
What Is the Google Index?
The Google index is a database of all the webpages the search engine has crawled and stored to use in search results.
It acts like a massive, searchable library of web content. And stores the text from each webpage, along with important metadata like titles, headers, links, images, and more.
All of this data gets compiled into a structured index that allows Google to instantly scan its contents and match search queries with relevant results.
So when users search for something in Google, they’re searching its powerful index to find the best webpages on that topic.
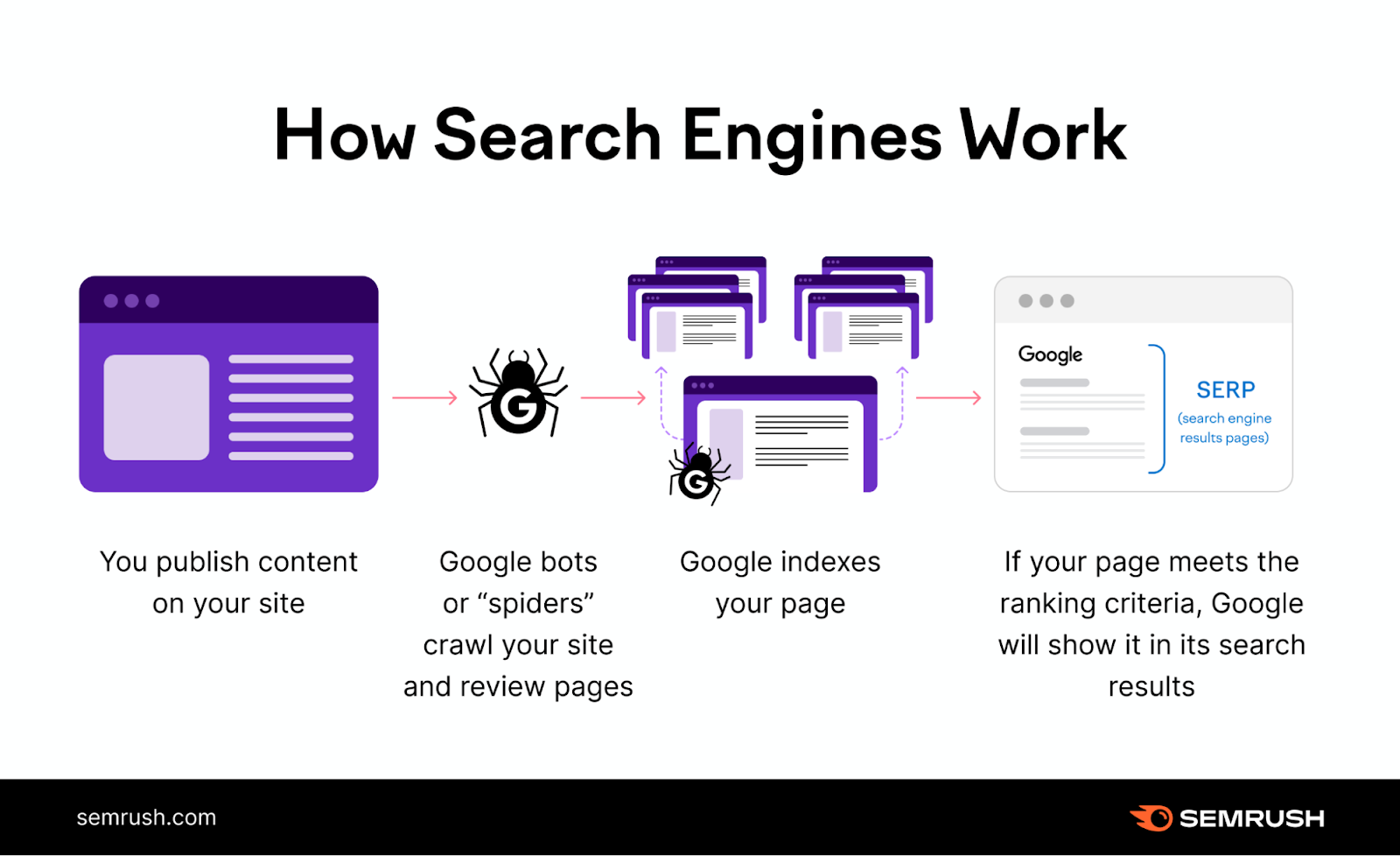
Every page that appears in Google’s search results has to be indexed first. If your page isn’t indexed, it won’t show in search results.
Here’s how indexing fits into the whole process (assuming there aren’t issues along the way):
- Crawling: Googlebot crawls the web and looks for new or updated pages
- Indexing: Google analyzes the pages and stores them in its database
- Ranking: Google’s algorithm picks the best and most relevant pages from its index and shows them as search results
Predetermined algorithms control Google indexing. But there are things you can do to influence indexing.
How Do You Check If Google Has Indexed Your Site?
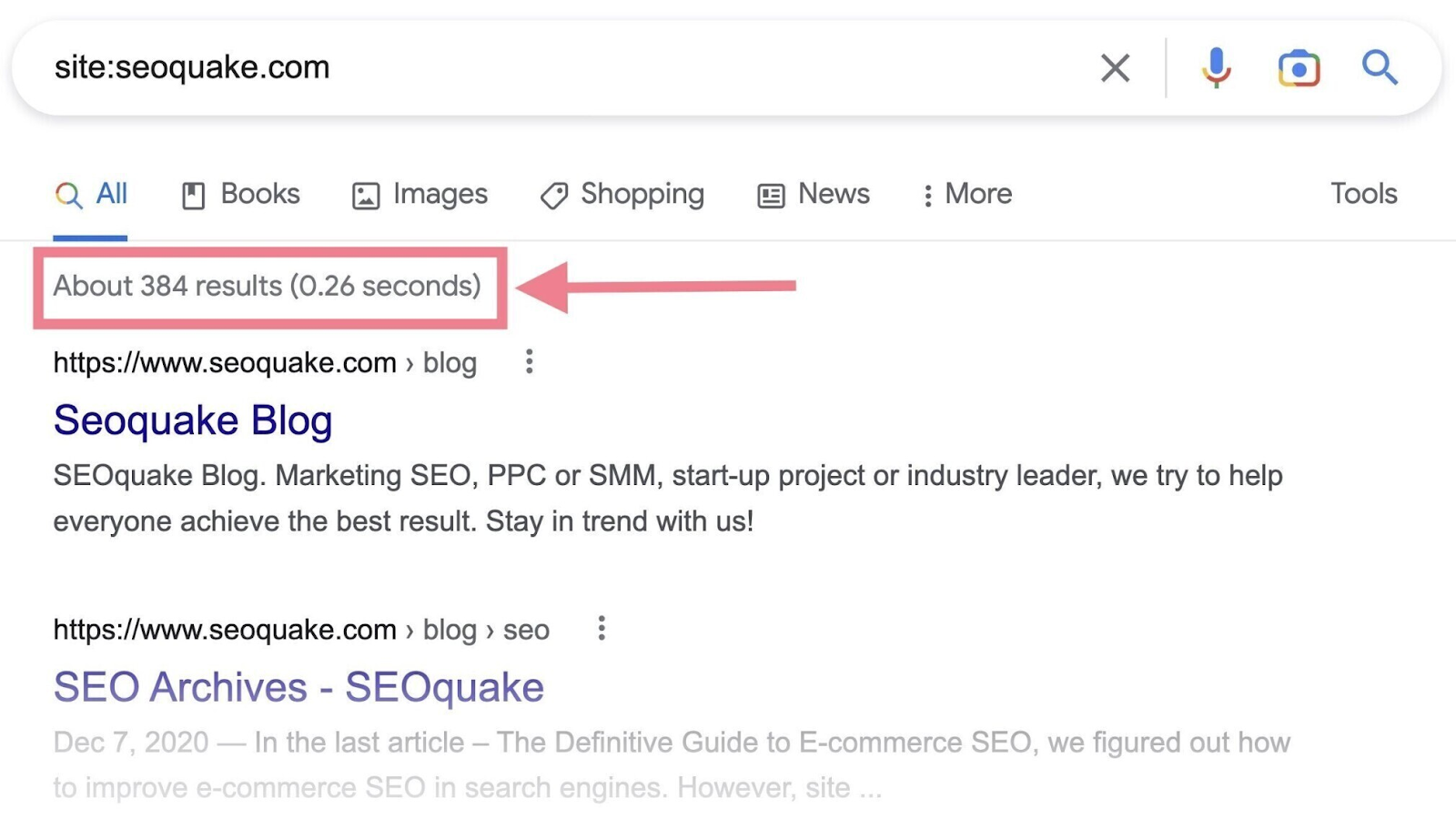
Google makes it easy to find out whether your site has been indexed—by using the site: search operator.
Here’s how to check:
- Go to Google
- In the search bar, type in the site: search operator followed by your domain (e.g., “site:yourdomain.com”)
- When you look below the search bar, you’ll see an estimate of how many of your pages Google has indexed
If zero results show up, none of your pages are indexed.
If there are indexed pages, Google will show them as search results.
That’s how you quickly check the indexing status of your pages. But it’s not the most practical way, as it may be difficult to spot specific pages that haven’t been indexed.
The alternative (and preferable) way to check if Google has indexed your website is to use Google Search Console (GSC). We’ll take a closer look at it and how to index your website on Google in the next section.
How Do You Get Google to Index Your Site?
If you have a new website, it can take Google some time to index it because it has to be crawled first. And crawling can take anywhere from a few days to a few weeks.
(Indexing usually happens right after that, but it’s not guaranteed.)
But you can speed up the process.
The easiest way is to request indexing in Google Search Console. GSC is a free toolset that allows you to check your website’s presence on Google and troubleshoot any related issues.
If you don’t have a GSC account yet, you’ll need to:
- Sign in with your Google account
- Add a new property (your website) to your account
- Verify ownership of the website
Need help? Read our detailed guide to help you set up Google Search Console.
Then, follow these steps:
Create and Submit a Sitemap
An XML sitemap is a file that lists all the URLs you want Google to index. Which helps crawlers find your main pages faster.
It looks something like this:

You’ll likely find your sitemap on this URL: “https://yourdomain.com/sitemap.xml”
If you don’t have one, read our guide to creating an XML sitemap (or this guide to WordPress sitemaps if your website runs on WordPress).
Once you have the your sitemap URL, go to “Sitemaps” in GSC. You’ll find it under the “Indexing” section in the left menu.
Enter your sitemap URL and hit “Submit.”
It may take a couple of days for your sitemap to be processed. When it’s done, you should see the link to your sitemap and a green “Success” status in the report.
