
As we’re all aware, generative AI has come to revolutionize our lives, our daily routines, and particularly the way we work. It’s as simple as choosing your preferred AI assistant and integrating it into your everyday tasks. Major companies like Google, Facebook, Microsoft, and OpenAI are in a race to develop increasingly precise AI systems that can yield better results, possess more capabilities, be “smarter”, and offer myriad features that make our work easier.
But have you ever wondered how this is possible? Many of you may be proficient in using these tools, but have you thought about what happens behind those engaging chat interfaces with artificial intelligences?
The goal of this blog post is to provide a brief review of some of the underlying technologies that have revolutionized and propelled the development of artificial intelligence over the years. With that in mind, let’s delve into a bit of history.
Evolution of AI and Deep Learning

Evolution of AI timeline
Statistics Era (Until the 1950s):

Statistic Era
In this early era, AI focused on symbolic logic and heuristic rules. Statistics played a pivotal role in the initial approaches to solving artificial intelligence problems. This era was characterized by the development of algorithms that could process and analyze data, which led to significant advancements in pattern recognition and decision-making processes. Such statistical techniques formed the cornerstone of initial problem-solving strategies in artificial intelligence, setting a robust framework for the subsequent evolution of the field.
Natural Language Processing (NLP) Era (1950s-1990s):

NPL Era
This era marked a significant shift in artificial intelligence as researchers delved into the complexities of human language. Efforts were concentrated on developing systems capable of comprehending and generating natural language through the use of intricate formal grammars and rule-based methodologies. Notable achievements of this time include Noam Chomsky’s revolutionary language theories, which provided a structural foundation for linguistic ******, and the SHRDLU project, an early natural language understanding program that could interact with virtual objects in a block world. These endeavors greatly enhanced the understanding of linguistic structures and contributed to the progressive sophistication of NLP applications.
Machine Learning Era (1990s-2010s):

