
Yes, the AI wave brought me back to a challenging period in my career. It took me back to my junior developer days when I did not know much about software architecture, best practices, or fixing performance issues. After approximately 7 or 8 years, that sense of uncertainty returned. I was unsure where to start, and where to find information, and most importantly, I lacked the support of my co-workers, many of whom had already faced the challenges of junior developers. The AI development wave felt eerily like those days. Fortunately, I had been in such situations before, and my experience as a senior developer with leadership skills greatly helped.
Instead of being the rookie, I now led a team of interns into this new AI-driven world. After months of exhaustive research into the rapidly evolving AI technologies – which were popping like popcorn every day – we finally built a strong foundation. However, we still needed real-world use cases, not just abstract ideas that led nowhere.
Putting all the pieces together
Once we had developed what I consider a robust understanding of AI capabilities, we began collaborating closely with the project managers and stakeholders. We set realistic yet somewhat ambitious goals and tasks. Drawing from my experiences with the current project, we found a pain point where AI could work. Our Talent Fulfillment team had struggled to locate the ideal candidate when a client requested a resource. As you may know, Perficient is a consultancy company with a business model that focuses on matching the best candidate with the best client as fast as possible.
Our Current Situation and Desired Destination
Current Situation
For years, we had been relying on our homemade, old-school search tool to find the best match for a client’s position. Users entered keywords like technologies, certifications, or any other relevant terms in the search bar. This search scanned through our employees’ resumes in our database, after retrieving the results, we used a simple algorithm to sort them. Employees with more matches in their job experience field took precedence, followed by those with expertise in technologies and other resume fields. However, after a few months of using this tool, we realized it was not ideal.
For example, the search results lacked information about employee availability or current assignments. More importantly, the tool struggled to interpret project job descriptions. This often left our Talent Fulfillment team confused about the meaning of new technologies, which, in our rapidly evolving industry, emerged every six months or even sooner.
Years passed, and our team grew accustomed to this search engine. While it served its purpose to some extent, it still required manual checks for employee availability and a deep understanding of client job descriptions. The job descriptions themselves varied greatly, featuring new technologies, typos, year-of-experience requirements, soft skills criteria, and factors related to their natural language, such as the way each person expresses themselves. In conclusion, searches for the right candidate could sometimes take days.
Where We Want to Be
Fast forward to 2022, and we have resolved the issue of employee availability and status. Relying on AI, we started finding solutions. The options were abundant. We explored everything from training our own ****** based on existing ones to delving into the world of vector databases, which we heard about for the first time then. This stage brought me back to my junior developer days when everything was new and unfamiliar. New AI tools were popping up left and right, and we struggled to comprehend how they worked and which ones suited our needs.
After months of research and testing various concepts, we made a major decision to combine two AI technologies: vector databases and the GPT-3.5 model. The next part gets a little technical, so do not be alarmed if you miss a detail or two.
The Technical Aspect
Remember the main goal: “Find the best candidate for the client’s job description as quickly as possible.“
For this technical part, let’s consider this example of a job description the Talent Fulfillment team may receive:
“Hi Team! We are looking for a JavaScrip (notice typo) Front-end Lead Developer with over 5 years of experience who has led and mentored junior and senior developers. This candidate should also be capable of making informed decisions based on client requirements and maintaining constant communication with business analysts, product owners, and quality assurance professionals to ensure the team’s optimal performance. If they have knowledge of relational databases and have worked with React or Vue.js as a front-end framework, that would be a plus.”
Let’s analyze this job description. As you can see:
- It contains grammar errors.
- It is written in natural language.
- It mentions several technologies.
Now, imagine the Talent Fulfillment team attempting to search for a candidate for this position. They would first have to identify the technologies. Let’s assume they can extract the terms “JavaScrip” (with a typo), “React,” “Vue.js,” and “Relational Database” from the text. After copying and pasting these keywords into our current search tool and executing the search, the results may yield a good candidate. However, it is not guaranteed to be the best.
First, there is the issue of the search missing developers with “JavaScrip” skills due to the typo. Second, many candidates do not include the term “Relational Database” on their resumes; instead, they mention “SQL” or “MySQL.” As a result, the search might not provide the best results.
In conclusion, executing the search may yield results, but it might not guarantee the best candidates. The search could miss potential candidates due to spelling errors. Furthermore, many candidates use different terms, such as “SQL” or “MySQL,” instead of “Relational Database” in their resumes.
Now, let’s take a look at the new solution:
- Users no longer need to extract keywords from the job description; they only have to copy and paste the entire job description. The AI search will handle the rest.
- With vector databases, the AI understands context better and delivers improved results. It considers years of experience, skills such as “leading and mentoring,” and more complex aspects.
- This AI system with vector databases can identify typos and make more accurate matches. For example, even if the job description says “Javascrip” with a typo, the search will find “JavaScript.”
- Finally, with the GPT model, we can provide more comprehensive results, including an overview of each employee who appears in the final results.