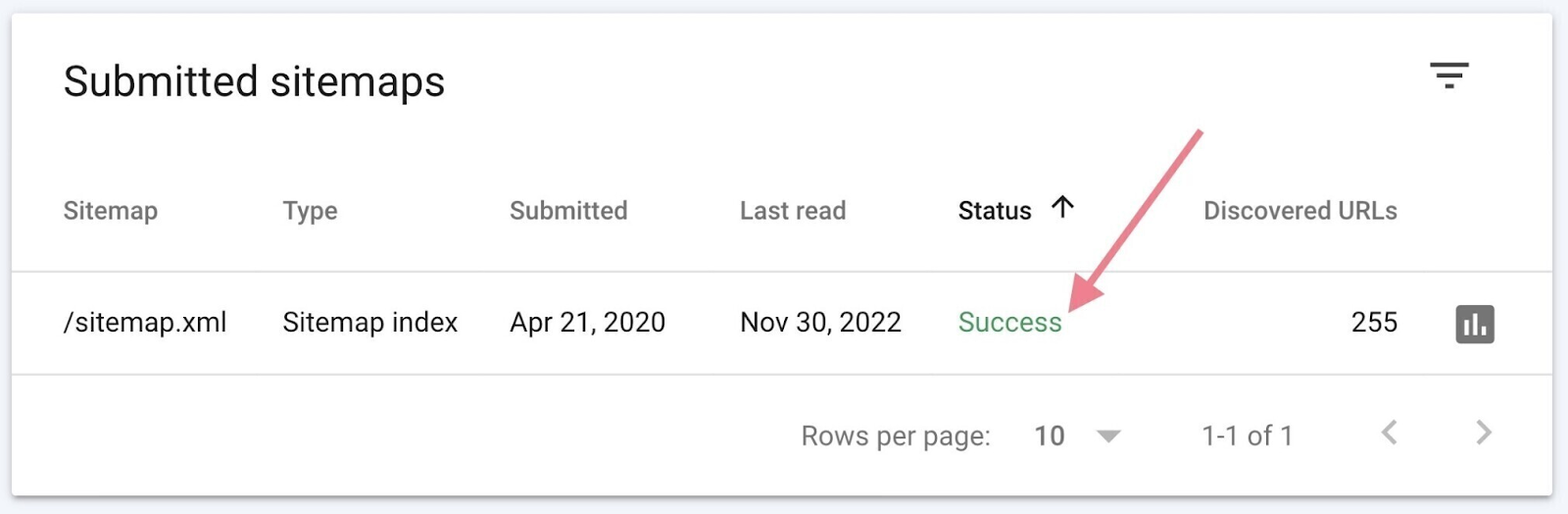
Submitting the sitemap can help Google discover all the pages you deem important. And speed up the process of indexing them.
Use the URL Inspection Tool
To check the status of a specific URL, use the URL inspection tool in GSC.
Start by entering the URL in the search bar at the top.

If you see the “URL is on Google” status, it means Google has crawled and indexed it.
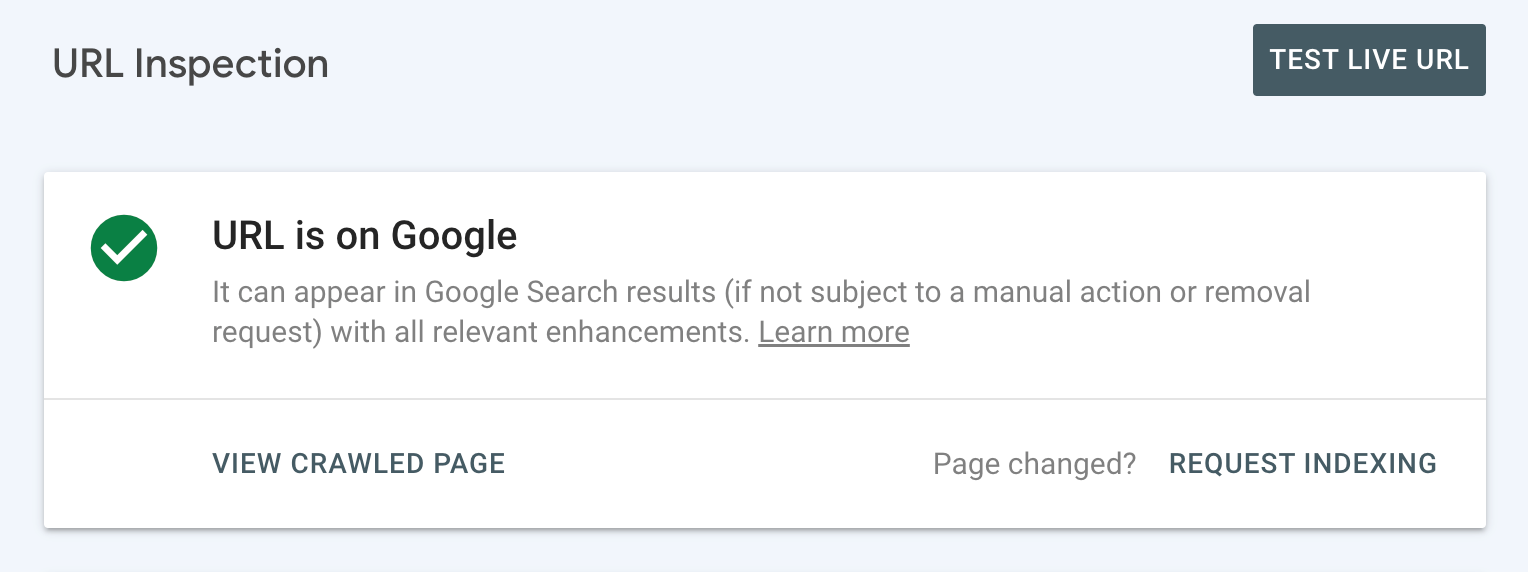
You can check the details to see when it was last crawled and also get other helpful information.

If this is the case, you’re all set and don’t have to do anything.
But if you see the “URL is not on Google” status, it means the inspected URL isn’t indexed and can’t appear in Google’s search engine results pages (SERPs).
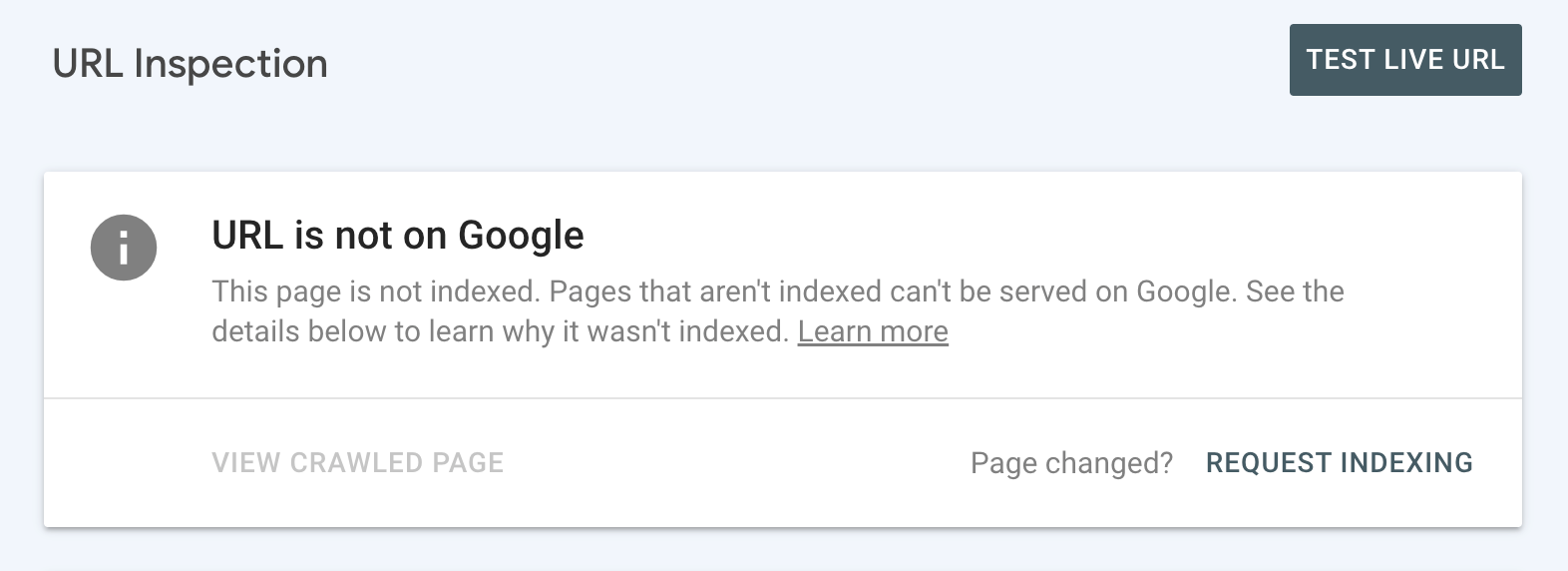
You’ll probably see the reason why the page hasn’t been indexed. And you’ll need to address the issue (see next section for how to do this).
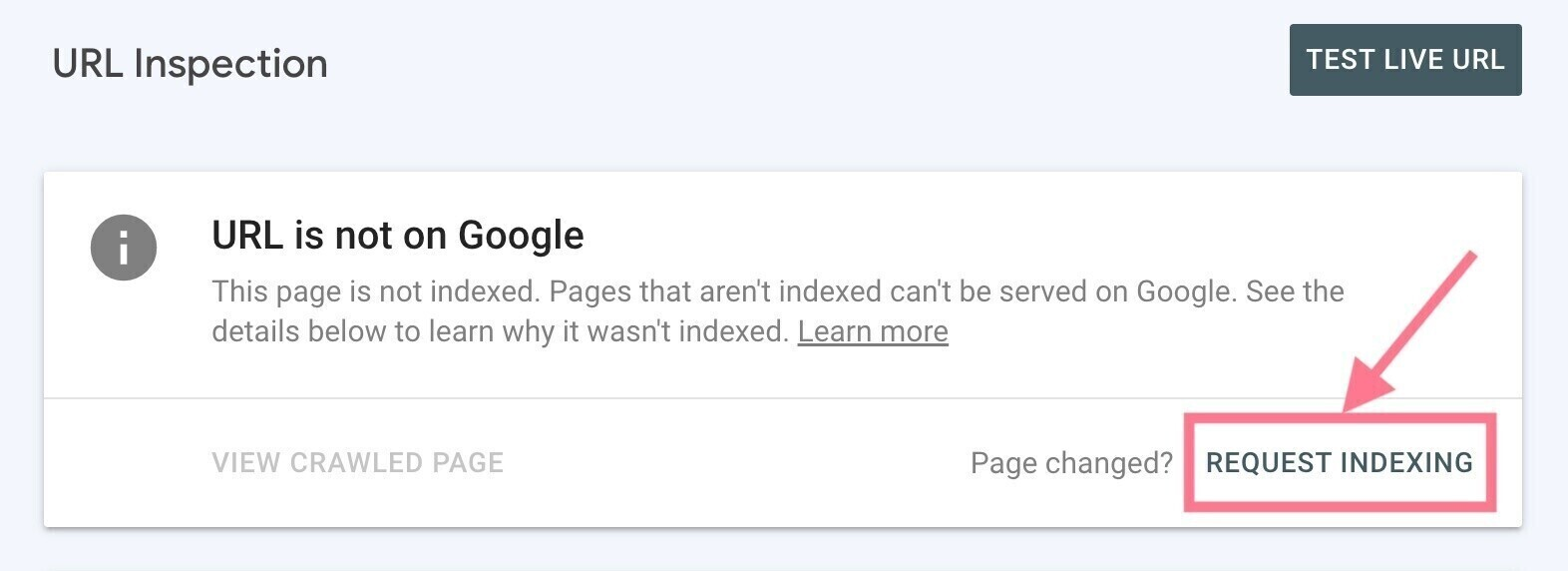
Once that’s done, you can request indexing by clicking the “Request Indexing” link.
