
Migrating a large website is always daunting. Big traffic is at stake among many moving parts, technical challenges and stakeholder management.
Historically, one of the most onerous tasks in a migration plan has been redirect mapping. The painstaking process of matching URLs on your current site to the equivalent version on the new website.
Fortunately, this task that previously could involve teams of people combing through thousands of URLs can be drastically sped up with modern AI ******.
Should you use AI for redirect mapping?
The term “AI” has become someone conflated with “ChatGPT” over the last year, so to be very clear from the outset, we are not talking about using generative AI/LLM-based systems to do your redirect mapping.
While there are some tasks that tools like ChatGPT can assist you with, such as writing that tricky regex for the redirect logic, the generative element that can cause hallucinations could potentially create accuracy issues for us.
Advantages of using AI for redirect mapping
Speed
The primary advantage of using AI for redirect mapping is the sheer speed at which it can be done. An initial map of 10,000 URLs could be produced within a few minutes and human-reviewed within a few hours. Doing this process manually for a single person would usually be days of work.
Scalability
Using AI to help map redirects is a method you can use on a site with 100 URLs or over 1,000,000. Large sites also tend to be more programmatic or templated, making similarity matching more accurate with these tools.
Efficiency
For larger sites, a multi-person job can easily be handled by a single person with the correct knowledge, freeing up colleagues to assist with other parts of the migration.
Accuracy
While the automated method will get some redirects “wrong,” in my experience, the overall accuracy of redirects has been higher, as the output can specify the similarity of the match, giving manual reviewers a guide on where their attention is most needed
Disadvantages of using AI for redirect mapping
Over-reliance
Using automation tools can make people complacent and over-reliant on the output. With such an important task, a human review is always required.
Training
The script is pre-written and the process is straightforward. However, it will be new to many people and environments such as Google Colab can be intimidating.
Output variance
While the output is deterministic, the ****** will perform better on certain sites than others. Sometimes, the output can contain “silly” errors, which are obvious for a human to spot but harder for a machine.
A step-by-step guide for URL mapping with AI
By the end of this process, we are aiming to produce a spreadsheet that lists “from” and “to” URLs by mapping the origin URLs on our live website to the destination URLs on our staging (new) website.
For this example, to keep things simple, we will just be mapping our HTML pages, not additional assets such as CSS or images, although this is also possible.
Tools we’ll be using
- Screaming Frog Website Crawler: A powerful and flexible website crawler, Screaming Frog is how we collect the URLs and associated metadata we need for the matching.
- Google Colab: A free cloud service that uses a Jupyter notebook environment, allowing you to run a range of languages directly from your browser without having to install anything locally. Google Colab is how we are going to run our Python scripts to perform the URL matching.
- Automated Redirect Matchmaker for Site Migrations: The Python script by Daniel Emery that we’ll be running in Colab.
Step 1: Crawl your live website with Screaming Frog
You’ll need to perform a standard crawl on your website. Depending on how your website is built, this may or may not require a JavaScript crawl. The goal is to produce a list of as many accessible pages on your site as possible.
