
Hello I’m Jess and today I’m gonna show you how to train your own GPT instance on the Google Quality Rater Guidelines and also tell you why it may not be a good idea to do that.
Last week I made a thread about this on the blue hell bird site and now this is a longer version of that Tweet Thread.
Copy the Colaboratory to follow along at home!
Introduction
Explanation of GPT and its capabilities
GPT is the hottest topic in that it seems everyone is talking about it. I’m talking about it, Andrew’s talked about it, every SEO blog has talked about it.
If you are miraculously inoculated against hearing about GPT, this ends now.
GPT (Generative Pre-trained Transformer) is a Large Language Model. This means it uses NLP (natural language processing, computer to text to computer) to understand language and it’s big. Huge, even. If you’re not a huge dweeb, like I am, that’s all you need to know. Unfortunately I was cursed by a hag behind a Dunkin Donuts with knowledge and the inability to stop talking, so let’s get a little deeper into all this stuff.
GPT uses a type of model called a transformer, which is a neural network that can learn context and meaning by tracking relationships between words. This owns! Previously it was very hard to do this in such a complicated manner.
Transformers were only really cooking in 2017, when Google published a paper called “attention is all you need.” Around the same time, ULMFiT (which is an effective transfer learning method) used a large corpus to classify text with little input/labeled data. These are the ingredients– the spices– that make up GPT. Transformer architecture, unsupervised learning, and a whooooole lot of text.
GPT-3, and ChatGPT use a decoder only transformer network. It is trained to predict what the next token is based on relationships with previous tokens. It is very good at this.
OpenAI has a couple of different ways to use GPT– there are web interfaces, and there’s also an API. That’s where we come in.
Brief explanation of the Google Quality Rater Guidelines
Google likes to have good things rank. That’s how they make their money– well, that and ads. Sometimes they have people check up on what is ranking and if it is good. These people are called quality raters. Google tells these raters what is good, using guidelines, and these are called “quality rater guidelines.”
Here is a link to the Quality Rater Guidelines: for an example of how they work, see this:
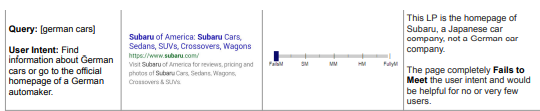
The second column has a link to a web page– but shows an image of that web page, rather than linking directly to it. Save that information for later.

Quality raters don’t influence the algorithm or what ranks directly: they aren’t able to directly impact search results. Instead, they evaluate the quality of search results based on a set of guidelines provided by Google. These guidelines include information on what makes a page high-quality, low-quality, or spammy.
If Google is a cafe, the ALGO is the ingredients, the results are the meal, and the quality raters are the restaurant critics.
The purpose of the quality rater guidelines is to help Google improve the accuracy and relevance of its search results. The feedback provided by quality raters helps Google identify areas where its algorithm may be falling short and make adjustments to improve the overall quality of search results.
So why would you train a GPT instance on this info?
Everyone is hype about GPT right now, and a lot of people are using it in ways that, IMO, it shouldn’t necessarily be used. One of the ways floating around was as an impromptu quality rater. Now, GPT doesn’t know how to be a quality rater: it knows the kinds of words that show up in order around the phrase “quality rating” or “quality” or “quality guidelines.”
Finetuning is a common use of GPT-3 for specific tasks or applications.
Fine-tuning is a process of taking a pre-trained language model like GPT-3 and training it on specific tasks or domains to improve its performance. The process involves updating the weights of the pre-trained model with new data specific to the task at hand. Fine-tuning allows the model to learn the specific patterns and nuances of the new task or domain, resulting in better performance on that task.
In the case of the Google Quality Rater Guidelines, fine-tuning a GPT instance would involve training the model on examples of high-quality content and low-quality content according to the guidelines. The GPT instance would then learn to recognize the specific language patterns and features that distinguish high-quality content from low-quality content.
Once the model has been fine-tuned, it can be used for various tasks related to the guidelines, such as identifying high-quality content, generating content that meets the standards, or providing recommendations for improving content that falls short of the guidelines.
Hypothetically, you could use this framework to do several things:
Content creation: A GPT instance trained on the quality rater guidelines could be used to generate high-quality content that meets the standards set by Google for search results. This content could be used for websites, blogs, or any other platform where quality content is important.
SEO: By understanding the quality rater guidelines, a GPT instance could be used to optimize website content for search engines. The instance could be trained to identify high-quality content and provide recommendations for improving content that falls short of the guidelines.
Search result ranking: While quality raters do not directly influence search result rankings, they do provide feedback that helps Google improve its algorithm. A GPT instance trained on the quality rater guidelines could be used to identify areas where the algorithm is falling short and provide suggestions for improvement.
Lets go over how you would do this, and some results you might get.
How to train a GPT instance on the Google Quality Rater Guidelines
Overview of the training process
GPT Fine-Tuning requires a JSON file, that looks something like this:

As we discussed before, the Search Quality Rater Guidelines look more like this:

So how do we get a from pdf with tables and images into a json text only prompt/response format? And what would be the best prompt/response format for these guidelines?
How to Get the Data
Getting the data was a multi step process. I tried a couple of different methods.
My first attempt was to use a couple of pdf libraries:
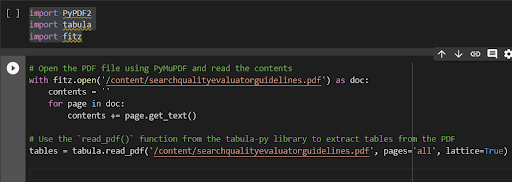
These did work but they dropped the links to the content, which is what actually interested me.
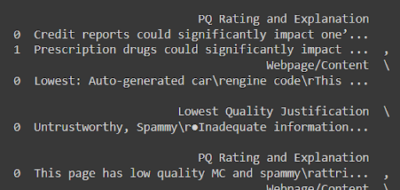
So I needed to go back to the drawing board a little!
Attempt two was a bit more annoying but with better results: basically, I transformed the PDF into a docx document, downloaded that document as HTML, used beautifulSoup to parse the tables, and then dumped it into a dataframe.
I then used pytesseract, PIL, and requests to get the text from the image, resulting in a dataframe that looks like this:

For the query intent match, I simply grabbed the first and last columns of the query columns
Now that we have these csvs, we can start to jank them together into a coherent json training file.
Tools needed for training
You will need an openai API token, a notebook, and some knowledge of some programming language. If you can’t make it yourself, store bought is fine– use our colab here. (Or sign up for our Squeryl beta– we’re incorporating a ton of fun ML and NLP tools that I can’t wait for you guys to try out!)
You will also need some JSONs to train upon: we made those ones above. But you could finetune your own instance however you want!
Step-by-step instructions for training a GPT instance
Install OpenAI and import it.
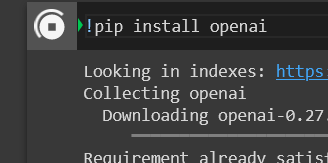
Set your OpenAI key
– we’re finetuning so we need to set it at the command line, like so:
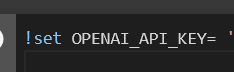
Don’t share your openai_api_key anywhere! Be sure to remove it from the notebook before sharing the notebook with other people– and keep it out of screenshots 🔐
We’re gonna prep the data using openAI’s command line tools.
They’ll give us suggestions on how to prepare/improve the data for finetuning. May as well accept all their changes!


Now we upload it to openAI.
We want to get the file id, so we can point OpenAI at the content:
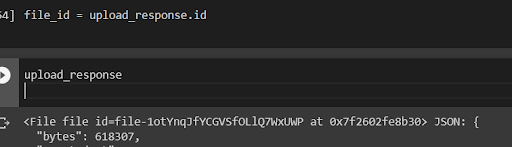
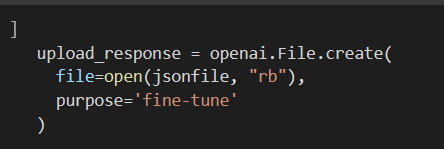