Common Indexing Issues to Find and Fix
Sometimes, there may be issues with your website’s technical SEO that keep your site (or a specific page) from being indexed—even if you request it.
This can happen if your site isn’t mobile-friendly, loads too slowly, has redirect issues, etc.
Perform a technical SEO audit with Semrush’s Site Audit to find out why Google has not indexed your pages.
Here’s how:
- Create a free Semrush account (no credit card needed)
- Set up your first crawl (we have a detailed setup guide to help you)
- Click the “Start Site Audit” button
After you run the audit, you’ll get an in-depth view of your site’s health.
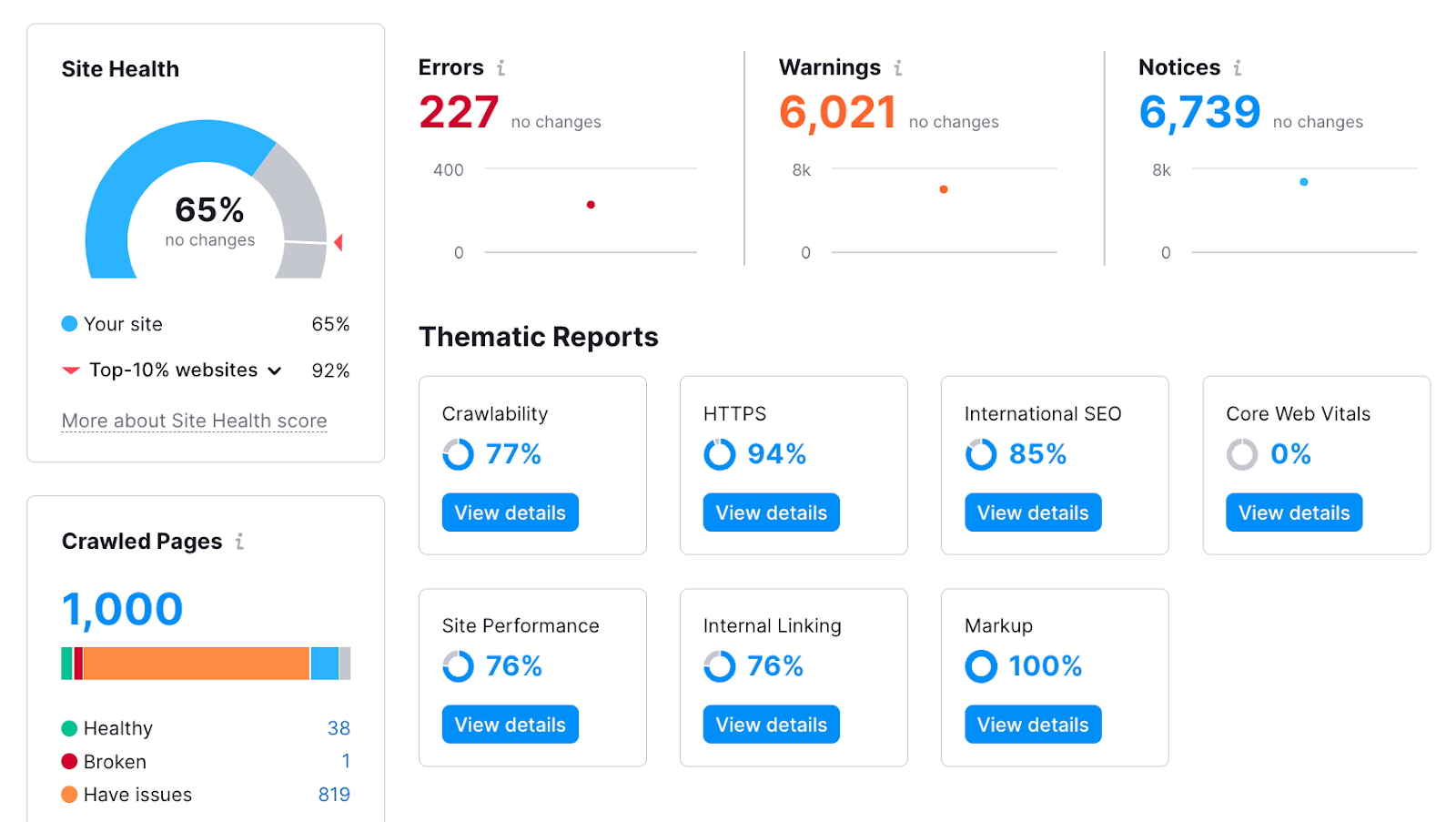
You can also see a list of all the problems by clicking the “Issues” tab:
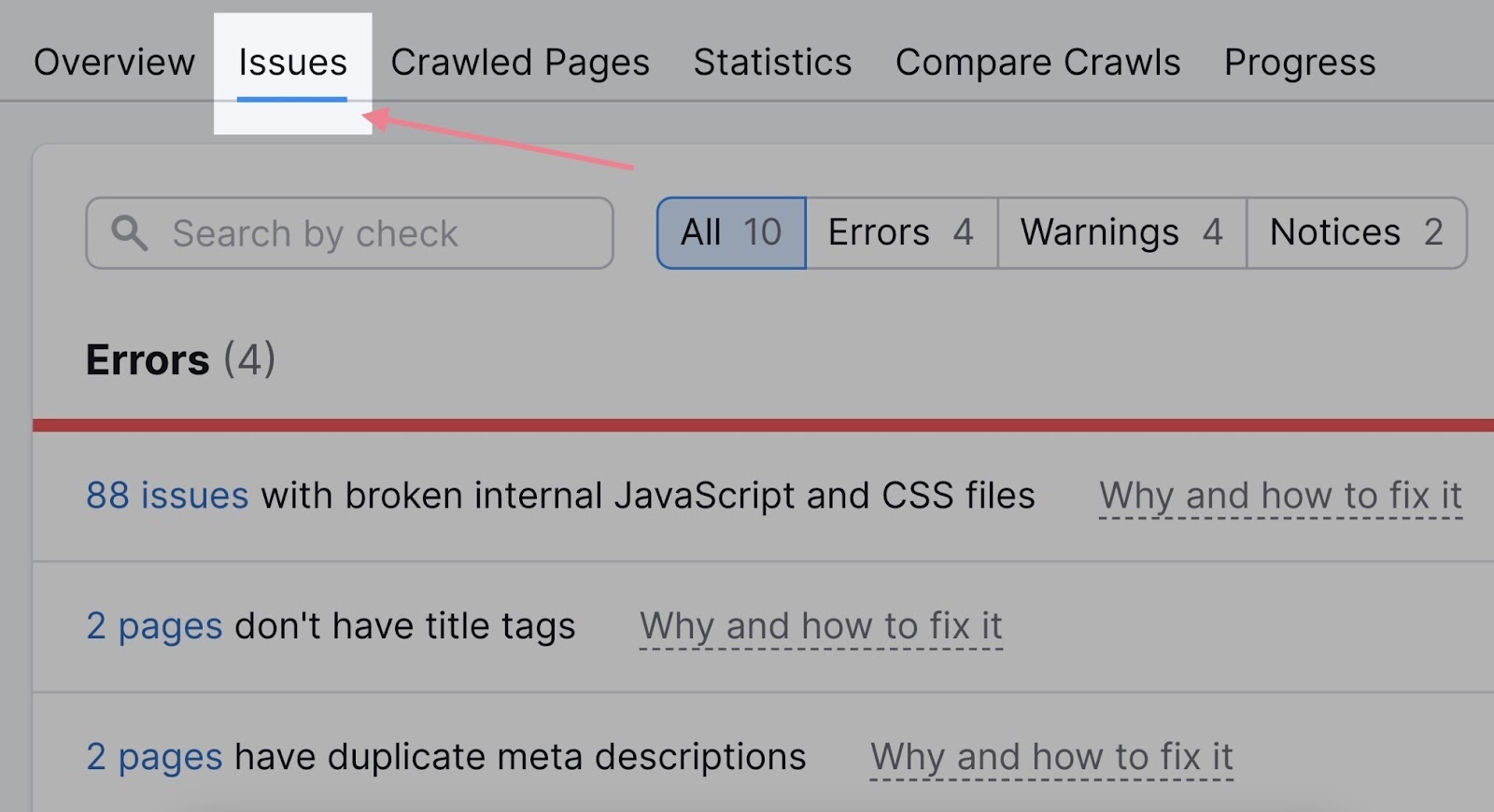
The issues related to indexing will almost always appear at the top of the list—in the “Errors” section.
Let’s take a look at some common reasons why your site may not be indexed and how to fix the problems.