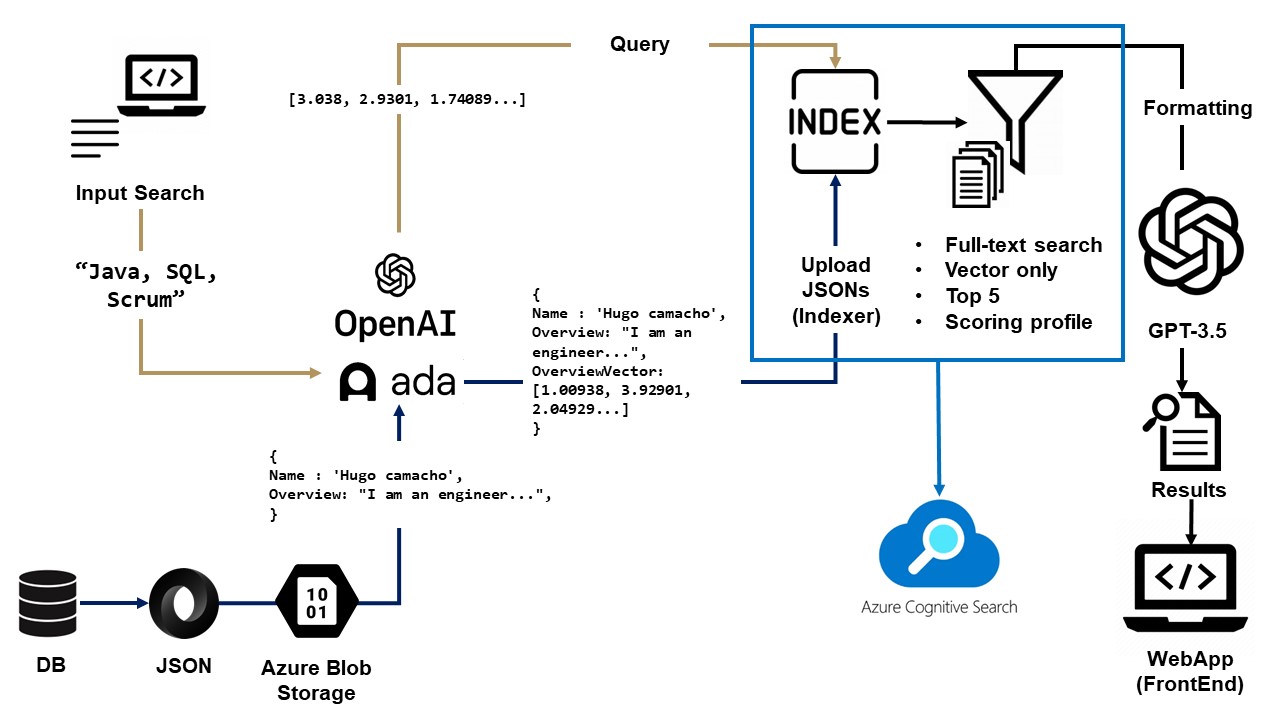
How We Developed This Solution (Small diagram at the end)
- We began by creating our vector databases using the existing information we had. A vector represents a way a computer can understand natural language or any type of text with context (it can also understand audio and images). If you want to see how this might look, consider this text: “A developer with experience in making team decisions and mentoring developers in the front-end part of the project.” In vector form, it might look like this: [-12341, 0.412341, 5132.15412, 1.45123, -0.5123123], with many more numbers, typically up to around 1,300 dimensions.
- How do we create these vector representations of text? We utilize the ADA GPT 3.5 Model, which is a pre-trained model by OpenAI. In technical terms, we have a Python code that uses the embedding function. For each section of an employee’s resume that has context, like the job description, we run this function and save it as a vector.
- The result is a JSON file for each employee’s resume, comprising regular text and vectors. Imagine a developer’s resume, which contains certifications, technologies, or skills; these sections remain as regular text. We vectorize only sections with context, such as job descriptions and experiences.
- Next, we upload these new JSON files to an index, which is a key-value pair “table” stored in Azure Cognitive Search. This index serves as our primary search engine and where we execute all our queries. To give you an idea of how cutting-edge our technology is, Azure introduced the capability to store vector databases in June 2023.
- In the final step, we execute the query. Because we are querying an index with vectorized fields, we first need to convert our plain query text to vectors. Using Azure Cognitive Search’s power, we run a hybrid search. It initially performs a traditional keyword search in plain text. Subsequently, it runs a vectorized search, followed by algorithms that deliver the best results possible. Et voila!
In Conclusion
Yes, it has been a while since I felt this level of uncertainty, not knowing what to expect or if we could meet even the basic expectations. But with my years of experience, I can confidently say that I approached these new challenges more effectively (obviously haha), thanks to my supportive team. I must emphasize that my team’s main forces are interns with immense dedication, and this journey would not have been possible without their hard work. We are learning new things week by week and continually fine-tuning our search results. At the same time, we realized that our approach to the solutions is not the only one or the best one, it is the one that currently fits best. With this mindset, we are well aware that there is always room for improvement. It has been an incredible ride, and from what I can see, it is far from over. Now, we eagerly await input from our Talent Fulfillment team. This tool was designed to help them and enhance their job, and I am eager to hear their feedback and strive to deliver a better product with each release.
If you have read through this entire article, I really appreciate it and if you have more technical or non-technical questions, please do not hesitate to reach out to me. I will be more than happy to provide a deeper explanation.