’s Knowledge Graph which popularized the term in 2012. However, knowledge graphs have proven to be valuable across various industries beyond the scope of SEO.
Social Media Sites
Meta constructed its own network of interconnected data points from publicly available information on their social platforms. These data points represent real-world entities and their relationships, creating a graph encompassing people, interests, activities, and more.
For example, when a user clicks the “Like” button on Facebook, this information is represented in the form of triples about that user. In the context of a knowledge graph, these triples consist of Subject-Predicate-Object relationships. If a user likes a particular movie (Object), the triple could be (User – Likes – Movie).
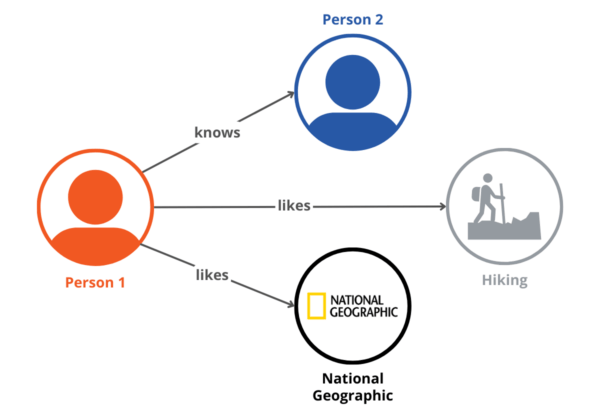
These triples expand the knowledge graph, creating new connections between users and their interests, activities, and affiliations. By analyzing the generated triples, Facebook gains insights into users’ interests, hobbies, preferences, and social connections.
As an example, if a user likes multiple posts related to hiking, the platform understands the user’s interest in outdoor activities. With this enriched knowledge graph, Facebook can personalize users’ experiences. Users see content in their feeds that aligns with their interests, creating a more engaging experience.
Advertisers can leverage this data to target specific demographics based on their interests and behaviours.
Cultural Heritage Institutions
Cultural heritage institutions, including galleries, libraries, archives, and museums, grapple with the daunting task of managing vast amounts of unstructured, semi-structured, and structured data that is stored in silos. The absence of efficient applications to manage this information often leads to manual efforts in collecting and processing this data, resulting in high labour costs and outdated information.
To address these challenges, cultural heritage researchers are turning to knowledge graphs as an innovative and dynamic solution. The following illustration showcases a digital cultural heritage management project that has constructed a knowledge graph using data from the Chinese Palace Museum.
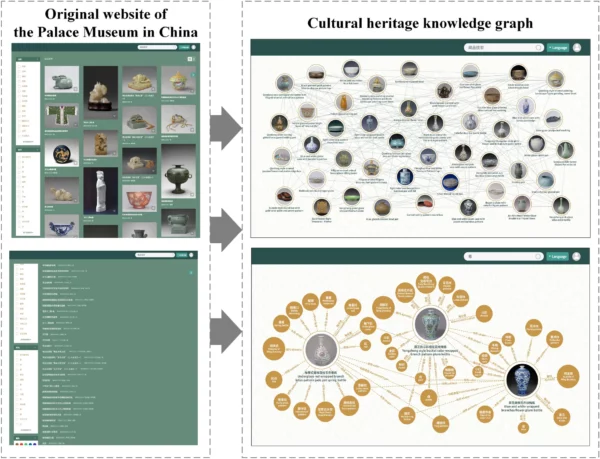
Heritage Science Journal, 2023
Additionally, the integration of deep learning algorithms with these knowledge graphs further refines digital cultural heritage management, enhancing visualization capabilities and making it more intelligent and cohesive. These systems working in tandem is one example of the relationship between knowledge graphs and AI.
Enterprises
Enterprises like large consulting firms have harnessed the power of knowledge graphs to optimize information management. With vast networks of consultants, sometimes in the hundreds of thousands, they often face the challenge of matching the right expert to specific projects.
A specific consulting firm with 300,000 consultants, partnered with SemanticArts to create a knowledge graph detailing each consultant’s specialization, industry experience, skills, and availability. To streamline access to this data, SemanticArts also prototyped a chat service to leverage the knowledge in the graph database.