Mistakes with Your Robots.txt File
Your robots.txt file gives instructions to search engines about which parts of a website they shouldn’t crawl. And it looks something like this:
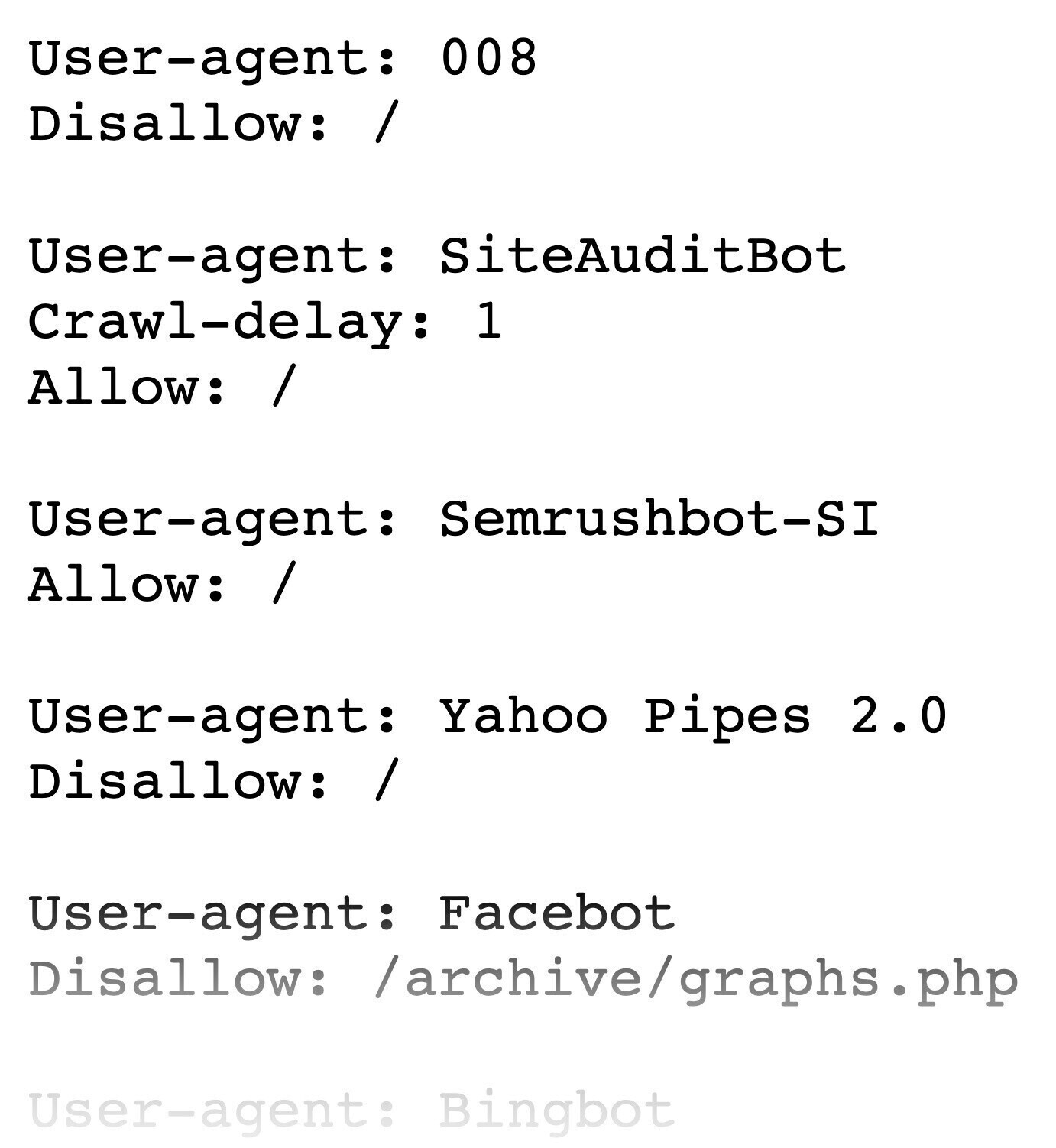
You’ll find yours at “https://yourdomain.com/robots.txt.”
(Follow our guide to create a robots.txt file if you don’t have one.)
You may want to use directives to block Google from crawling duplicate pages, private pages, or resources like PDFs and videos.
But if your robots.txt file tells Googlebot (or web crawlers in general) that your entire site shouldn’t be crawled, there’s a high chance it won’t be indexed either.
Each directive in robots.txt consists of two parts:
- “User-agent” identifies the crawler
- The “Allow” or “Disallow” instruction indicates what should and shouldn’t be crawled on the site (or part of it)
For example:
User-agent: *
Disallow: /
This directive says all crawlers (represented by an asterisk) shouldn’t crawl (indicated by “disallow:”) the whole site (represented by a slash symbol).
Inspect your robots.txt to make sure there’s no directive that could prevent Google from crawling your site or pages/folders you want to have indexed.
Accidental Use of Noindex Tags
One way to tell search engines not to index your pages is to use the robots meta tag with a “noindex” attribute.
It looks like this:
<meta name="robots" content="noindex">
You can check what pages on your website have noindex meta tags in Google Search Console:
- Click the “Pages” report under the “Indexing” section in the left menu
- Scroll down to the “Why pages aren’t indexed” section
- Click “Excluded by ‘noindex’ tag” if you see it
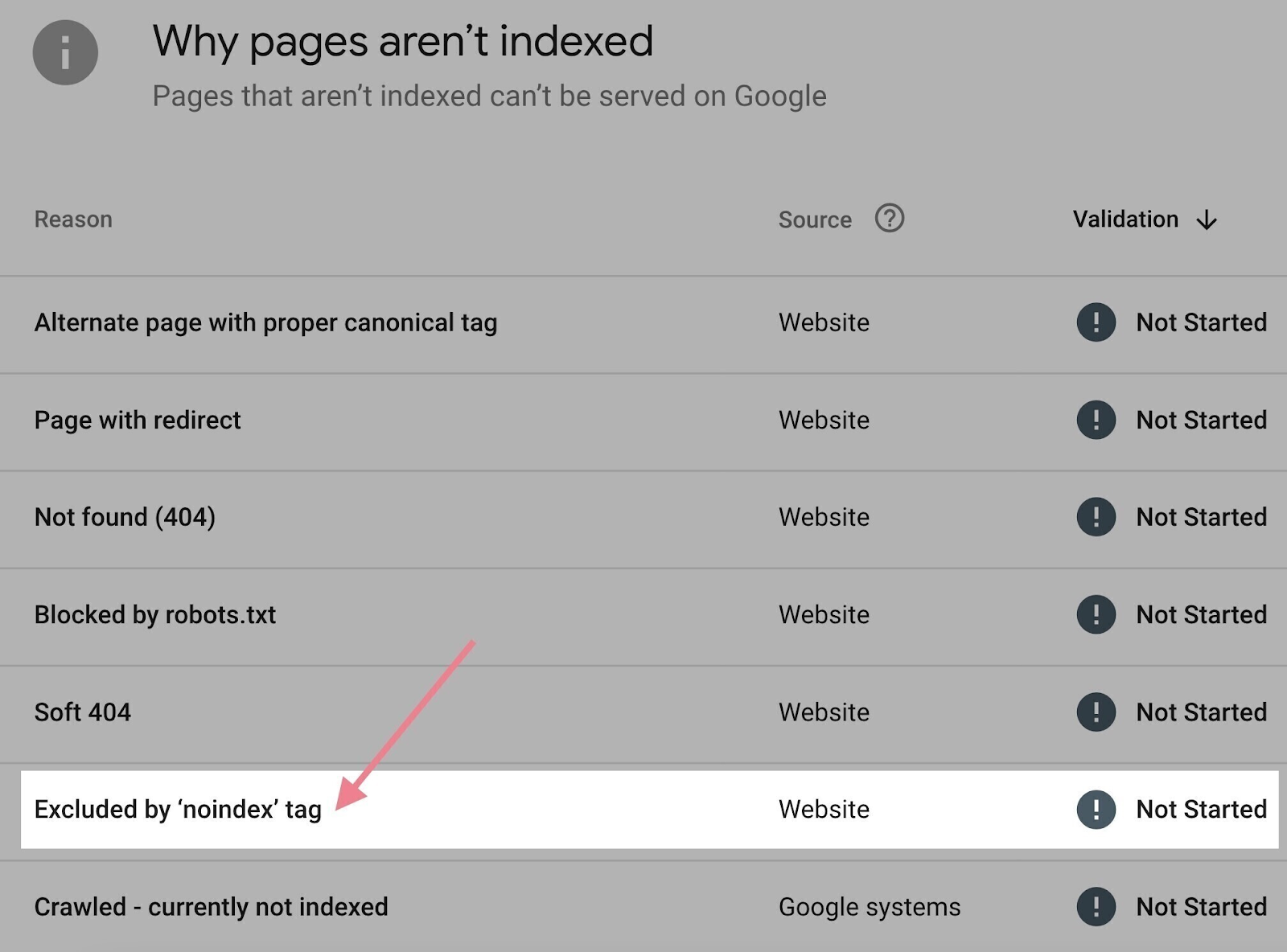
If the list of URLs contains a page you want indexed, simply remove the noindex meta tag from the source code of that page.
Semrush’s Site Audit will also warn you about pages that are blocked either through the robots.txt file or the noindex tag.
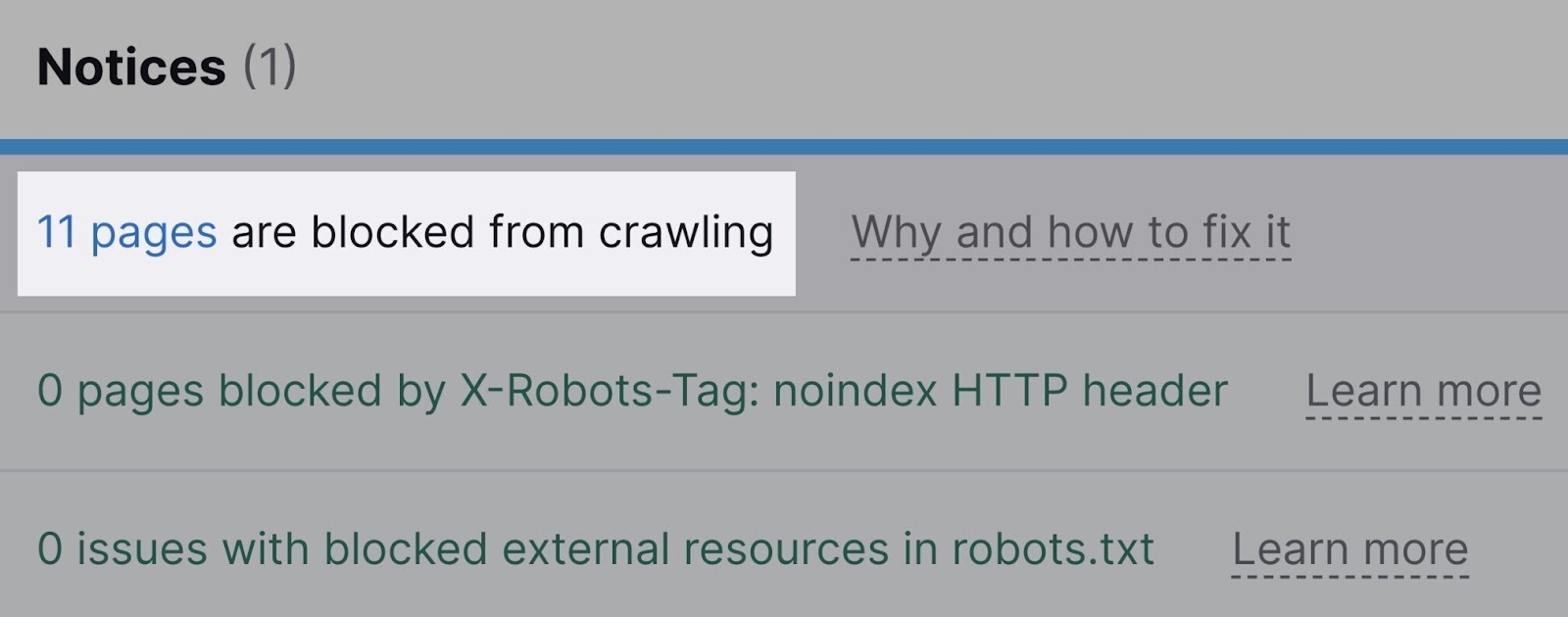
It’ll also notify you about resources blocked by the x-robots-tag, which is usually used for non-HTML documents (such as PDF files).

