
Read it again: there was no leak. The information was shared with industry veterans.
It certainly is a treasure map for SEOs. Solving this puzzle will require our collective insight, critical thinking and analysis – if that’s even possible.
Why the pessimism?
It’s like when a chef tells you the ingredients to the delicious dish you’ve just consumed. You hurry to note it all down as he turns away.
But when you try recreating the same recipe at home, it’s nowhere near what you experienced at the restaurant.
It’s the same with the Google document “leak.” My perspective is our industry was given the types of ingredients used to determine the top search results, but no one knows how it’s all put together.
Not even the brightest two among us who were given access to the documentation.
If you recall…
In May, thousands of internal documents, which appear to have come from Google’s internal Content API Warehouse, claimed to have been leaked (per publication headlines).
In reality, they were shared with prominent industry SEO veterans, including Rand Fishkin, SparkToro co-founder. Fishkin outright acknowledged in his article that the information was shared with him.
In turn, he shared the documentation with Mike King, owner of iPullRank. Together and separately, they both reviewed the documentation and provided their own respective POVs in their write-ups. Hence, my take on all of this is that it’s strategic information sharing.
That fact alone made me question the purpose of sharing the internal documentation.
It seems the goal was to give it to SEO experts so they could analyze it and help the broader industry understand what Google uses as signals for ranking and assessing content quality.
“You don’t pay a plumber to bang on the pipe, you pay them for knowing where to bang.”
There’s no leak. An anonymous source wanted the information to be more broadly available.

Going back to the restaurant metaphor, we can now see all the ingredients, but we don’t know what to use, how much, when and in what sequence (?!), which leaves us to continue speculating.
The reality is we shouldn’t know.
Google Search is a product that’s part of a business owned by its parent company, Alphabet.
Do you really think they would fully disclose documentation about the inner workings of their proprietary algorithms to the world? That’s business suicide.
This is a taste.
For established SEOs, the shared Google documentation that’s now public sheds light on some of the known ranking factors, which largely haven’t changed:
- Ranking features: 2,596 modules are represented in the API documentation with 14,014 attributes.
- Existence of weighting of the factors.
- Links matter.
- Successful clicks matter.
- Brand matters (build, be known).
- Entities matter.
Here’s where things get interesting because the existence of some aspects means Google can boost or demote search results:
