
In Spark with Scala, creating DataFrames is fundamental for data manipulation and analysis. There are several approaches for creating DataFrames, each offering its unique advantages. You can create DataFrames from various data sources like CSV, JSON, or even from existing RDDs (Resilient Distributed Datasets). In this blog we will see some approaches towards creating dataframe with examples.
Understanding Spark DataFrames:
Spark DataFrames are a fundamental member of Apache Spark, offering a higher-level abstraction built on top of RDD. Their design aims to offer a more efficient processing mechanism for managing large-scale structured data.
Let’s explore the different methods for creating the dataframes:
Creating DataFrame from a Collection:
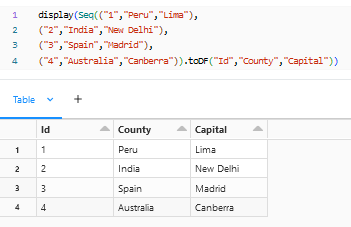
DataFrames intended for immediate testing can be built on top of a collection.
In this case the dataframe is built on top of a Sequence.
DataFrame Creation using DataFrameReader API:
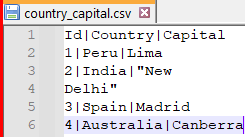
The shown below is the dataset that will be used to explore creating DataFrames using DataFrameReader API.
Creating a Dataframe from CSV/TXT Files:
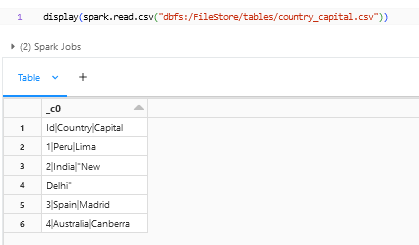
We can directly use “spark.read.csv” method to read the file into a dataframe. But the current data cannot be loaded directly into table or other downstream. The headers and delimiters need to be put as separate options to get the data properly loaded into the dataframe. Let’s go through the options that are available and get the data to a proper format below.
Options:
By default, the header option will be false in the Spark Dataframe Reader API. Since our file has header, we need to specify the option – option(“header”,” true”) to get the header. Sometimes if the header option has been missed and the file has a header there is a chance that the header might go as a row and get stored in the table.
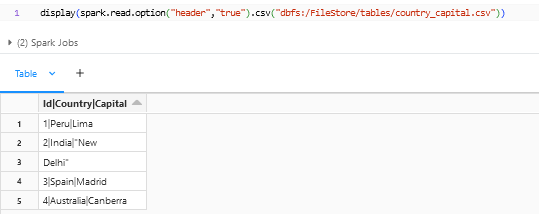
The delimiter option will be “,” by default. The sample file that we have provided has “|” as its delimiter so it needs to be explicitly called out using the option – option(“delimiter”,”|”) to get the columns splitted.
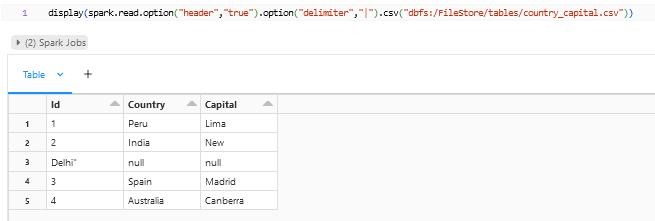
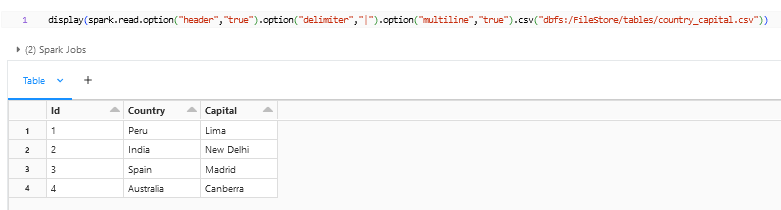
As you see in the above snapshot that the data is splitted and assigned to individual columns and rows, though the Capital for India New Delhi is splitted into two rows because by default the multiline option would be set to false. If we have this kind of multiple lines coming from the file then we can enable the multiline option by using this option – option(“multiline”, “true”).
The schema of the dataframe can be viewed by using “.printSchema” method.

From the above snapshot we can see that the datatype for the column “Id” being referred as string though the datatype that we are seeing in the files is integer. This is because the inferSchema will be set to false when reading the file. “inferSchema” is nothing but the DataFrameReader, which will go through the data and finds the datatype of the column. We can also enforce the Schema of the dataframe by creating a Schema using StructType and passing it through “.schema” method. Both the methods are shown below.
- inferSchema: We can set the inferSchema to true by including this option – option(“inferSchema”,”true”), which in turn will make the DataFrameReader to go through the data and find the datatype.