Improper Canonical Tags
Another reason your page may not be indexed is that it mistakenly contains a canonical tag.
Canonical tags tell crawlers if a certain version of a page is preferred. To prevent issues caused by duplicate content appearing on multiple URLs.
If a page has a canonical tag pointing to another URL, Googlebot assumes there’s a preferred version of that page. And will not index the page in question, even if there is no alternate version.
The “Pages” report in Google Search Console can help here.
Scroll down to the “Why pages aren’t indexed” section. Click the “Alternate page with proper canonical tag” reason.
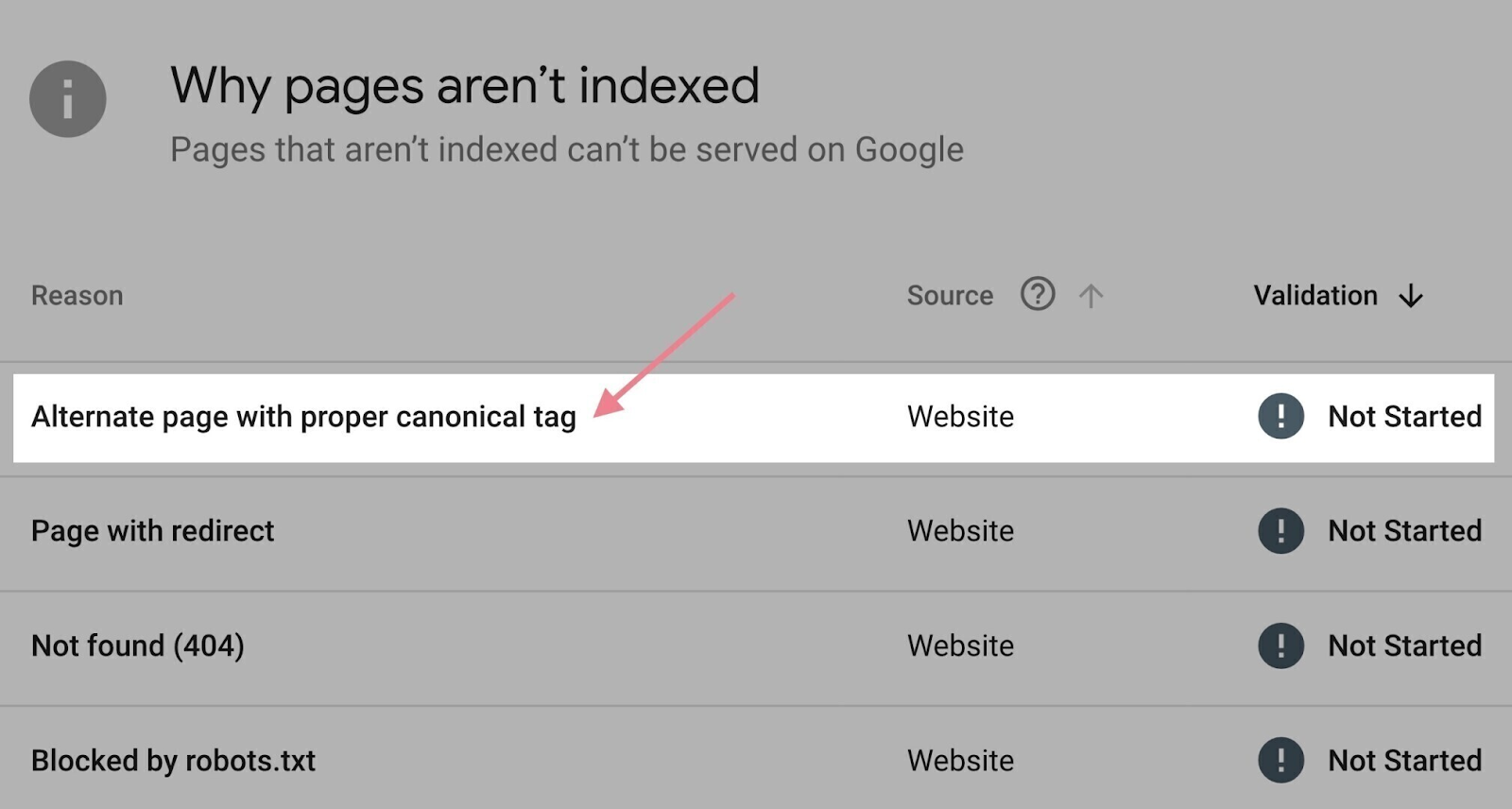
You’ll see a list of affected pages to go through.
If there’s a page you want to have indexed (meaning the canonical is used incorrectly), remove the canonical tag from that page. Or make sure it points to itself.
Internal Link Problems
Internal links help crawlers find your webpages. Which can speed up the process of indexing.
If you want to audit your internal links, go to the “Internal Linking” thematic report in Site Audit.
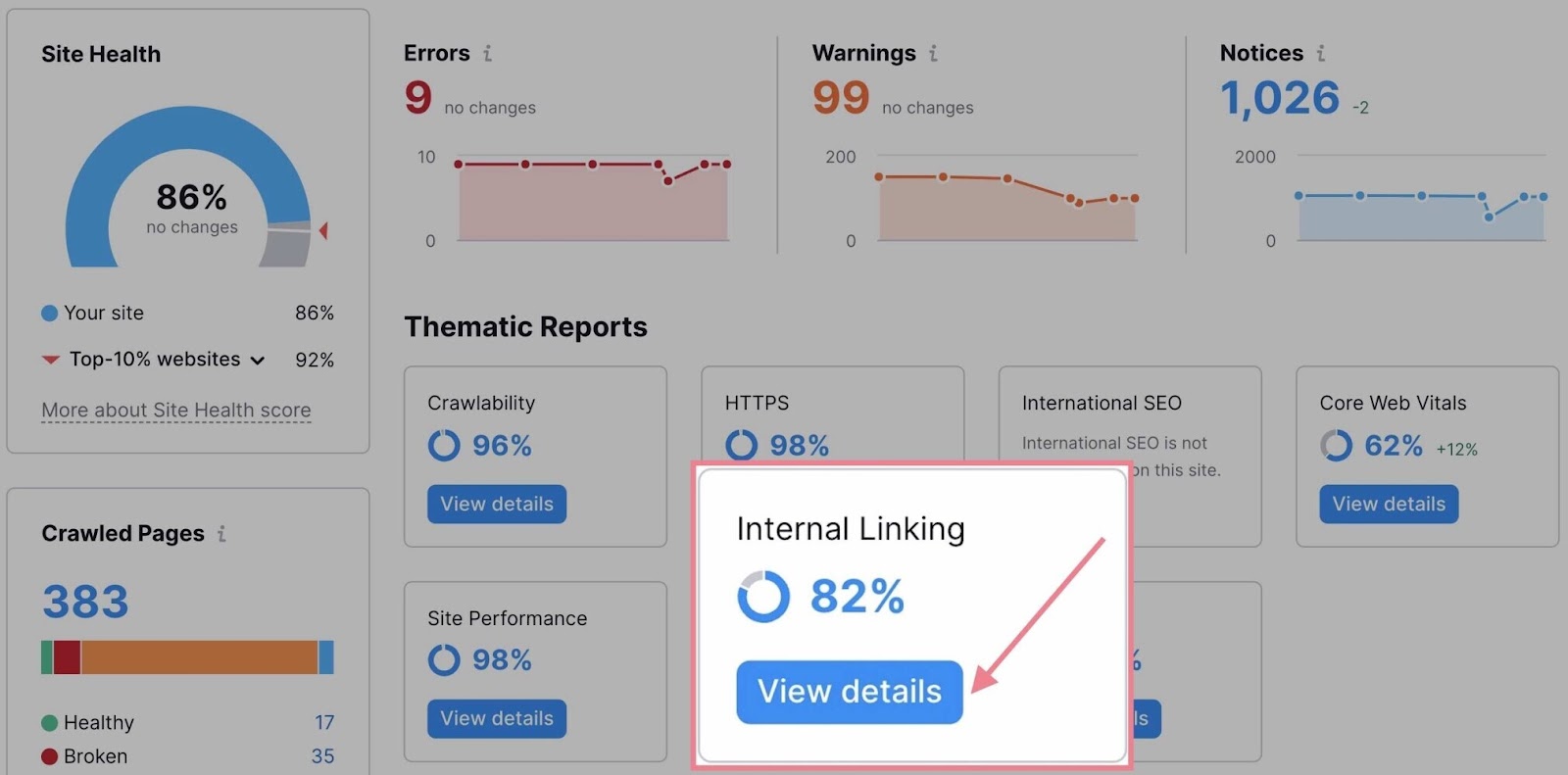
The report will list all the issues related to internal linking.