Machine Learning Era
The dawn of this era was defined by a paradigm shift towards data-driven approaches, primarily through the advent and refinement of machine learning and artificial neural networks. This period was marked by substantial progress in the fields of computer vision and natural language processing, driven by the development and application of deep learning techniques. Innovations such as convolutional neural networks and recurrent neural networks paved the way for systems that could learn from vast amounts of data, leading to unprecedented accuracy in image and speech recognition tasks. These advancements not only revolutionized the capabilities of AI systems but also set the stage for practical applications that seamlessly integrated into daily life, such as digital assistants and advanced diagnostic tools. This era’s focus on probabilistic reasoning and algorithmic learning fostered a new wave of intelligent systems adept at handling complex, real-world tasks.
Introduction to Transformers in AI
Transformers
The Dawn of a New Era in Deep Learning
Transformers have stood at the forefront of the deep learning revolution, significantly transforming the landscape of natural language processing (NLP) and various other AI-driven tasks.
Some key points in the history:
- The Emergence of ELMo and Sequence-to-Sequence Mastery: First making their mark in 2017 with ****** like ELMo, transformers quickly became the go-to architecture for complex sequence-to-sequence challenges. From translating languages to summarizing extensive documents, their proficiency has been unparalleled.
- The Novelty of Self-Attention Mechanisms: What sets transformers apart from their predecessors is their unique utilization of self-attention mechanisms. This innovative approach allows them to efficiently process and understand the intricate relationships and dependencies between all elements in an input sequence.
- BERT: A Milestone in Language Processing: The introduction of BERT (Bidirectional Encoder Representations from Transformers) was a game-changer. By understanding the bidirectional context of language, BERT has significantly pushed the boundaries of what machines can comprehend and generate, leading to a deeper and more nuanced language understanding.
- Beyond NLP: A Versatile Architecture: The versatility of transformers is not confined to NLP. They have shown exceptional capabilities in fields like computer vision, speech recognition, and even reinforcement learning, paving the way for a future where their application is boundless and their impact, immeasurable.
Understanding Transformers in Deep Learning
Transformers have rapidly become a cornerstone in the field of deep learning, particularly within the realm of natural language processing (NLP). Their introduction marked a significant technological advancement in the way sequential data is processed and understood.
The Power of Self-Attention Mechanisms
At the heart of the Transformer model lies the self-attention mechanism, a sophisticated method that allows the model to weigh and understand the relationships and nuances within sequential data. This breakthrough has significantly expanded the capabilities of deep learning ******.
Self-Attention Mechanisms
A Paradigm Shift in Deep Learning
The Transformer’s architecture, distinct from its predecessors, doesn’t rely on recurrent or convolutional layers. Instead, it processes data points in parallel, drastically improving computational efficiency and model performance, especially in tasks involving long sequences of data.
The Seminal Work of Vaswani et al.
The groundbreaking paper “Attention Is All You Need” by Vaswani et al., published in 2017, unveiled the Transformer to the world. This pioneering work not only introduced a new architecture but also proposed a novel concept: in many cases, the self-attention mechanism alone, without recurrent or convolutional networks, could be sufficient for a wide array of tasks.
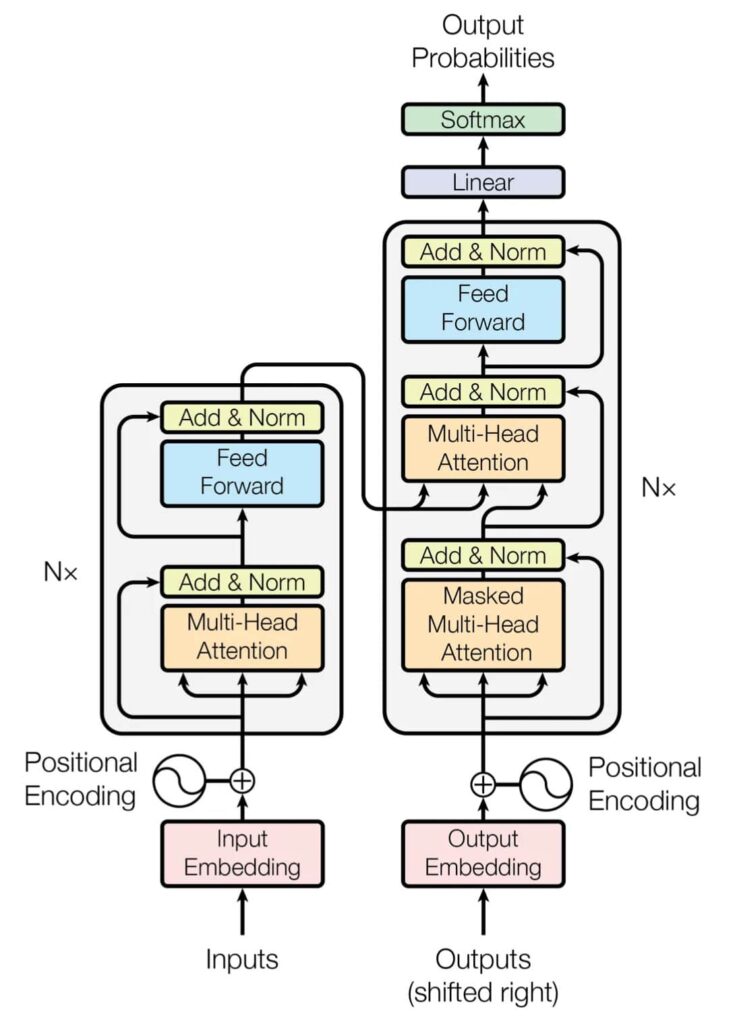
The Transformer — model architecture. [1]
Impact Across Fields
While Transformers were initially conceived for NLP tasks, their impact has rippled across various fields. Their ability to handle complex patterns in data has made them a preferred choice for challenges in language translation, content summarization, and even areas beyond NLP, such as image processing and generative tasks.
The Transformer model continues to be a subject of extensive research and application, pushing the boundaries of what artificial intelligence can achieve. Its influence extends through the vast expanse of deep learning applications, securing its place as a transformative force in the AI revolution.
As we continue to explore the depths of Transformer capabilities, one thing remains clear: the architecture has not only redefined expectations but also set a new standard for future innovations in the field of deep learning.
Basic Structure of Transformers
At its core, the Transformer model consists of two main components: Encoders and Decoders. Each of these plays a critical role in processing and generating sequential data, such as natural language text.