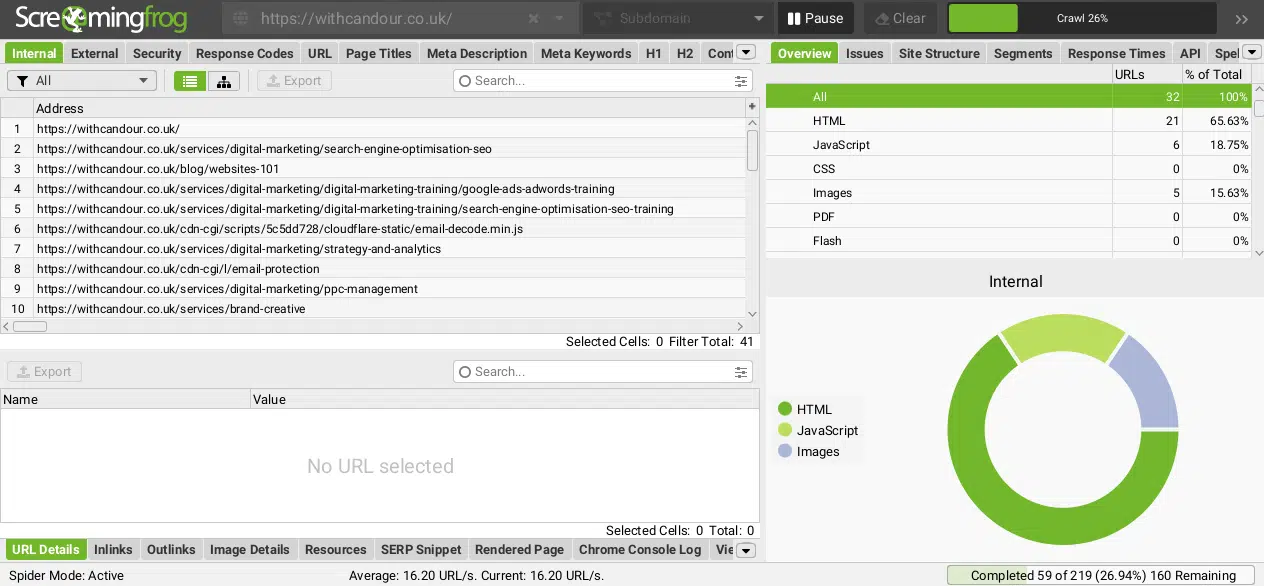
Step 2: Export HTML pages with 200 Status Code
Once the crawl has been completed, we want to export all of the found HTML URLs with a 200 Status Code.
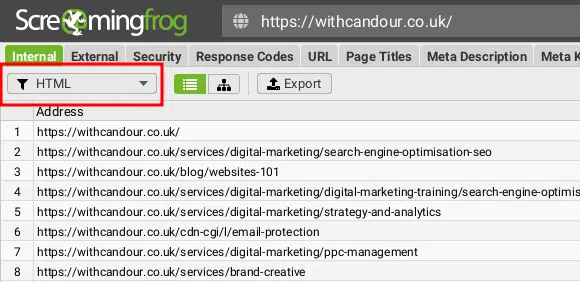
Firstly, in the top left-hand corner, we need to select “HTML” from the drop-down menu.
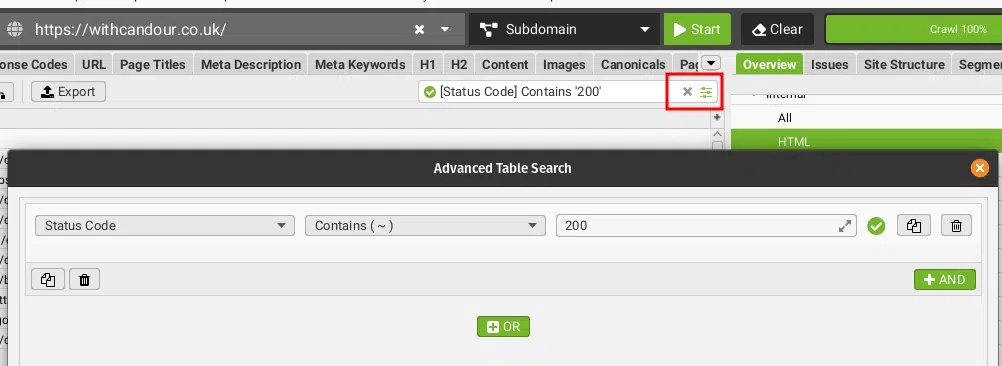
Next, click the sliders filter icon in the top right and create a filter for Status Codes containing 200.
Finally, click on Export to save this data as a CSV.
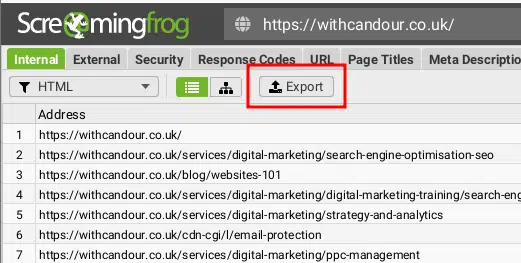
This will provide you with a list of our current live URLs and all of the default metadata Screaming Frog collects about them, such as Titles and Header Tags. Save this file as origin.csv.