- Defining Schema: We can enforce the schema by using the “.schema” method for which we will define the schema and pass it on when reading the file, by which we can control the datatype of the columns. If there is a datatype mismatch when enforcing the data in the column then null will be populated.

The “spark.read.csv” with options can be used to read the txt or txt.gz files, which will return us the dataframe. If we have the proper text file within the zip, then we can directly read them as dataframes without unzipping it.
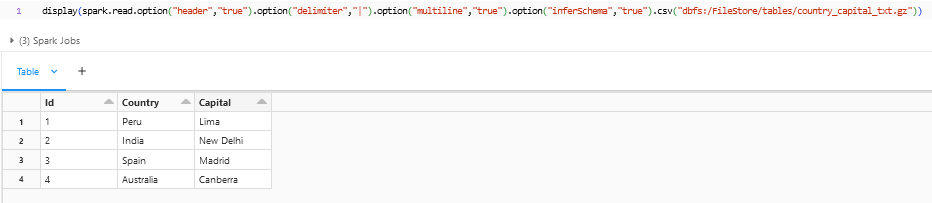
- Reading csv with a different Format:
The “spark.read.format(“csv”).load” can be also used instead of spark.read.csv. Both are same functions but with a different syntax.
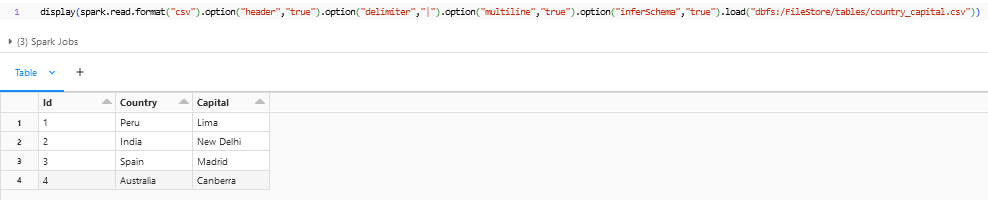
The above are some of the options that are present when reading the file into a dataframe, few more options which was not shown here are escapeQuotes, unescapedQuoteHandling, quote, escape, mode, nullValue, lineSep.
Creating a Dataframe from json Files:
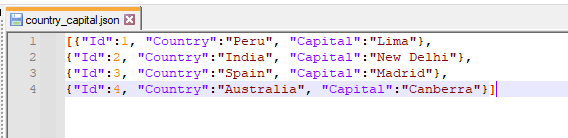
The below is the json file snapshot that will used for the examples.
The DataFrameReader can be used for reading the json into a dataframe by using “spark.read.json()”.
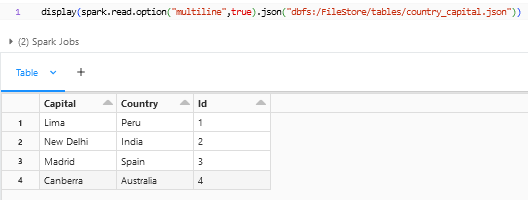
In the above snapshot we can see that the dataframe is arranged using the alphabetical order of the column names, which we can change to the desired format with Id in the first followed by country and capital as in the json.
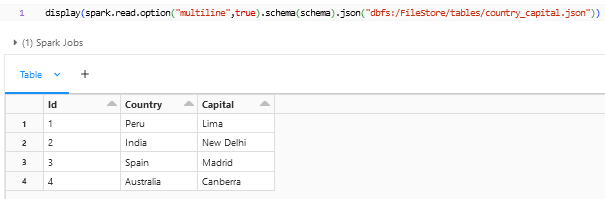
With the schema defined we can see that the columns are in alignment and can be transformed if needed and stored into a table.
The DataFrameReader can also be used to read files of parquet, orc and also, we can connect to different databases using the jdbc connection and read them into the dataframe.
Conclusion:
In conclusion, creating DataFrames in Spark using Scala involves various approaches, each tailored to specific requirements and preferences. The DataFrame API provides a flexible and intuitive interface for data manipulation and analysis, offering both functional and declarative programming paradigms.
The DataFrame creation process can include reading data from diverse sources, such as CSV files, JSON, Parquet, or even external databases. Once the DataFrame is created, you can use the powerful Spark SQL capabilities to execute SQL queries directly on your DataFrames and perform your transformations before using them in the downstream. Overall, the flexibility and scalability of Spark Scala’s DataFrame API empower data engineers and analysts to efficiently process and analyse large-scale datasets within the Spark ecosystem.