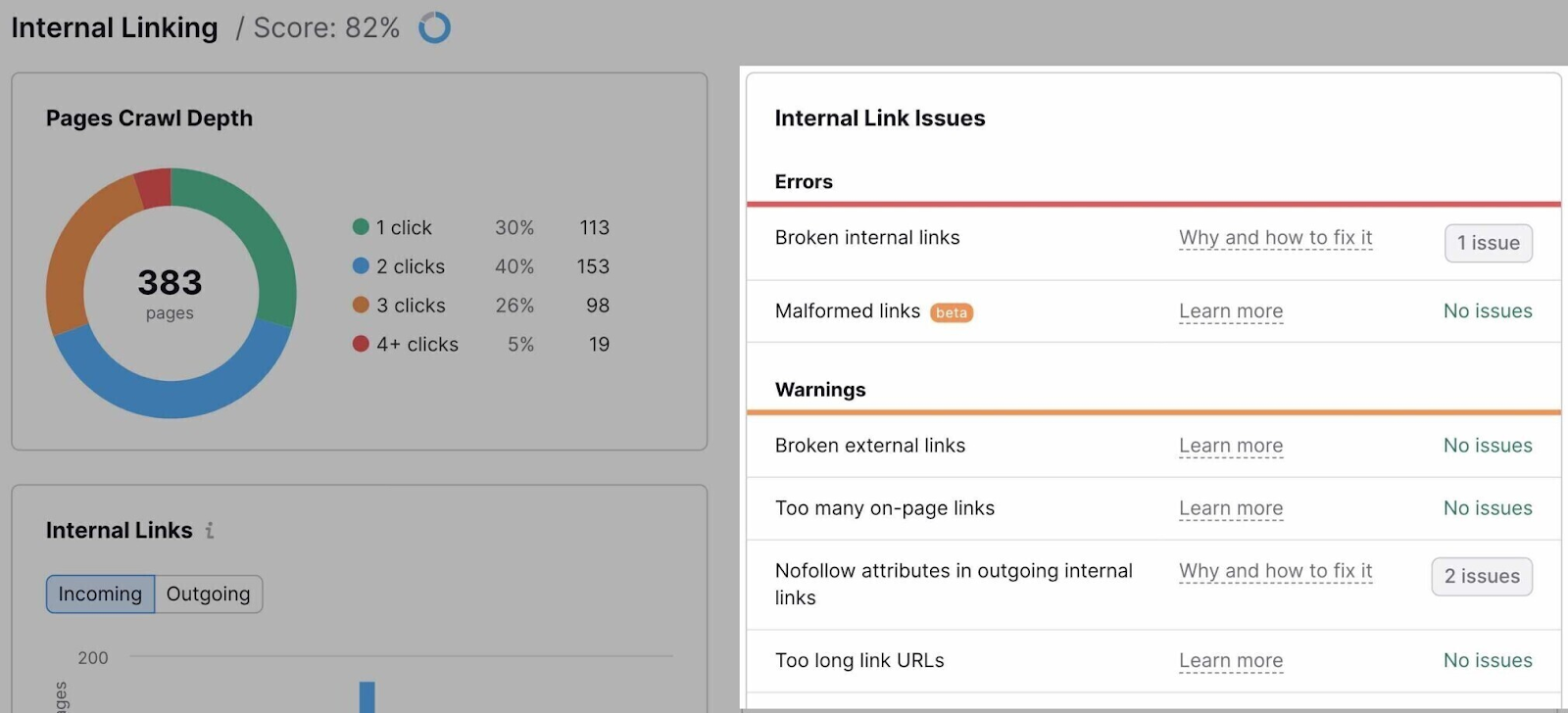
It would help to fix all of them, of course. But these are some of the most important issues to address when it comes to crawling and indexing:
- Outgoing internal links contain nofollow attribute: Nofollow links generally don’t pass authority. If they’re internal, Google may choose to ignore the target page when crawling your site. Make sure you don’t use them for pages you want to have indexed.
- Pages need more than 3 clicks to be reached: If pages need more than three clicks to be reached from the homepage, there’s a chance they won’t be crawled and indexed. Add more internal links to these pages (and review your website architecture).
- Orphaned pages in sitemap: Pages that have no internal links pointing to them are known as “orphaned pages.” They’re rarely indexed. Fix this issue by linking to any orphaned pages.
To see pages affected by a specific problem, click the link stating the number of found issues next to it.
Last but not least, don’t forget to use internal linking strategically:
- Link to your most important pages: Google recognizes that pages are important to you if they have more internal links
- Link to your new pages: Make internal linking part of your content creation process to speed up the indexing of your new pages
404 Errors
A 404 error shows up when a web server can’t find a page at a certain URL.
Which can happen for a number of reasons. Like an incorrect URL, a deleted page, a change in URL, or a website misconfiguration.
And 404 errors can prevent Google from finding, indexing, and ranking your pages. They also harm the user experience.
That’s why you should check for 404 errors and fix them.
In your Site Audit report, click “Issues.”
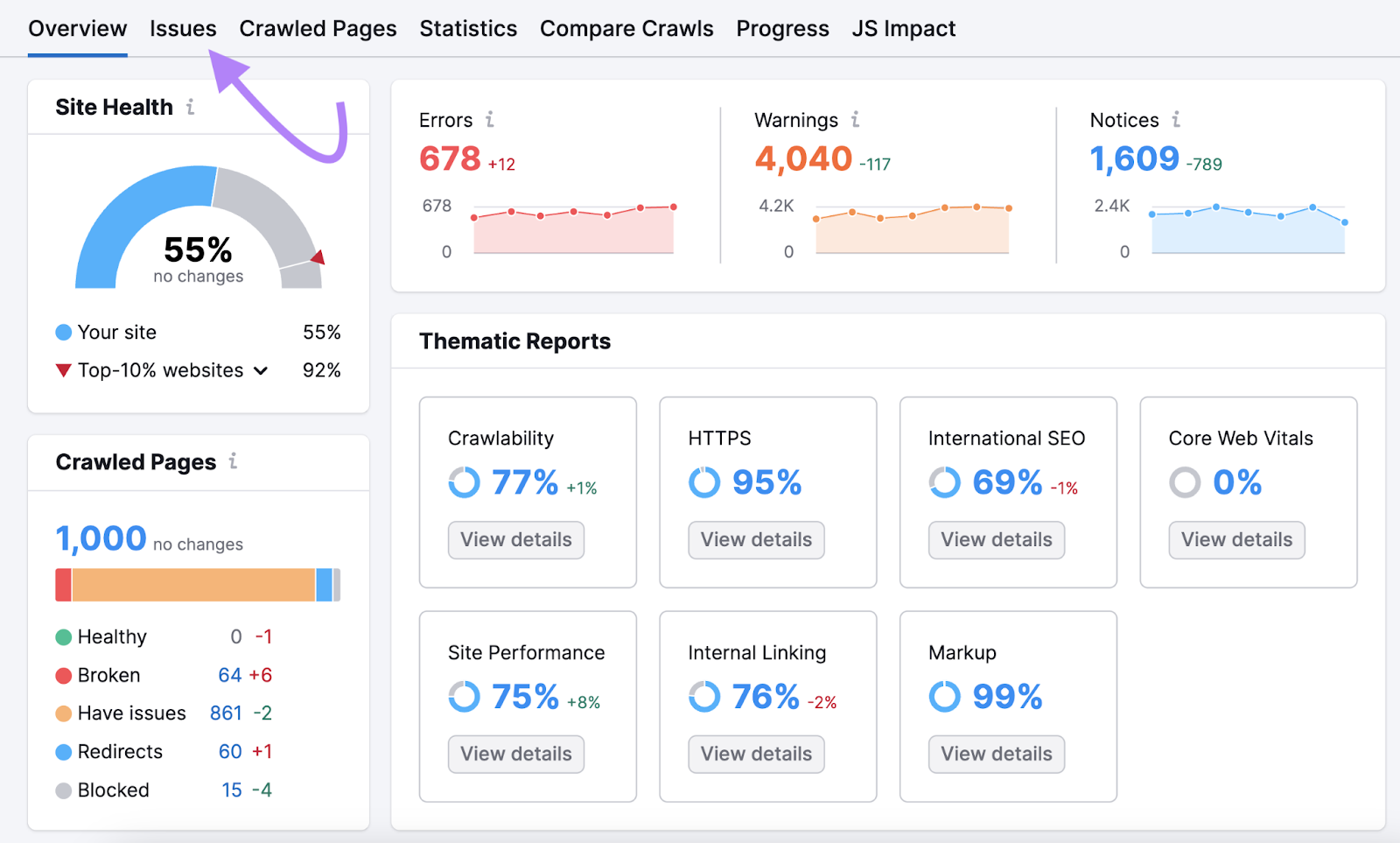
Find and click on the link in “# pages returned a 4XX status code.”
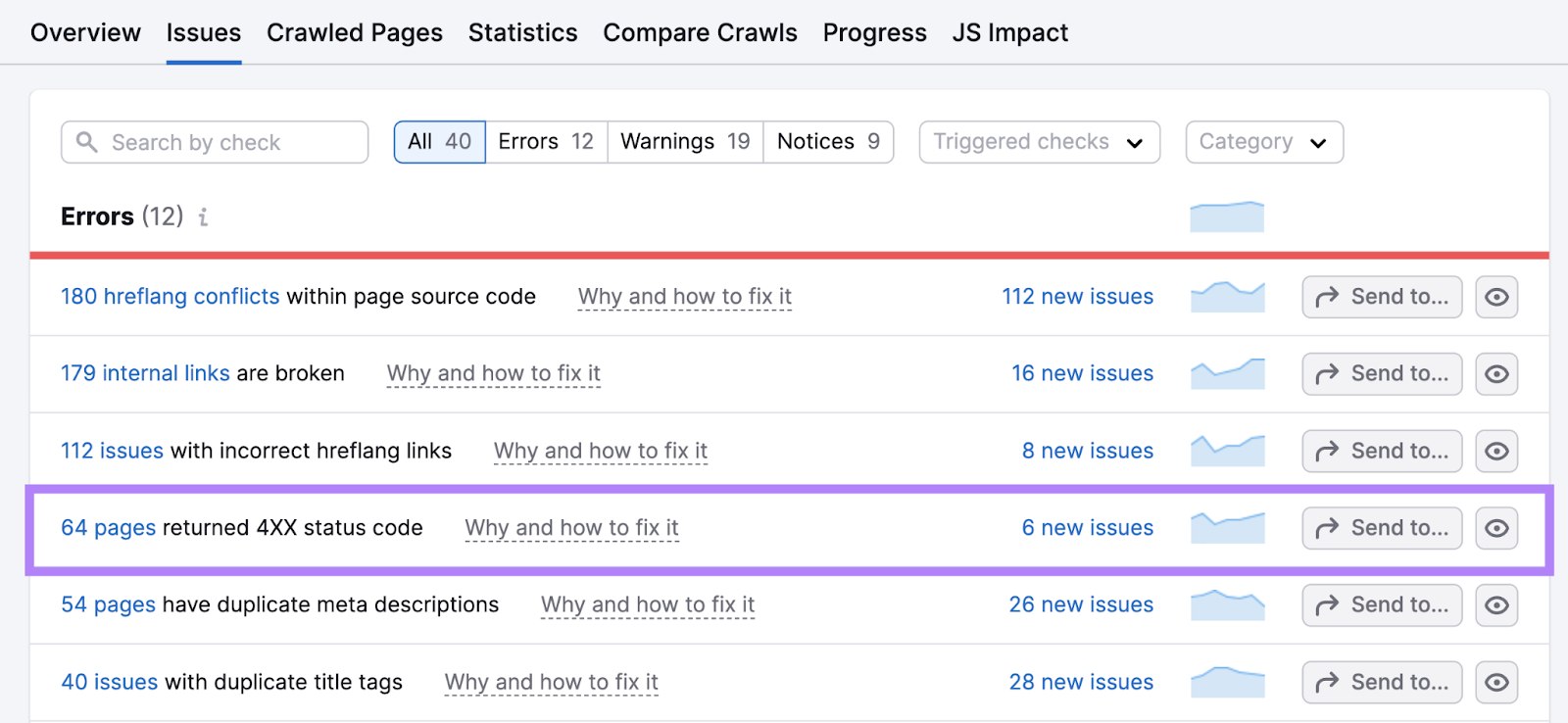
For any pages that have “404” indicated as the error, click “View broken links” to see all the pages that include a link to that broken URL.