Transformer
Encoders: The First Half of the Equation
Encoders are designed to receive and process sequential input. In the context of natural language processing, this input is typically text.
Key Features of Encoders:
- Multi-Layered Attention and Transformations: Encoders use multiple layers, each consisting of a self-attention mechanism followed by linear transformations. This design helps the model to focus on different parts of the input sequence for a comprehensive understanding.
- Self-Attention Layers: These layers enable the encoder to weigh the importance of different words in a sentence, capturing the context and nuances of the language.
Decoders: Crafting the Output
Decoders are responsible for generating the sequential output, which could be in the form of translated text or any other sequence.
Key Features of Decoders:
- Masked Self-Attention Layer: This critical layer in the decoder prevents the model from ‘peeking’ into the future parts of the sequence, ensuring that the output is generated based solely on the preceding elements and the input from the encoder.
- Integration with Encoder Outputs: Decoders take information not just from their previous outputs but also from the encoders, facilitating a more context-rich and accurate generation of the output sequence.
The Synergy of Encoders and Decoders
The combination of encoders and decoders in the Transformer architecture allows for efficient and effective processing of sequential data. Each component complements the other, ensuring that the input is thoroughly understood and the output is accurately generated, maintaining the integrity and context of the sequence.
Transformers, with their encoders and decoders, continue to be a foundational element in numerous AI applications, from language translation to content generation, showcasing their versatility and effectiveness in handling complex sequential data.
Pre-training and Fine-tuning

Pre-training and Fine-tuning
When venturing into the complex world of Natural Language Processing (NLP), two concepts that stand as fundamental pillars are pre-training and fine-tuning. These techniques are part of a paradigm shift in how we develop ****** capable of understanding and generating language with human-like aptitude. They harness the remarkable ability of ****** like BERT to comprehend the nuances of human language.
Pre-training: Teaching the Basics of Language
Pre-training is akin to a student’s years of schooling before specializing in a particular field. In machine learning terms, it involves training a model, typically, a deep learning model, on an immense dataset. Think of it as a virtual library containing a vast expanse of human knowledge conveyed through language.
What happens during pre-training is quite fascinating:
- The model, for instance, BERT, gets fed with thousands, if not millions, of sentences.
- Its goal is to predict missing words in sentences, a task known as the masked language model objective.
- Throughout this process, the model is not just learning vocabulary but is also picking up on sentence structures, grammar, context, and the subtle interplay between words.
This stage results in a model that captures a broad knowledge of language. It understands the building blocks of communication, the “general” in general language understanding. Pre-training imbues the model with a depth of linguistic competence.
Fine-tuning: Specializing the Model’s Skills
Once the model has undergone its extensive pre-training, it’s time to fine-tune it to excel at specific tasks. The pre-trained model might have a solid grasp of language, but how do we make it an expert at understanding medical journals or discerning the sentiment behind product reviews?
This is where fine-tuning comes into play:
- The model now gets trained on a smaller, task-specific dataset.
- For example, if the goal is sentiment analysis, it would be exposed to texts labeled with sentiments.
- Fine-tuning typically requires less data than pre-training because the model is adapting its broad knowledge to a narrower domain.
Fine-tuning allows the pre-trained model to specialize, tailoring its vast understanding of language to a specific context. It’s what enables these NLP ****** to achieve high performance on a variety of tasks, from text classification to question answering, with relatively minimal additional data input.
The Importance of Pre-training and Fine-tuning
Combining pre-training with fine-tuning leverages the strengths of these large language ******. It’s a powerful approach that enables the development of NLP systems that are both highly competent in language capabilities and incredibly specialized in their application.
As the field of machine learning evolves, these techniques will continue to shape the landscape of NLP, making intelligent systems more accessible and more potent in their respective roles. For businesses, researchers, and developers, this means the opportunity to create advanced AI-driven solutions without the need for enormous datasets for every new task, saving both time and resources.
Tokenization
At its core, tokenization is the process of breaking down text into smaller, more manageable units, known as tokens. These tokens can be words, characters, or subword units, and they allow computer ****** to process and interpret text more effectively. It transforms raw unstructured text into organized data that can be fed into various language processing tasks, such as sentiment analysis, translation, or text generation.