- SiteAuthority – Google uses it but also denied having a website authority score
- King’s article has a section called “What are Twiddlers.” While he goes on to say there’s little information about them, they’re essentially re-ranking functions or calculations.

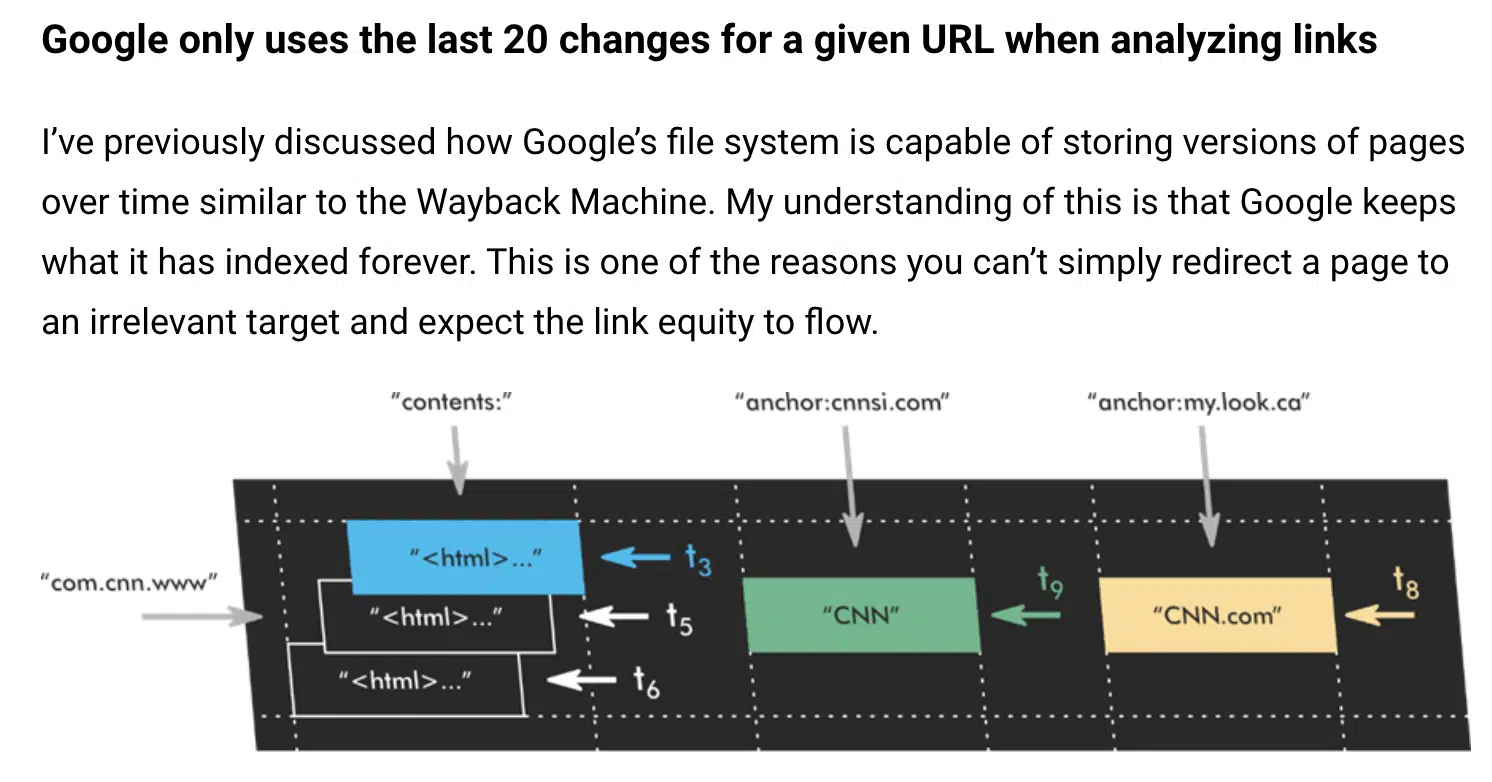
- King’s article “Google only uses the last 20 changes of a URL when analyzing links.” Again, this sheds some light on the idea that Google keeps all the changes they’ve ever seen for a page.
Both Fishkin and King’s articles are lengthy, as one might expect.
If you’re going to spend time reading through either articles or – tip of the cap to you – the documents themselves, may you be guided by this quote by Bruce Lee that inspired me:
“Absorb what is useful, discard what is not, add what is uniquely your own.”
Which is what I’ve done below.
My advice is to bookmark these articles because you’ll want to keep coming back to read through them.
Rand Fishkin’s insights
I found this part very interesting:
“After walking me through a handful of these API modules, the source explained their motivations (around transparency, holding Google to account, etc.) and their hope: that I would publish an article sharing this leak, revealing some of the many interesting pieces of data it contained and refuting some “lies” Googlers “had been spreading for years.”
The Google API Content Warehouse exists in GitHub as a repository and directory explaining various “API attributes and modules to help familiarize those working on a project with the data elements available.”
It’s a map of what exists, what was once used and is potentially currently being used.
Which ones and when is what remains open to speculation and interpretation.
Smoking gun
We should care about something like this that’s legitimate yet speculative because, as Fishkin puts it, it’s as close to a smoking gun as anything since Google’s execs testified in the DOJ trial last year.
Speaking of that testimony, much of it is corroborated and expanded on in the document leak, as King details in his post. 👀 But who has time to read through and dissect all that?
Fishkin and King, along with the rest of the SEO industry, will be mining this set of files for years to come. (Including local SEO expert Andrew Shotland.)
To start out, Fishkin focuses on five useful takeaways:
- NavBoost and the use of clicks, CTR, long vs. short clicks and user data.
- Use of Chrome browser clickstreams to power Google Search.
- Whitelists in travel, COVID-19 and politics.
- Employing quality rater feedback.
- Google uses click data to determine how to weight links in rankings.
Here’s what I found most interesting:
NavBoost is one of Google’s strongest ranking signals
Fishkin cites “Click Signals In NavBoost” in his article, which is where sharing proprietary information is helpful, a lot more of us now know we should be doing our homework on the NavBoost system. Thank you, Rand!