This is only one example of knowledge graphs being used to standardize and unify information for a chat service. Chatbots act as translators, allowing users to query knowledge graphs in natural language, rather than having to learn graph query languages like SPARQL. This seamless integration of knowledge graphs and chatbots not only enhances internal processes but also exemplifies the potential of this technology in modern enterprises.
With the introduction of LLMs, many enterprises are also exploring how knowledge graphs can be used to ground them to provide accurate and efficient information to users on their sites.
Google’s Knowledge Graph
Arguably the most well-known use case, Google’s Knowledge Graph began with Freebase, a project started by Metaweb in 2007. Freebase was a huge collection of structured data described as “synapses for the global brain.” It became a significant linked open data project in 2008.
Google acquired Freebase in 2010, incorporating this extensive knowledge base into its proprietary Knowledge Graph. Upon releasing their knowledge graph, Google introduced the concept of “strings not things”, announcing their pivot from lexical, keyword-based search, to semantic search.
Google continued to maintain Freebase before giving its content to the Wikidata community in 2014. When Freebase became read-only in 2015, it held over 3 billion facts about nearly 50 million entities.
Google embraced the knowledge graph to harness the intricate connections between entities on the web, adding crucial context to web data.
Knowledge Panels: Google’s Knowledge Graph Brought to Life
Now that you know the history and purpose of Google’s knowledge graph, it’s important to be able to identify how this information is presented in search. Enter – Google’s Knowledge Panel.
The Knowledge Panel is the box that appears on the right side of the search results page when you search for well-known entities (celebrities, businesses, landmarks, etc.).
The Knowledge Panel provides a snapshot of information about the entity you searched for, sourced from Google’s Knowledge Graph. It offers a quick overview, including key facts, images, links to official websites, and sometimes interactive elements like maps or social media profiles.
For example, here is our co-founder, Mark van Berkel’s knowledge panel.
In essence, Google’s Knowledge Graph is the extensive database that powers the Knowledge Panel. It is a compilation of information from one or more pages that presents answers to search queries in the rich results, enhanced SERP results, and knowledge panels we’ve come to associate with authoritative and trusted content.
Even on a smaller scale, organizing data and establishing clear connections between entities is vital for search engines and machines to understand your content.
The good news is that you, too, can manage your content and entities as a knowledge graph for better search engine comprehension. By doing so, you can increase the likelihood of earning a knowledge panel for your business to build authority in search.
However, before you dive into this journey, it’s essential to implement semantic Schema Markup and establish your content’s entities.
The Semantic Building Blocks of a Knowledge Graph
To form a knowledge graph, your content (i.e. plain text, images, etc.) needs to be available in machine-readable code. In the context of SEO, this code is represented by the Schema.org vocabulary.
This informal ontology, of over 840 types and 20+ properties per type, can be applied to web content in the form of Microdata, RDFa, or JSON-LD. Once applied, it is expressed as Schema Markup, and enables machines to understand information about your content and differentiate between things, like local businesses and products.
Moreover, properties can be added to each Type to provide further context to this data. Does the local business serve a specific area? Does the product come in different sizes or colours?
This is information that users were querying about mostly by way of keywords, or “strings”. Schema.org’s ability to define and connect information would turn data into a graph of things and transform the capabilities of search in the process.
Schema.org’s vocabulary has allowed unstructured content (i.e. text, images, etc) to be understood as distinct entities. This provides the foundation upon which knowledge graphs are built.
Developing Your Knowledge Graph
By using this markup to then develop your knowledge graph, you are establishing semantic relationships between not only your own content, but to external databases, adding more context to your content.
Developing your own knowledge graph enhances your organization’s ability to manage and utilize its data efficiently, facilitating informed decision-making processes. It also significantly improves user experience by enabling accurate and personalized search results that are directly aligned with user queries. This can lead to more targeted and quality traffic engaging with your site.
But, most exciting of all, is that a knowledge graph promotes interoperability among different data sources and systems, fostering innovation and enabling the development of new products, services, or insights for your organization.
As search is shifting toward AI-powered systems, this innovative approach is becoming increasingly important to stay ahead.
The Knowledge Graph Process
Learning to implement Schema Markup is much like learning another language, one that allows your web content to be understood by machines. Every time you mark up a thing on your page, you are asserting that this thing exists and defining how it relates to other things in the world.