Tokenization
Imagine trying to understand a speech without being able to distinguish individual words. That’s what raw text looks like to a computer without tokenization. By breaking down the text, tokenization makes it possible for machines to tackle the complexities of human language.
Types Of Tokenization
Tokenization comes in different levels, each suited to particular applications within NLP, usually tokenization tends to be a complex process, it can spend quite some time doing this. Here are the most common levels of tokenization:
Word-Level Tokenization:
- The most intuitive form of tokenization, where words are treated as tokens.
- Each word is separated based on spaces and punctuation, making it easy for tasks that rely on word frequency or presence.
- Useful for applications such as word clouds or basic text analysis.
Character-Level Tokenization:
- As implied, characters are treated as tokens.
- This level is useful when the structure of the word is important, such as in spelling correction or text generation ******.
- Language ****** can learn to generate or modify text one character at a time, allowing for a finer understanding of text patterns.
- This process compares to the other ones take a tremendous amount of time, and its recommended only on specific tasks like: when the structure of the word is important, such as in spelling correction or text generation ******.
Subword-Level Tokenization:
- This level falls between word and character tokenization.
- Some words are broken down into meaningful subword units or morphemes.
- It’s particularly useful for handling a mix of common words and rare words, as well as for morphologically rich languages where words have many different forms.
Embeddings
Embeddings are dense vectors of real numbers, one per word or phrase in the language, wherein each word is mapped to one vector and the vector values are learned in a way that resembles a neural network. Consequently, words that share common contexts in the corpus are located in close proximity to one another in the space.
Vectors
The Essence of Vector Representations
But what makes embeddings truly fascinating is their ability to capture the nuanced meanings and relationships of words. Through careful training, embeddings can encode aspects such as:
- Semantic Meaning: Words with similar meanings are positioned closer to each other in the embedding space.
- Contextual Nuance: Variations in word usage based on context are accounted for, allowing words to have different embeddings based on the surrounding words.
- Syntactic Information: Grammatical properties can also be embedded within this space, enabling understanding of parts of speech and tenses.
Advantages of Using Embeddings
Transforming words into vectors offers several advantages, including:
- Dimensionality Reduction: Embeddings map words to a lower-dimensional space as compared to the high-dimensional space where words are one-*** encoded.
- Generalization: By representing words in a continuous vector space, ****** can generalize from one word to another, leveraging the similarities in the embedding space.
- Improved Performance: Many NLP tasks see a boost in performance when using pre-trained embeddings, as they provide a more nuanced understanding of language than raw text alone.
Transformers Use Cases
Unlocking a myriad of use cases where they have significantly improved performance and accuracy. Here are some fascinating ways transformers are being applied across different domains:
Text Classification

Text Classification
Text classification serves as the cornerstone of numerous NLP applications, and transformers have enhanced its capabilities:
- Sentiment Analysis: Transformers are adept at gauging emotions within the text, designating sentiments as positive, negative, or neutral, which helps businesses understand consumer opinions on products and services.
- Topic Classification: These ****** can identify patterns and themes within the text, skillfully categorizing content into predefined topics, thus streamlining content management and discovery.
- Spam Detection: By recognizing common attributes of unwanted messages, transformers provide a robust defense against the deluge of spam, safeguarding our inboxes and communication channels.
Named Entity Recognition (NER)
NER is crucial for information extraction, as transformers can detect and classify specific entities mentioned in text such as names, organizations, dates, and more. This not only powers search and recommendation systems but also aids in data analysis and intelligence gathering.