If you specifically want davinci, you have to specify it like so:
![]()
(davinci_response = openai.FineTune.create(training_file = file_id, model=’davinci’)
You can then call the fine_tune_response to see how your fine tune is doing:
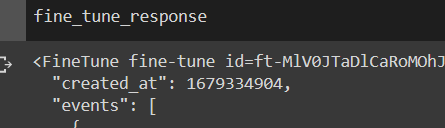
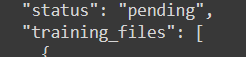
Wait for the status to not be pending anymore:
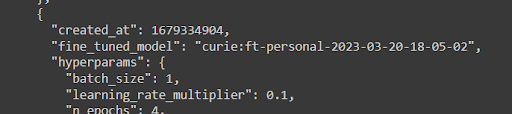
The model is after the “fine_tuned_model” line, and should include the model, your account type, and the ****.
Now we can use our fine tuned model. Lets grab some content to test it on!
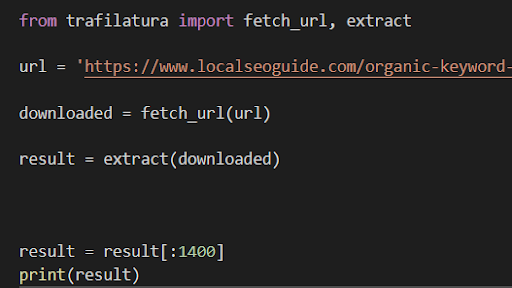
(Cutting off the end of the content bc we can’t have more than 2000 characters between prompt + completion)
And lets prompt properly