In case you weren’t aware, that’s coming from Google engineer Paul Haahr. One time, we were in the same conference room together. I feel like I got a tad smarter listening to him.
QRG feedback may be directly involved in Google’s search system
Seasoned SEOs know the QRG is a great source of tangible information for evaluating one’s own site against what Google is asking paid human beings to evaluate quality web results against. (It’s the OG SEO treasure map.)
What’s important about what we learned from this documentation is that quality raters’ feedback might play a direct role in Google’s search system, not just serve as surface-level training data.
This is another reason to carefully read and understand the documentation.
But seriously, high level it for me, Rand
Now, for the non-technical folks, Fishkin also provides an overview to marketers in a section titled “Big Picture Takeaways for Marketers who Care About Organic Search Traffic.” It’s great. It covers things that resonate, like:
- The importance of “building a notable, popular, well-recognized brand in your space, outside of Google search.”
Large, established and trusted brands are what Google likes to send traffic to, subsequently, in favor of smaller publishers. Who knows, maybe that landscape will shift with the latest August 2024 core update.
- He mentions that E-E-A-T (experience, expertise, authority, trust) exists, but there are no direct correlations in the documentation.
I don’t think that makes those aspects any less important because there are a fair bit of actionable steps a marketer can take to better reflect these quality/quantity signals.
Fishkin also points to his research on organic traffic distribution and his hypothesis that for most SMBs and small website publishers, SEO yields poor returns. “SEO is a big brand, popular domain’s game.”
The data doesn’t lie, but the broader context is in line with what former in-house enterprise SEO turned consultant Eli Schwartz says: SEO needs to have a product-market fit because, in my experience, it’s an awareness and acquisition channel, not one for demand creation.
Read Fishkin’s article if you’re a marketer looking to get a basic understanding of the shared documentation. King’s article is a lot lengthier and more nuanced for the more seasoned SEOs.
Mike King’s insights
For starters, I completely agree with King here:
“My advice to future Googlers speaking on these topics: Sometimes it’s better to simply say ‘we can’t talk about that.’ Your credibility matters and when leaks like this and testimony like the DOJ trial come out, it becomes impossible to trust your future statements.”
I realize Googlers don’t want to tip their hand by not saying something, but when leaks strategic sharing of information like this surface, people still draw their own conclusions.
It’s no secret that Google uses multiple ranking factors. This documentation pointed to 14,000 ranking features and more, to be exact. King notes this in his article:

King also cites a shared environment where “all the code is stored in one place, and any machine on the network can be a part of any of Google’s systems.”
Talk Matrix to me, Neo.
Truthfully, though, King’s thorough post is probably one of those forever-open Chrome tabs I’ll always have.
I did appreciate this high-level section titled “Key revelations that may impact how you do SEO.” This is what those of us skim readers came for.
King helps SEOs boil the ocean in this section by giving his main takeaways. My personal top takeaways from this section were this:
“The bottom line here is that you need to drive more successful clicks using a broader set of queries and earn more link diversity if you want to continue to rank. Conceptually, it makes sense because a very strong piece of content will do that. A focus on driving more qualified traffic to a better user experience will send signals to Google that your page deserves to rank.”
Then this:
“Google does explicitly store the author associated with a document as text.”
So, while E-E-A-T may be nebulous aspects of expertise and authority to score, they are still accounted for. That’s enough proof for me to continue advising for it and investing in it.
Lastly, this: (within the Demotions section)
“Anchor Mismatch – When the link does not match the target site it’s linking to, the link is demoted on the calculations. As I’ve said before, Google is looking for relevance on both sides of a link.”
Lightbulb moment. In the back of my head, I know the importance of anchor text. But it was good to be reminded of the specific way in which relevance is communicated.
Internal and external linking can seem like an innocuous technical SEO aspect, but they serve as a reminder of the care required when using links.
See, it is valuable to read other SEO veterans’ evaluations because you just might learn something new.
My top 5 takeaways for SEOs from the sharing of internal Google documents
You’ve heard from the best, now here are my recommendations to websites that want to benefit from sustainable, organic growth and revenue opportunities.