NER example
Question Answering

Chatbot
From chatbots to virtual assistants, transformers have elevated the way machines can understand and respond to queries. Be it providing concise answers from large documents or engaging in meaningful conversations, their capabilities are impressive.
Semantic Similarity
Ensuring that the meaning of texts is accurately understood and compared, transformers are vital in applications like plagiarism detection, information retrieval, and linking similar content across vast databases.
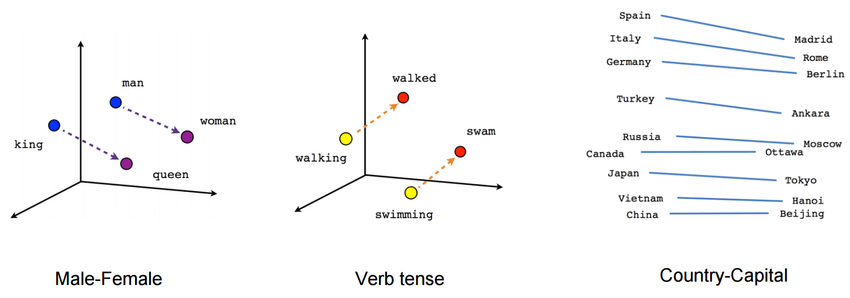
Implicite semantic term relationships in Word2Vec ****** [2]
Text Generation
The ability of transformers to generate coherent and nuanced text has led to innovations like automated content creation, dialogue systems, and even aiding writers with creative storytelling.
Text generation example
GPT (Generative Pretrained Transformer) is one such model that has taken the world by storm with its ability to produce text that’s often indistinguishable from that written by humans.
Machine Translation

Machine translation
Breaking down language barriers, machine translation powered by transformers facilitates real-time, accurate translation, fostering global communication and understanding.
Summarization

Summarization
Transformers excel at distilling the essence of lengthy texts into concise, informative summaries, which is key for digesting large volumes of information and staying updated in today’s fast-paced world.
Keyword Generation

Keyword cloud
Identifying keywords is a fundamental task in SEO, content analysis, and information retrieval. Transformers streamline this process by pinpointing relevant terms that capture the essence of texts.
Transformers Popular Architectures
BERT

Bert by Google [3]
BERT is a ground-breaking model introduced by Google in 2018 that considers the context from both the left and the right side of a token within text. Unlike previous ****** that processed words in a sequence one after another, BERT takes into account the full context of a word by looking at the words that come before and after it. This allows for a level of word understanding that closely mimics how humans interpret language.
BERT Use Cases
BERT’s versatility makes it a go-to for an array of NLP tasks. BERT can be adapted for different applications as:
- Text Classification (Sentiment Analysis, Topic Classification, Spam Detection)
- Named Entity Recognition (People, Organizations, Locations, etc…)
- Extractive Question and Answering
- Semantic Similarity
In essence, BERT is not just another step in the NLP journey; it’s a giant leap that’s opened up a world of possibilities. Developers and businesses can harness the power of BERT to perform a myriad of tasks that were once a pipedream, thereby creating more intuitive, efficacious, and intelligent systems that push the boundaries of machine-human interaction. As BERT and Transformer ****** continue to evolve, it’s clear that the future of NLP is bright and immensely exciting.
GPT