Important note: Your full migration plan needs to account for things such as existing 301 redirects and URLs that may get traffic on your site that are not accessible from an initial crawl. This guide is intended only to demonstrate part of this URL mapping process, it is not an exhaustive guide.
Step 3: Repeat steps 1 and 2 for your staging website
We now need to gather the same data from our staging website, so we have something to compare to.
Depending on how your staging site is secured, you may need to use features such as Screaming Frog’s forms authentication if password protected.
Once the crawl has completed, you should export the data and save this file as destination.csv.
Optional: Find and replace your staging site domain or subdomain to match your live site
It’s likely your staging website is either on a different subdomain, TLD or even domain that won’t match our actual destination URL. For this reason, I will use a Find and Replace function on my destination.csv to change the path to match the final live site subdomain, domain or TLD.
For example:
- My live website is
https://withcandour.co.uk/(origin.csv) - My staging website is
https://testing.withcandour.dev/(destination.csv) - The site is staying on the same domain; it’s just a redesign with different URLs, so I would open destination.csv and find any instance of
https://testing.withcandour.devand replace it withhttps://withcandour.co.uk.
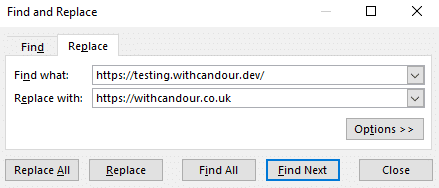
This also means when the redirect map is produced, the output is correct and only the final redirect logic needs to be written.
Step 4: Run the Google Colab Python script
When you navigate to the script in your browser, you will see it is broken up into several code blocks and hovering over each one will give you a”play” icon. This is if you wish to execute one block of code at a time.
However, the script will work perfectly just executing all of the code blocks, which you can do by going to the Runtime’menu and selecting Run all.
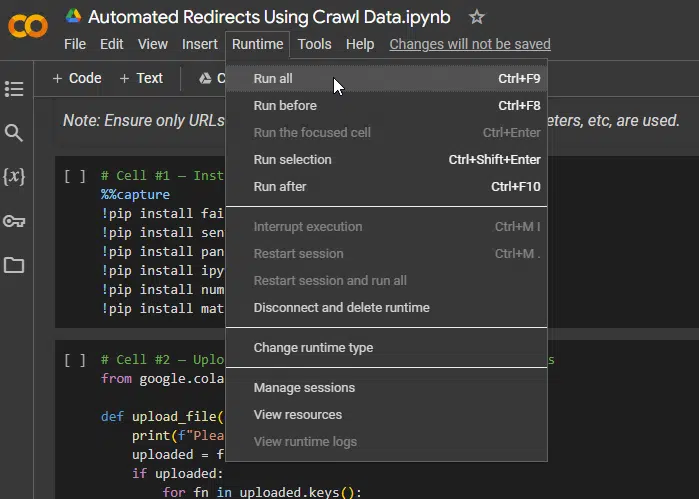
There are no prerequisites to run the script; it will create a cloud environment and on the first execution in your instance, it will take around one minute to install the required modules.
Each code block will have a small green tick next to it once it is complete, but the third code block will require your input to continue and it’s easy to miss as you’ll likely need to scroll down to see the prompt.
Get the daily newsletter search marketers rely on.
Step 5: Upload origin.csv and destination.csv
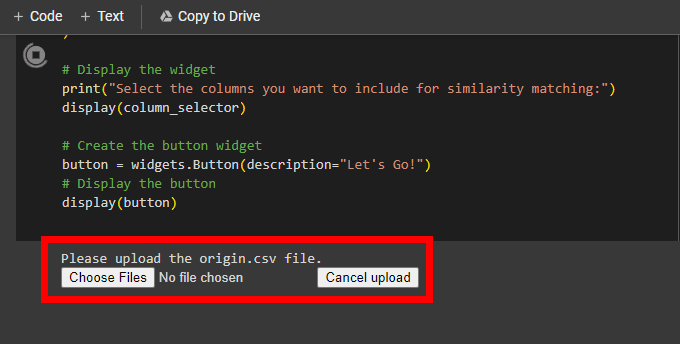
When prompted, click Choose files and navigate to where you saved your origin.csv file. Once you have selected this file, it will upload and you will be prompted to do the same for your destination.csv.