Then, change those links to the correct URLs by fixing typos in ones that were mistyped. Or linking to the new pages where the content is now located.
If there’s content from any broken URLs that no longer exists, replace the links with the best possible substitutes.
Duplicate Content
Duplicate content is when identical or incredibly similar content appears in more than one place on your site. And it can confuse search engines, leading to indexing a page you don’t want to be the primary page for search rankings.
Find duplicate content issues by clicking “Issues” in your Site Audit project and searching for “duplicate.”
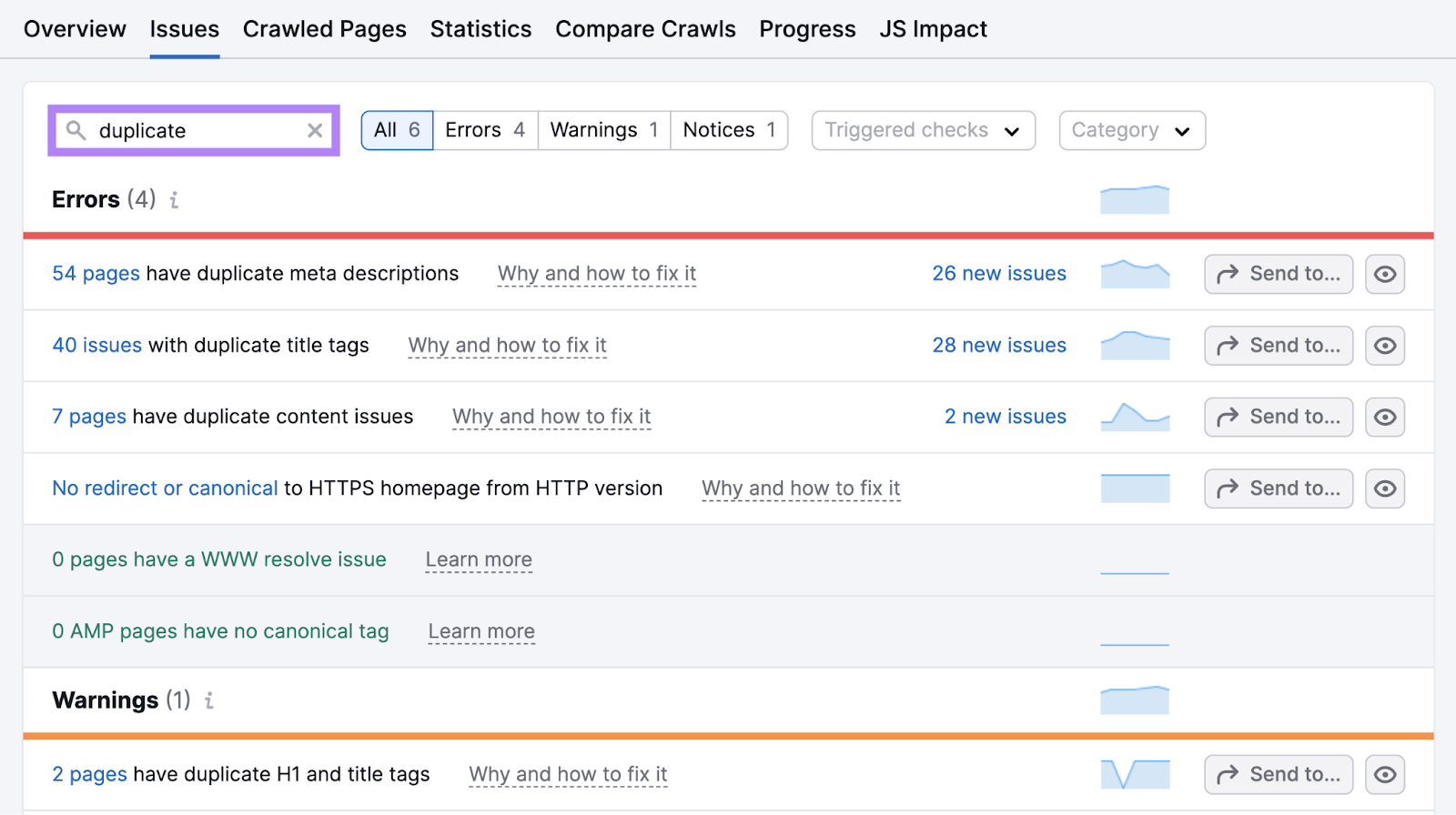
Click the hyperlink in “# pages have duplicate content issues” to see a list of affected pages.
If you have duplicates that aren’t serving a purpose, include any content from those pages on the main page. Then, delete the duplicates and implement a 301 redirects to the main page.
If you need to keep the duplicates, use canonical tags to indicate which one is the main one.
Poor Site Quality
Even if your website meets all technical requirements, Google may not index all your pages. Especially if it doesn’t consider your site to be high quality.
In an episode of SEO Office Hours, John Mueller from Google advises prioritizing site quality:
If you have a smaller site and you’re seeing a significant part of your pages are not being indexed, then I would take a step back and try to reconsider the overall quality of the website and not focus so much on technical issues for those pages.
If this sounds like your situation, follow the three best practices below to enhance it.
Create High-Quality Content
Quality content that’s “helpful, reliable, and people-first” is more likely to be indexed and served in search results.
Here are some tips to improve the quality of the content you publish on your site:
- Center your content around customers’ needs and pain points. Address pertinent problems and questions and provide actionable solutions.
- Showcase your expertise. Publish content written by or including insights from subject matter experts. Share real-life examples and your brand’s experience with the topic.
- Update your content regularly. Make sure what you post is relevant and up to ****. Run regular content audits to identify mistakes, outdated information, and opportunities for improvement.
Build Relevant Backlinks
Google views backlinks (links on other sites that point to your site) from industry-relevant, high-quality websites as recommendations. So, the more successful your link building efforts (proactively taking steps to gain backlinks) are, the better your chances of ranking.
And having more backlinks helps with indexing. Because Google’s crawler finds new pages to index through links.
You can use different link building tactics to gain more high-quality links. For example, doing targeted outreach to journalists and bloggers, writing articles for other sites, and analyzing competitors’ backlinks for opportunities you can replicate.
Use Backlink Gap to dive deeper into competitor backlinks.
Enter your domain and up to four competitors’s domains. Click “Find prospects.”

The “Best” tab shows you websites that link to all your competitors but not to you.
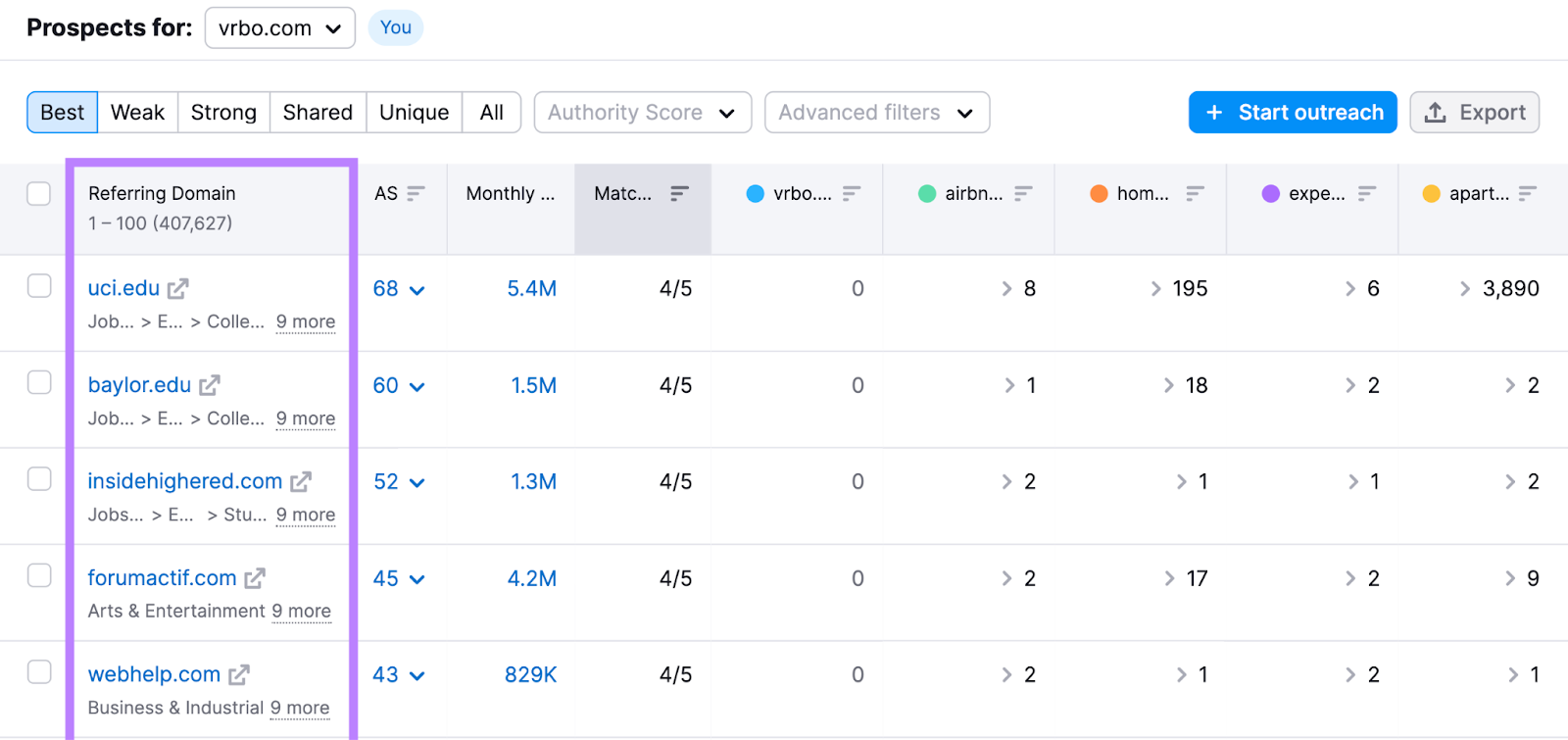
Look through your competitors’ pages and explore how you can replicate some of the backlinks. Here are a few examples:
- Contributing expert insights: Find websites where rival brands publish guest articles, get cited as subject matter experts, or appear as podcast guests. Reach out to those websites to explore how you can be featured.