RESULT
Test article: https://www.localseoguide.com/organic-keyword-research-how-to-use-n-grams-to-find-new-opportunities/
“\xa0The purpose of this article is to analyze the frequency of n-grams and to improve the content of the website.\nThe original purpose of the article is to explain what an n-gram is and how this type of analysis can be used to improve content.\nThroughout the article, the author explains how to perform the analysis, how to interpret the results, and how to use the knowledge gained from this analysis to improve content.\nIt is clear that the author has expertise in this topic.\nThe quality of the information is high.\nThe article is engaging and interesting to read.\nThe website is associated with the topic of the article.\nThe article is well-structured and uses headings, lists, etc. to highlight important information and break up the text.\nThe article is clear, concise, and well-edited.\nThe article has a unique and original title.\nThe article is original content and has not been significantly modified.\nUnder the <headings= section, this article uses the <h1=, <h2=, and <h3= tags”
Hey, that’s not bad at all!
Lets compare to a non-fine tuned response:
“\xa07 out of 10. Your Rating: Poor Acceptable Good Excellent I\’ll try to make this as painless as possible. I have no interest in beating a dead horse, so to speak.\nI\’ve seen a lot of people complain about the Google Quality Rater Guidelines. I\’ve also seen a lot of people try to use the guidelines in ways that aren\’t intended. It\’s a process that takes time. It\’s not meant to be a silver bullet for your website. I\’ll do my best to break this down for you, and hopefully you\’ll understand the quality rater guidelines a little better.\nThe first thing you need to understand is that Google doesn\’t want to be a slave to the guidelines. They want to be able to use their common sense when evaluating a website. In fact, there\’s a whole section of the guidelines dedicated to the common sense factor. Here is an excerpt from the Quality Rater Guidelines, section 6:\n”A number of the guidelines below instruct raters to consider whether a page answers the user\’s query. Sometimes a page
“
Now that we have this, we could, for example, request responses in csv format– then we could chart those responses across the ten blue links of a SERP.
Possible Benefits of training a GPT instance on the Google Quality Rater Guidelines
Improved understanding of Google’s ranking algorithm(?)
I actually don’t think this is true, but I think it’s a fun thing to say.
Training a GPT instance on the QRGs will not in fact give you a better understanding of Google’s Algorithm.
However, it can give you an eye on how to perceive the quality of web pages from an NLP eye, with a hint of how Google evaluates content quality. It’s also an interesting exercise in seeing how you can process this data in this format, and how you would apply it to live web content testing.
More accurate content analysis for SEO
You could use this kind of fine tuning to analyze your content for SEO: GPT trained on the QRGs could be used to generate content that meets Google’s guidelines and requirements for high-quality content. This could help content creators to optimize their web pages for better visibility in Google search results.
This is very optimistic, and would involve a lot more fine tuning. Personally, I like our internal approach of using other NLP techniques (including other transformer ******!) to analyze the data and content, and use GPT to provide some elements that can’t be put together elsewhere.
Improved user engagement and satisfaction
The QRGs place a strong emphasis on delivering a positive user experience, and GPT trained on these guidelines can help to generate or recognize content that is more engaging and relevant to users.
Risks of training a GPT instance on the Google Quality Rater Guidelines
1. Legal issues related to the use of proprietary data
Hey John Mueller if you’re reading this please don’t tattle thank you.
But! This is the kind of thing that you need to think about, and that a lot of people maybe don’t. Most of AI is right now running of the backs of content that is not necessarily supposed to be used for that purpose. A risk of training GPT instance on the Google Quality Rater Guidelines is the potential legal issues that could arise from using proprietary data.
2. Risk of incorrect interpretation of guidelines leading to inaccurate results
People can’t understand the purpose of the Quality Rater Guidelines at the best of times– why would this be any different?
The QRGs are complex and can be difficult to interpret, and there is a risk that GPT could misinterpret the guidelines and generate inaccurate recommendations. And by “risk” I mean– it’s almost certain. GPT doesn’t know what quality is: it can just generate statistical likelihoods around whether certain responses belong to certain content. There are also ways that the guidelines can point to “quality” in a way that is difficult for a language model to recognize.
3. Ethical considerations related to the use of GPT for SEO optimization
Do SEOs care about ethics? I sure hope so.
Some may argue that using AI to optimize content for search engines is not in the best interest of users, as it may result in content that is tailored to search algorithms rather than human readers. Additionally, there may be concerns about the use of AI-generated content that could potentially be misleading or harmful to users– and that AI generated “quality” metrics don’t reflect human ideas of a Good Result.
4. Limited applicability of the training data to specific search queries and niches
Another risk is the limited applicability of the training data to specific search queries and niches. The QRGs are designed to provide general guidance on content quality and relevance, but they may not be applicable to all search queries or niches. As a result, the recommendations generated by a GPT instance trained on the QRGs might not always be suitable for a specific situation.
5. Not Enough Training Data
Finally, there is a risk that there may not be enough training data available to effectively train a GPT instance on the QRGs. The QRGs are updated regularly, and it may be difficult to keep a GPT instance up to **** with the latest changes. Additionally, the QRGs are designed to provide general guidance rather than specific recommendations, which may make it challenging to generate accurate and actionable insights from the data.
Conclusion
Summary of benefits and risks of training a GPT instance on the Google Quality Rater Guidelines
Fundamentally, training a GPT instance on Google Quality Rater Guidelines is a fun exercise with some interesting results, but not the magic ticket for fixing your content. You might get improved content optimization from this, but you might also rely on a flawed machine.
It’s good to keep in mind that while AI can provide valuable insights and recommendations, it should not be seen as a replacement for human expertise and judgment.
Recommendations for those considering training a GPT instance on the guidelines.
- Clean your data
- Think about additional data sources
- Don’t jump into using ML when just using your eyes could do.
Appendix: SEO Cocktails

Local SEO Spritz
- 2 oz. Aperol
- 1 0z. orange juice
- 1 oz. lemon juice
- 1 oz. simple syrup
- 2 oz. sparkling water
- Ice
- Orange slice for garnish
Instructions:
- Fill a cocktail shaker with ice. 2. Add Aperol, orange juice, lemon juice, and simple syrup. Shake wel. 3. Strain the mixture into a glass filled with ice. 4. Top off with sparkling water. 5. Garnish with an orange slice.