Always remember, online, your two primary “customers” of your website are:
- Search engine bots (i.e., Googlebot).
- Humans searching for solutions to their problems, challenges and needs.
Your website needs to be cognizant of both and focus on maintaining and improving these factors:
1. Discovery
Ensuring your site is crawlable by search engine bots so that it is in the online index.
2. Decipher
Make sure search engines and humans easily understand what each page on your site is about. Use appropriate headings and structure, relevant internal links etc.
Yes, I said each page because people can land on any page of your website from an online search. They don’t automatically start at the homepage.
3. User experience
UX matters, again, for bots and people.
This is a double-edged sword, meaning that the page needs to load quickly (think CWV) to be browsed and the overall user interface is designed to serve the human user’s needs, “What is their intent on that page?”
A good UX for a bot typically means the site is technically sound and receives clear signals.
4. Content
What are you known for? These are your keywords, the information you provide, the videos and the demonstrated experience and expertise (E-E-A-T) in your vertical.
5. Mobile-friendly
Let’s face it, Googlebot looks for the mobile version of your site first to crawl. “Mobilegeddon” has been a thing since 2015.
Why you should always test and learn
For example, the rankings of exact match domains continue to fluctuate constantly.
As someone with a background in local SEO search directories, I continue to evaluate whether exact-match domains improve or lose rankings because Google’s advancements in this area interest me.
“Exact Match Domains Demotion – In late 2012, Matt Cutts announced that exact match domains would not get as much value as they did historically. There is a specific feature for their demotion.”
Personally, in my research and observation working with small businesses for keywords with very, very specific and low (10 or less) search volume, I haven’t found this to be an absolute. I may have found an outlier. Ha, or an actual leak.
Here’s what I mean: every Saturday in May, a lot of people will want to be in Kentucky at Churchill Downs for the fastest two minutes in sports, the Kentucky Derby.
The rental homes and properties SERP is dominated by marketplace sites, from Airbnb to Kayak to VRBO and Realtor.com. But there’s one hanging on in this pack. In opposition 8, it’s an exact match domain.


Has it been demoted? Maybe.
It’s also, in its own way, an aggregator site, listing a handful of local rental properties.
So while it’s not a name brand aggregator site, it has hyper-local content and, therefore, may continue to weather the storm.
It could also be a core update away from being bounced onto page 2. Nothing to do but ride it until it bucks you.
Heck, the organic listing above it is ranking for the incorrect location “Derby, NY.”
So, is Google search perfectly ranking all query types? Neigh.
NavBoost highlights
For those who haven’t been paying close enough attention. Meet NavBoost.
The documentation mentioned NavBoost is a system that employs click-driven measures to boost, demote, or otherwise reinforce a ranking in Web Search.
Various sources have indicated that NavBoost is “already one of Google’s strongest ranking signals.”
The leaked shared documentation specifies “Navboost” by name 84 times, with five modules featuring Navboost in the title. That’s promising.
There is also evidence that they contemplate its scoring on the subdomain, root domain and URL level, which inherently indicates they treat different levels of a site differently.
It’s worth continuing to research and process Google’s patent and use of NavBoost.
Conclusion
It’s a gift to continue to have great minds in the SEO space like Fishkin and King, who can distill large amounts of documentation into actionable nuggets for us mortals.
None of us know how the data is used or weighted. But we now know a bit more about what’s collected and that it exists as part of the data set used for evaluation.
In my professional opinion, I’ve always taken statements from Google with a grain of salt because, in a way, I’m also intimately familiar with being a brand ambassador for a publicly traded company.
I don’t think any corporate representative is actively trying to be misleading. Sure, their responses can be cryptic at times, but they fundamentally can’t be explicit about any form of internal operating system because it’s core to the business’s success.
One reason why Google’s DOJ testimony is so compelling. But it can be difficult to comprehend. At the very least, Google’s own Search Central documentation is often more succinct.
The shared internal document is the best we’re going in terms of learning what’s actually included in Google’s “secret sauce.”
Because we’ll never fully know, my practical advice to practicing SEOs is to take this additional information we now have and to keep testing and learning from it.
After all, Google and all of its algorithms are, in parallel, doing the same along the path of being better than they were the day before.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.
Source link : Searchengineland.com