ChatGPT
Probably the most renowned architecture is the Generative Pretrained Transformer, or GPT, developed by OpenAI.
The GPT architecture is renowned for its ability to understand and generate human-like text. Unlike its predecessors, GPT doesn’t rely on traditional sequential data processing methods. Instead, it leverages attention mechanisms to process words in relation to all other words in a sentence, regardless of their position. This parallel processing capability, akin to how humans assimilate information, enables GPT to produce highly coherent and contextually relevant text.
GPT Use Cases
GPT cab be used for:
- Text generation (story generation, creative writing prompts, chatbot responses)
- Machine translation
- Summarization
T5: Text-to-Text Transfer Transformer
At the heart of the T5’s innovation is its unified text-to-text framework. T5 interprets every language task as a text conversion challenge, whether it’s translating languages, classifying text, or summarizing documents. This simplification of tasks into a consistent format allows T5 to operate with remarkable efficiency and agility.
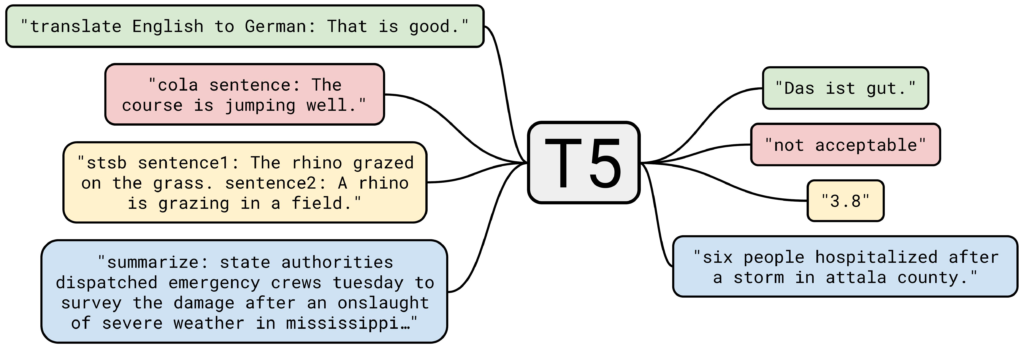
T5 – Transformer [4]
T5 is pre-trained on a colossal corpus of text in a self-supervised manner. Self-supervision enables the model to learn contextual relationships between words without the need for labelled data. This training regimen empowers T5 to generalize across a wide range of NLP tasks.
T5 Use Cases
- Machine Translation
- Keyword Generation (T5 can comprehend the essence of a text and derive keywords that encapsulate core information and context)
- Summarization
- Abstractive Question Answering
Transformers Distributions
Finally i want to share this interesting evolutionary tree of LLM’s (Large Language ******)
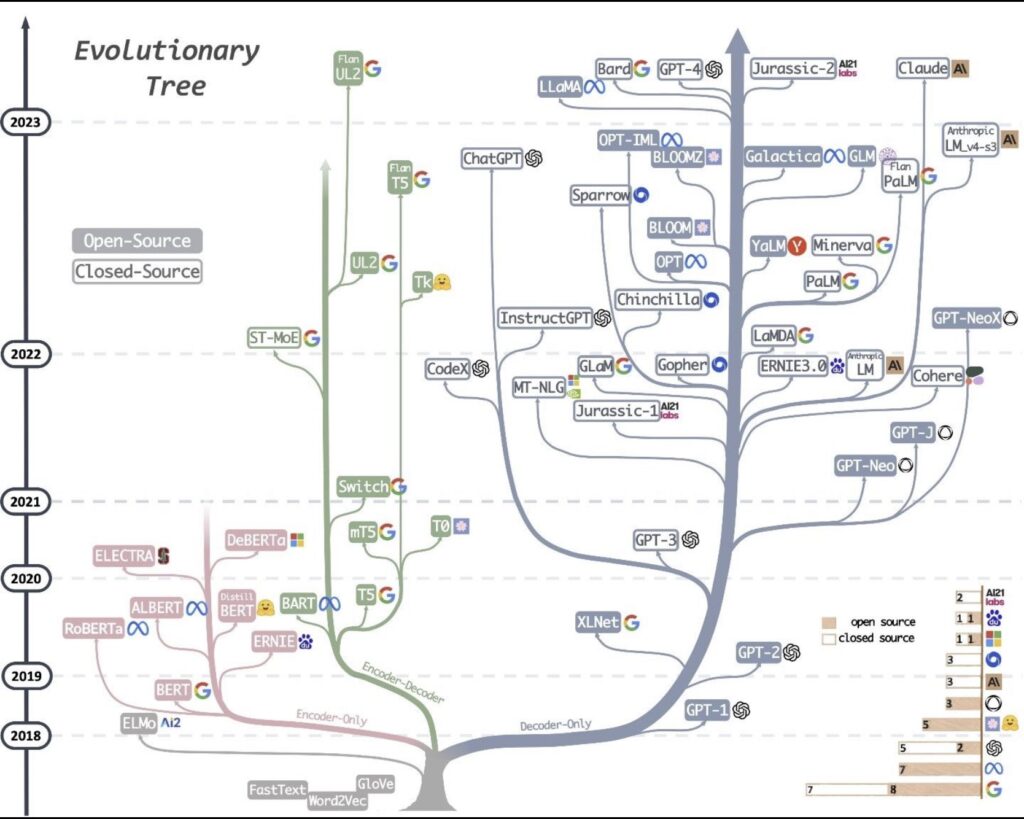
MML’s Evolutionary Tree [5]
Conclusion
As we stand at this juncture of technological advancement, it’s evident that transformers and their underlying technologies are not just a passing trend but a foundational aspect of modern AI. They will continue to shape the future of machine learning, opening new horizons for research, development, and application. The evolutionary tree of Large Language ****** (LLMs) is a testament to the rapid and ongoing growth in this field, hinting at a future where the possibilities and applications of AI are boundless.