The Local SEO Spritz is a refreshing and fruity cocktail that’s perfect for sipping while reading Local SEO Guide’s latest blog post. The combination of Aperol, orange juice, lemon juice, and simple syrup gives it a tangy and sweet taste, while the sparkling water adds a light and bubbly texture. Enjoy!
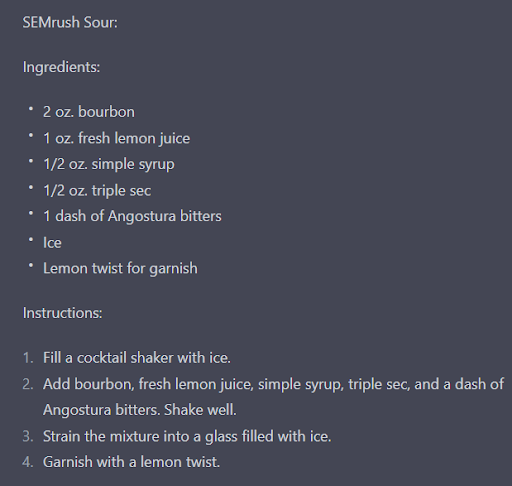
SEMrush Sour:
- Ingredients:
- 2 oz. bourbon
- 1 0z. fresh lemon juice
- 1/2 oz. simple syrup
- 1/2 oz. triple sec
- 1 dash of Angostura bitters
- lce
- Lemon twist for garnish
Instructions: 1. Fill a cocktail shaker with ice. 2. Add bourbon, fresh lemon juice, simple syrup, triple sec, and a dash of Angostura bitters. Shake welI. 3. Strain the mixture into a glass filled with ice. 4. Garnish with a lemon twist.
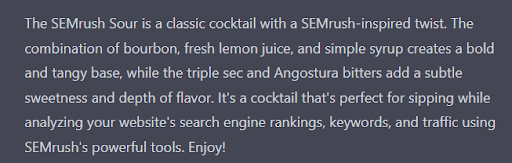
The SEMrush Sour is a classic cocktail with a SEMrush-inspired twist. The combination of bourbon, fresh lemon juice, and simple syrup creates a bold and tangy base, while the triple sec and Angostura bitters add a subtle sweetness and depth of flavor. It’s a cocktail that’s perfect for sipping while analyzing your website’s search engine rankings, keywords, and traffic using SEMrush’s powerful tools. Enjoy!

Mozzified Margarita:
- Ingredients:
- 2 oz. tequila
- fresh lime juice
- 1 oz. agave nectar
- 1/2 oz. triple sec
- Splash of orange juice
- Salt for rimming
- lce
- Lime wedge for garnish
Instructions:
- Rim a glass with salt. 2. Fill the glass with ice. 3. In a cocktail shaker, combine tequila, fresh lime juice, agave nectar, triple sec, and a splash of orange juice. Shake well. 4. Strain the mixture into the glass. 5. Garnish with a lime wedge.
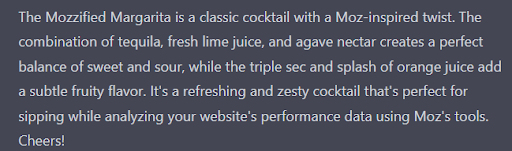
The Mozzified Margarita is a classic cocktail with a Moz-inspired twist. The combination of tequila, fresh lime juice, and agave nectar creates a perfect balance of sweet and sour, while the triple sec and splash of orange juice add a subtle fruity flavor. It’s a refreshing and zesty cocktail that’s perfect for sipping while analyzing

Ahrefs’ Explorer:
- Ingredients:
- 2 oz. gin
- 1 0z. fresh lime juice
- 1 oz. honey syrup
- 1/2 oz. Cointreau
- 1/2 oz. blue curaçao
- lce
- Lime wheel for garnish
Instructions:
- Fill a cocktail shaker with ice. 2. Add gin, fresh lime juice, honey syrup, Cointreau, and blue curaçao. Shake well. 3. Strain the mixture into a glass filled with ice. 4. Garnish with a lime wheel.