This approach is foundational to the development of a knowledge graph, illustrated in the Data, Information, Knowledge, Wisdom (DIKW) Pyramid below. This hierarchy of information and insight shows that enriching data with context and connection is essential. The more we do so, the more inference and wisdom can be drawn from it.
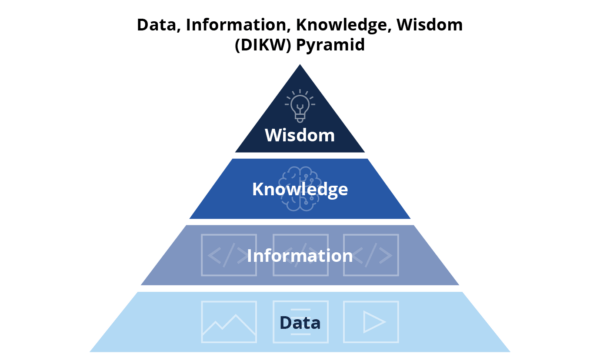
Data
Whether you’re running an automotive business, a medical office, or a software company, if you have an online presence, you have data. You may have internal data like sales and inventory, and external data like the content on your website. Your content contains data about the products or services provided, location information, and blog content that demonstrates your areas of expertise.
Data is raw and simple, and in this state often lacks semantic significance.
Information
However, simply creating content is not enough. Machines have a harder time interpreting plain texts or images than most humans.
Without structuring this data about your business, machines struggle to interpret it accurately. To bridge the gap between human understanding and machine comprehension, it’s crucial to structure your data to transform it into machine-readable information.
This is where an ontology, like Schema.org, comes in. By applying the Schema.org vocabulary to your data, it becomes structured and subsequently has the potential to become connected. Data becomes information when it is related to other data. For example, the text “Mark van Berkel” on its own is a data point, but it doesn’t give us useful information.
But if the Schema.org vocabulary were used to express that Mark van Berkel is the name of a Person who knows about Semantic Technology and the Semantic Web, and is the founder of Schema App, this provides useful information about the entity Mark van Berkel as an entity that machines can more readily comprehend.
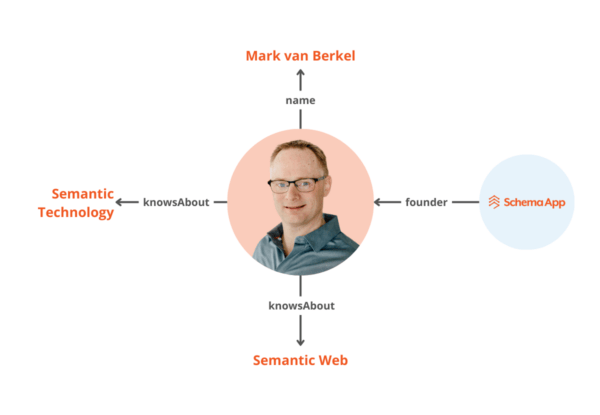
Finding which information to connect to other information can be tricky. This is another factor we take into account in our tools. Because of our background in semantic technologies, we are passionate about connecting your content.
This is why we developed the Schema Paths Tool to simplify the process and save time. The Schema Paths tool provides different pathways for how two entities on your site might connect using the Schema.org properties and types.
By simply inserting the two Types you want to connect, you can see every possible predicate to connect them. You can then choose the one that most appropriately articulates their relationship in the knowledge graph of your content.
Knowledge
However, applying an ontology can only get you so far.
In an interview with Steve Macbeth of Microsoft, he notes that “Semantics without the ability to connect to other data is almost as valueless as no semantics…[S]emantic data [is] only valuable in my opinion when it can be bridged to other data.”
This encompasses the “Knowledge” portion of this process, which further evolves the information that has been distinguished within your content. It represents a collection of information that is useful, typically in the form of triples connected to other triples. This essentially builds a knowledge graph by connecting it to other knowledge graphs.
All of these connections represent contextual information about a particular topic. For example, we can express that Mark knowsAbout the Semantic Web by connecting his knowledge graph to Semantic Web, which is an entity defined by Wikidata.