In essence, as we embrace the transformative power of Generative AI and Transformers, we step into a future where AI is not just a tool but a partner in our quest to explore, understand, and innovate in an increasingly complex digital world.
Written by Andrés Castillo in collaboration with Cristian Sanchez Pineda and Jose Orjuela.
References
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2023). Attention Is All You Need. https://arxiv.org/abs/1706.03762
[2] Kurz, Thomas. (2020). Adapting Semantic Web Information Retrieval to Multimedia. https://www.researchgate.net/publication/343212226_Adapting_Semantic_Web_Information_Retrieval_to_Multimedia
[3] Making Bert Learn Faster. https://artalukd.medium.com/making-bert-learn-faster-d1a7be42ea1c
[4] Tarasiewicz, Piotr & Kenjeyev, Sultan & Sebag, Ilana & Alshehabi, Shehab. (2023). Adversarial Conversational Shaping for Intelligent Agents. https://www.researchgate.net/publication/372584231_Adversarial_Conversational_Shaping_for_Intelligent_Agents
[5] A fascinating tree of GPTs & LLMs reveals what’s been going on under the covers. https://medium.com/@paul.k.pallaghy/a-fascinating-tree-of-gpts-and-llms-reveals-whats-been-going-on-4d4235f2a2b1
[6] BERT Explained: State of the art language model for NLP. https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
[7] BERT: Google’s New Algorithm That Promises to Revolutionize SERPs. https://rockcontent.com/blog/google-bert/
[8] Transformer Neural Network Architecture. https://devopedia.org/transformer-neural-network-architecture
[9] Understanding T5 Model : Text to Text Transfer Transformer Model. https://towardsdatascience.com/understanding-t5-model-text-to-text-transfer-transformer-model-69ce4c165023
[10] Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer. https://blog.research.google/2020/02/exploring-transfer-learning-with-t5.html?m=1
[11] T5: a detailed explanation. https://medium.com/analytics-vidhya/t5-a-detailed-explanation-a0ac9bc53e51
[12] Comparison between BERT, GPT-2 and ELMo. https://medium.com/@gauravghati/comparison-between-bert-gpt-2-and-elmo-9ad140cd1cda