Step 6: Select fields to use for similarity matching
What makes this script particularly powerful is the ability to use multiple sets of metadata for your comparison.
This means if you’re in a situation where you’re moving architecture where your URL Address is not comparable, you can run the similarity algorithm on other factors under your control, such as Page Titles or Headings.
Have a look at both sites and try and judge what you think are elements that remain fairly consistent between them. Generally, I would advise to start simple and add more fields if you are not getting the results you want.
In my example, we have kept a similar URL naming convention, although not identical and our page titles remain consistent as we are copying the content over.
Select the elements you to use and click the Let’s Go!
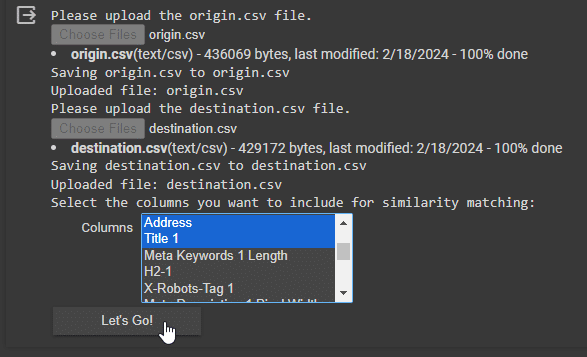
Step 7: Watch the magic
The script’s main components are all-MiniLM-L6-v2 and FAISS, but what are they and what are they doing?
all-MiniLM-L6-v2 is a small and efficient model within the Microsoft series of MiniLM ****** which are designed for natural language processing tasks (NLP). MiniLM is going to convert our text data we’ve given it into numerical vectors that capture their meaning.
These vectors then enable the similarity search, performed by Facebook AI Similarity Search (FAISS), a library developed by Facebook AI Research for efficient similarity search and clustering of dense vectors. This will quickly find our most similar content pairs across the dataset.
Step 7: Download output.csv and sort by similarity_score
The output.csv should automatically download from your browser. If you open it, you should have three columns: origin_url, matched_url and similarity_score.

In your favorite spreadsheet software, I would recommend sorting by similarity_score.
The similarity score gives you an idea of how good the match is. A similarity score of 1 suggests an exact match.
By checking my output file, I immediately saw that approximately 95% of my URLs have a similarity score of more than 0.98, so there is a good chance I’ve saved myself a lot of time.
Step 8: Human-validate your results
Pay special attention to the lowest similarity scores on your sheet; this is likely where no good matches can be found.

In my example, there were some poor matches on the team page, which led me to discover not all of the team profiles had yet been created on the staging site – a really helpful find.
The script has also quite helpfully given us redirect recommendations for old blog content we decided to axe and not include on the new website, but now we have a suggested redirect should we want to pass the traffic to something related – that’s ultimately your call.
Step 9: Tweak and repeat
If you didn’t get the desired results, I would double-check that the fields you use for matching are staying as consistent as possible between sites. If not, try a different field or group of fields and rerun.
More AI to come
In general, I have been slow to adopt any AI (especially generative AI) into the redirect mapping process, as the cost of mistakes can be high, and AI errors can sometimes be tricky to spot.
However, from my testing, I’ve found these specific AI ****** to be robust for this particular task and it has fundamentally changed how I approach site migrations.
Human checking and oversight are still required, but the amount of time saved with the bulk of the work means you can do a more thorough and thoughtful human intervention and finish the task many hours ahead of where you would usually be.
In the not-too-distant future, I expect we’ll see more specific ****** that will allow us to take additional steps, including improving the speed and efficiency of the next step, the redirect logic.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
Source link : Searchengineland.com