- Create better content: See which industry-leading online publications your competitors appear on. Consider creating a similar but better page with original insights, and then pitch it to those publications as a replacement link.
Further reading: How to Find Your Competitors’ Backlinks: A Step-by-Step Guide
Improve E-E-A-T Signals
E-E-A-T stands for “Experience, Expertise, Authoritativeness, and Trustworthiness.” These are part of Google’s Search Quality Rater Guidelines that real people use to evaluate search results.
This means creating pages with E-E-A-T in mind is more likely to help your search performance.
To improve your site’s E-E-A-T, aim to:
- Provide transparent author information. Highlight your contributors’ personal experiences and expertise concerning the topics they write about.
- Collaborate with subject matter experts. Include insights from industry experts. Or even hire them to review your content and ensure its accuracy.
- Support the claims you make. Cite credible sources across all your published content. So readers know the information you provide is reputable.
Further reading: What Are E-E-A-T and YMYL in SEO & How to Optimize for Them
Monitor Your Site for Indexing Issues
Fixing your indexing issues isn’t a one-time thing. New issues might crop up in the future—especially whenever you add new content or update your website’s structure.
Site Audit can help you spot new technical problems early before they escalate.
Simply select periodic audits in the settings.
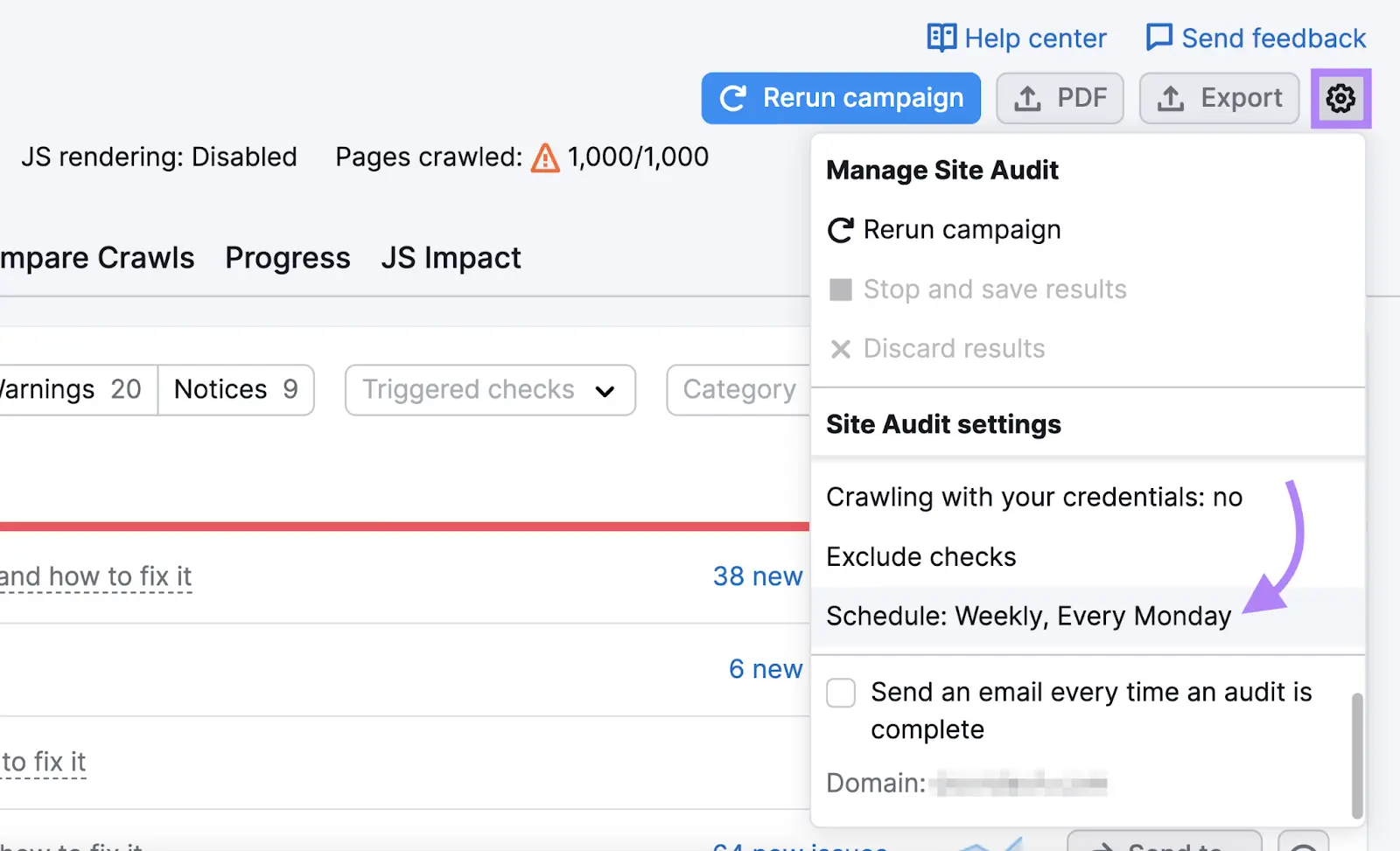
You’ll get an option to set up automatic scans on a daily or weekly basis
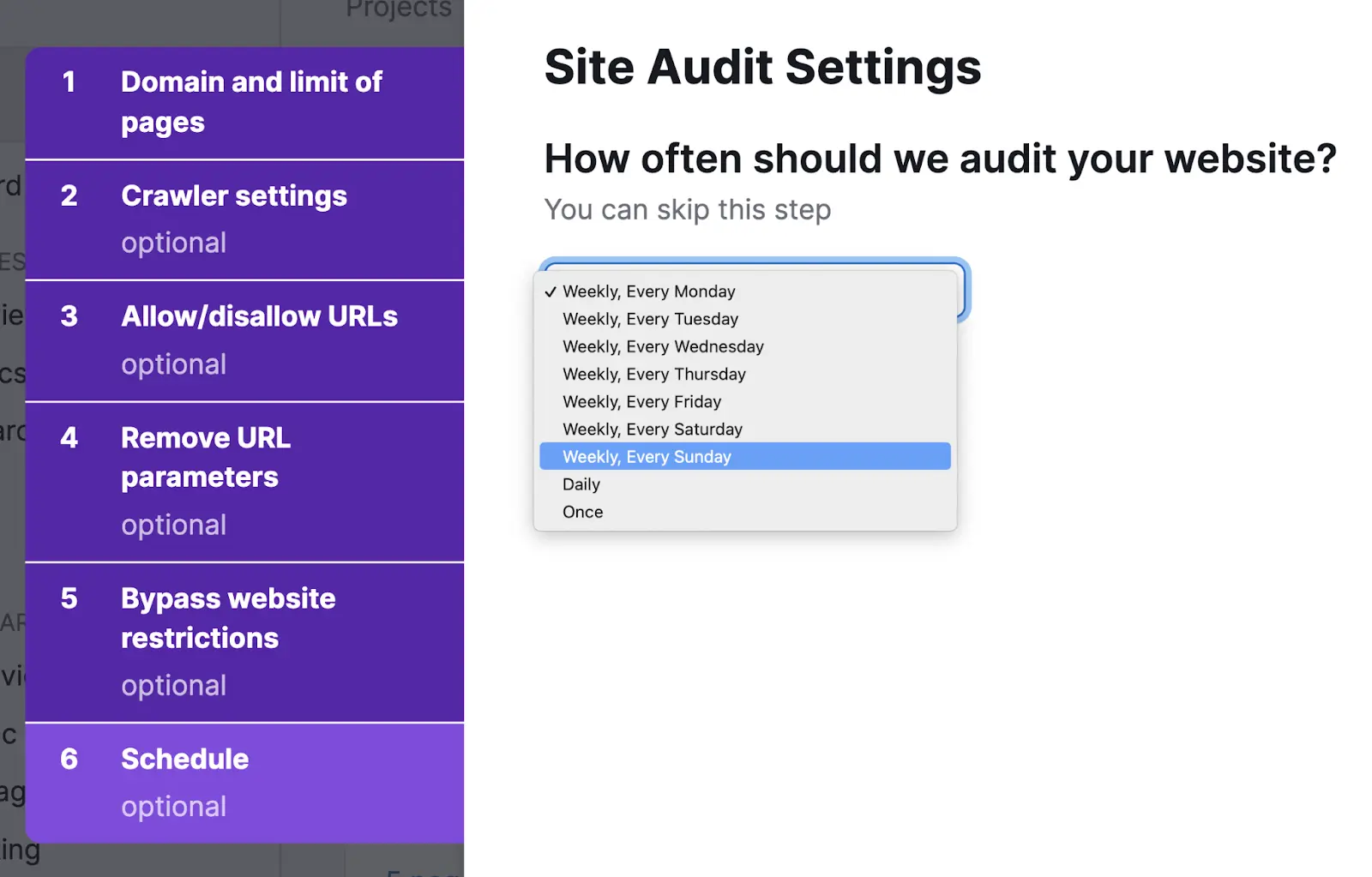
We recommend configuring weekly scans to start. You can adjust the cadence later as needed.
Site Audit will quickly flag any technical problems. Which means you can address them before they cause serious issues.
Google Indexing FAQs
How Long Does It Take Google to Index a Website?
The time Google needs to index your site varies greatly, depending on the size of your website. It can take a few days for smaller sites. And up to a few months for large websites.
How Can You Get Google to Index Your Website Faster?
You can specifically ask Google to crawl and index your content by:
- Submitting your sitemap (for indexing entire websites) in Google Search Console
- Requesting Google indexing (for a single URL) in Google Search Console
What’s the Difference Between Crawling and Indexing?
Crawling is the discovery process Google’s bot uses to follow links to find new websites and pages. Indexing is when Googlebot analyzes the content of a page to understand it and store it for ranking purposes.
Why Are Some of Your Webpages Not Indexed By Google?
Your pages may not be indexed due to issues like:
- Your robots.txt file is blocking Googlebot from indexing certain pages
- Googlebot can’t find the page because of a lack of internal links
- There are 404 issues
- Your site might has duplicate content
Find these issues and more using Site Audit.
Source link : Semrush.com