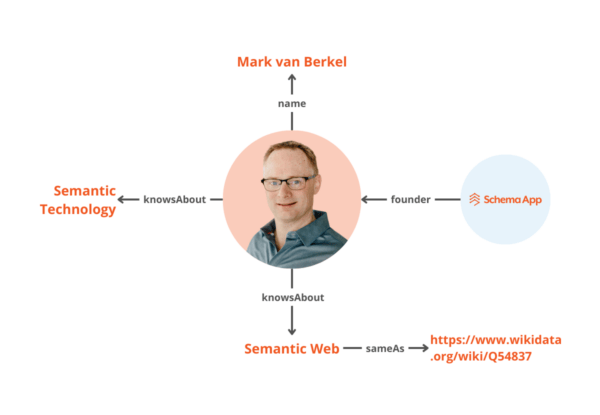
By linking to other knowledge graphs like Wikidata, we can be more explicit with machines about our information so that they can disambiguate the information about the entity. Your content can inform and be informed by other structured data on the web.
Thanks to this collaborative effort, new knowledge may be inferred and accessed through semantic search.
Wisdom
Wisdom, in this sense, takes existing knowledge derived from knowledge graphs and uses it to make inferences, actionable insights, and educated assumptions to generate new knowledge.
Unlike data and information, which reflect the past, wisdom guides present actions and future aspirations, emphasizing the practical application of knowledge.
What Can You Do With a Knowledge Graph
The versatility of knowledge graphs provides limitless flexibility in their applications. Despite being a longstanding concept, various industries continue to leverage knowledge graphs as foundational frameworks for organizing information for many different use cases.
Ground LLMs
If you want to deploy an AI chatbot to assist your customers, it’s critical that it provides accurate information every time. The problem, however, is that LLMs can’t fact-check like humans do. They respond to queries based on patterns and probabilities, sometimes resulting in incorrect or fabricated responses, known as “hallucinations.”
This means the AI needs to understand specific things about your business, like what you sell and how things are related, to give the right answers to customers. Businesses can address this challenge by utilizing their own knowledge graph, containing accurate information about their products or services, to train the AI chatbot effectively.
Analyze Your Content
Formatting and structuring your content in the form of a knowledge graph allows you to categorize and quantify your content library and identify gaps. It also enables a deeper level of analysis to answer questions like:
- Which schema.org Types are used most often?
- How many entities are identified on each page?
- How many properties are being used?
- How much of your content is being marked up?
Your knowledge graph can also be used to easily assess your content qualitatively, by answering questions such as:
- How do your entities compare to the search terms you’re targeting with your content?
- Are you linking to entities from external authoritative knowledge bases? If so, which ones?
- Are there any missing that should be present considering your area of expertise?
Improve Search
By understanding the relationships between different entities, knowledge graphs enable search engines to offer more relevant results and simplify information discovery for users. They enhance navigation with related links and suggested searches, making it easier for visitors to find what they need.
At Schema App, we’ve been implementing semantic Schema Markup and entity linking to help customers develop their knowledge graph. By having a knowledge graph, search engines can better match your page to a user search query. This drives more qualified traffic and increases click-through rates (CTR).
The Importance of Knowledge Graphs in SEO
Knowledge graphs establish semantic relationships between different pieces of information. They enhance the overall user experience and credibility of a website, which are also factors considered by search engines in their ranking algorithms. By leveraging knowledge graphs, websites can enhance their SEO efforts, leading to increased organic traffic and improved online presence.
For SEO purposes, knowledge graphs are invaluable for delivering precise, tailored search results that go beyond just the string of words typed into search. Empowered by knowledge graphs, search engines can now infer context around a query and fill in gaps that would otherwise remain limited to the keywords used in the query.
This deeper comprehension ensures highly relevant search results, increasing the likelihood of user clicks and qualified traffic, and ultimately boosting CTR for relevant pages.
Developing your own marketing knowledge graph is essential for optimizing your semantic SEO strategy. It helps in preparing your content for the future of search and driving meaningful traffic to your pages.
Interested in developing your own marketing knowledge graph for your organization but don’t know where to start? Schema App takes care of the technical aspects so that you can take full advantage of what structured data can do without getting mired in the weight of the work.
Contact our team today to get started.

Jasmine is the Product Enablement Lead at Schema App. Schema App is an end-to-end Schema Markup solution that helps enterprise SEO teams create, deploy and manage Schema Markup to stand out in search.