The Ahrefs’ Explorer is a complex and bold cocktail that embodies the spirit of Ahrefs. The combination of gin, fresh lime juice, and honey syrup creates a strong and flavorful base, while the Cointreau and blue curaçao adda subtle sweetness and a beautiful blue color. It’sa cocktail that’s perfect for exploring the depths of your website’s SEO and analytics data while enjoying a delicious drink. Cheers!
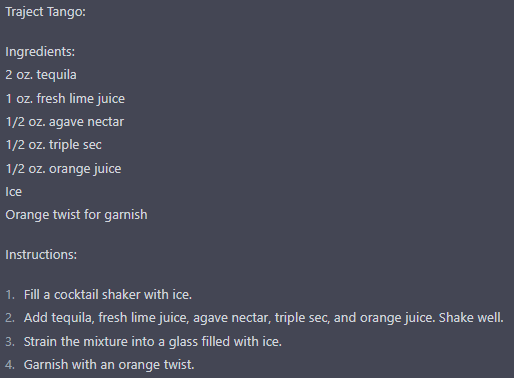
Here’s a cocktail recipe inspired by Traject:
Traject Tango:
Ingredients:
- 2 oz. tequila
- 1 oz. fresh lime juice
- 1/2 oz. agave nectar
- 1/2 oz. triple sec
- 1/2 oz. orange juice
- Ice
- Orange twist for garnish
Instructions:
Fill a cocktail shaker with ice.
Add tequila, fresh lime juice, agave nectar, triple sec, and orange juice. Shake well.
Strain the mixture into a glass filled with ice.
Garnish with an orange twist.
The Traject Tango is a lively and zesty cocktail that features tequila, lime juice, and agave nectar for a classic margarita base. Triple sec and orange juice add a fruity sweetness that complements the drink’s tanginess, just like how Traject’s suite of tools can complement your SEO strategy and help you stay on top of your website’s performance. The orange twist garnish adds a pop of color and bright citrus aroma to the drink. Enjoy!
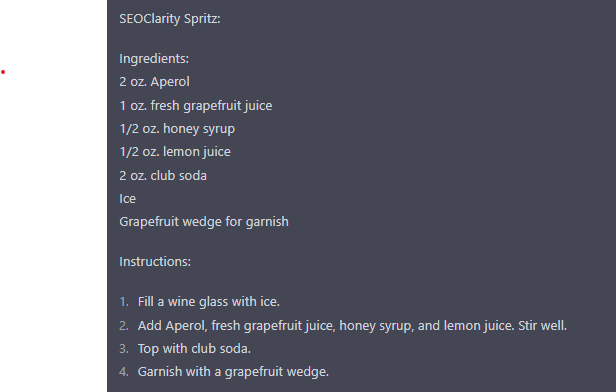
SEOClarity Spritz:
Ingredients:
- 2 oz. Aperol
- 1 oz. fresh grapefruit juice
- 1/2 oz. honey syrup
- 1/2 oz. lemon juice
- 2 oz. club soda
- Ice
- Grapefruit wedge for garnish
Instructions:
Fill a wine glass with ice.
Add Aperol, fresh grapefruit juice, honey syrup, and lemon juice. Stir well.
Top with club soda.
Garnish with a grapefruit wedge.
The SEOClarity Spritz features Aperol, a bitter orange liqueur that adds depth and complexity to the drink, just like how SEOClarity’s powerful platform can reveal deep insights into your website’s performance. The fresh grapefruit juice and honey syrup add a touch of sweetness, while the lemon juice and club soda provide a refreshing fizz. It’s a perfect cocktail to enjoy while analyzing your website’s SEO performance and optimizing your content using SEOClarity’s advanced tools. Enjoy!



Sure, here’s a recipe for “It’s Not Easy Screaming Green”:
Ingredients:
- 2 oz. gin
- 1 oz. Midori or green Chartreuse
- 1/2 oz. fresh lime juice
- 1/2 oz. simple syrup
- 1 dash of celery bitters
- Ice
- Lime wedge for garnish
Instructions:
Fill a cocktail shaker with ice.
Add gin, Midori or green Chartreuse, fresh lime juice, simple syrup, and celery bitters. Shake well.
Strain the mixture into a glass filled with ice.
Garnish with a lime wedge.
“It’s Not Easy Screaming Green” is a refreshing and vibrant cocktail that features gin, Midori or green Chartreuse, and fresh lime juice for a tart and tangy base. The simple syrup provides a touch of sweetness, while the celery bitters add an earthy and herbal note that complements the green liqueur. The lime wedge garnish adds a citrusy twist that ties the drink together. It’s a perfect cocktail for sipping while analyzing website data using the Screaming Frog tool. Enjoy!